接上篇
模块
最早的时候,程序员们为了重用代码,会直接把代码 #include 到自己的项目中来,然后把库代码和应用代码一起编译出一个可执行应用。这个时间点,library 是通过源代码分发的。但是那个时候外部存储设备非常慢,而内存则非常贵并且容量很有限。没有办法把所有代码都放在内存中进行编译,这样编译器就需要多次从外部存储设备中读取源代码,然后多次访问巨慢的外部存储。可以预见,库的代码越多,可能会导致程序的编译过程就越慢,为了缩短编译时间,程序员们想出了可以把库和 application 分开编译的法子:
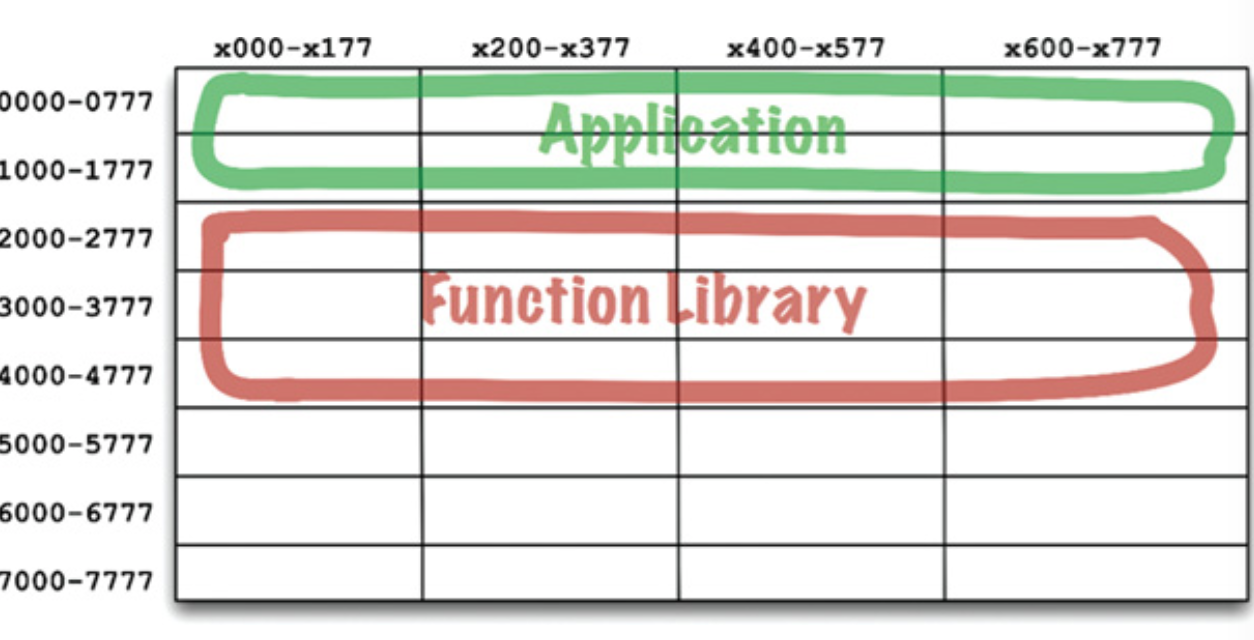
只要把 library 加载到固定的内存位置,例如 2000,那么我们就可以直接使用编译好的 library 了。
不过这种做法很快遇到了问题,程序自己要使用的内存很快就超过了 2000,这时候就非常地尴尬了。机智的工程师们还是想出了解决之道:
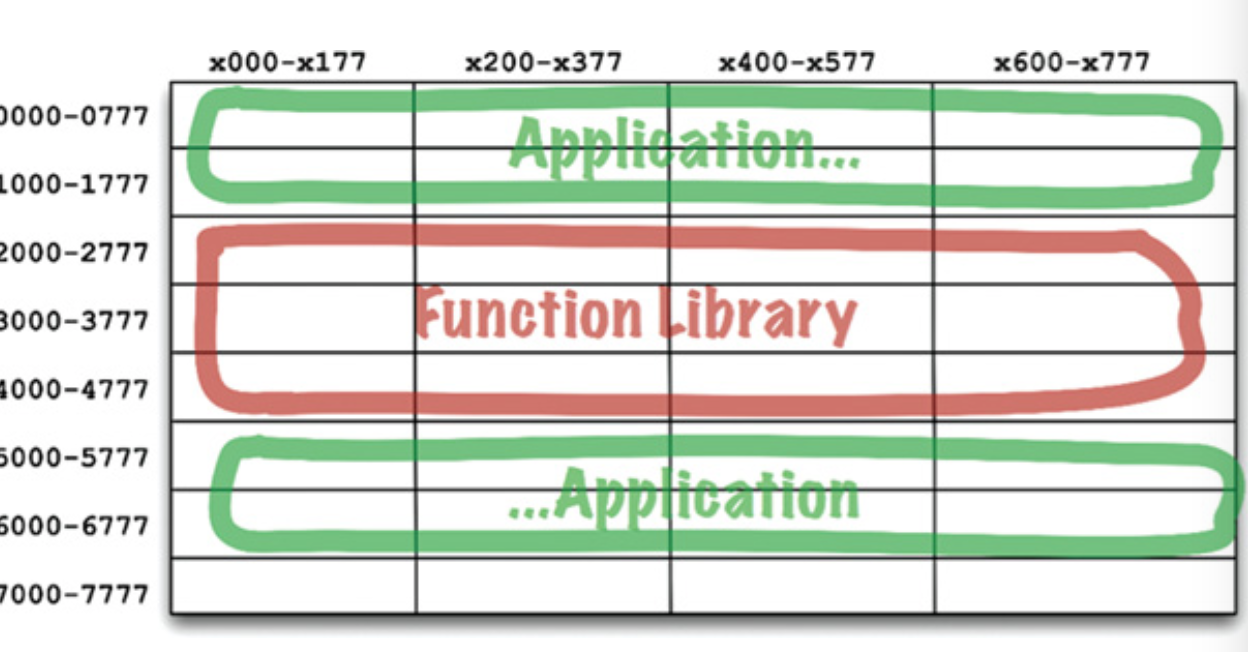
跨过 lib 的地址去寻址。。。这种做法显然是不可持续的。所以后来才慢慢有了“可重定位”的概念,才有了后来 linkers 的发展。这之后有了动态链接的概念,然后就是插件化的架构。现在常见的共享库可能是 DLL,也可能是 JAR。虽然有的语言依然是使用源码进行共享库的分发(PHP/Go)。
模块的内聚
模块是否内聚有三条可参考规则。
REP: The Reuse/Release Equivalence Principle
CCP: The Common Closure Printciple
CRP: The Common Reuse Principle
光看英文比较玄乎,REP 中比较重要的是下面这些观点:
1. 重用的粒度也就是版本发布的粒度,意思就是说,我们对一个外部 library 的重用,是要参考这个库的版本号的。在应用的单次叠代开发中,不应该随意切换依赖库的版本(除非是因为 bug)。
2. 第一条提到的版本号,我们需在自己的应用中对所有依赖进行版本号记录。这样才能够保证我们的应用使用的第三方库是彼此兼容的。如果出现问题,也可以根据记录去寻找到底是哪里出现了兼容问题。
3. 如果 library 发生了 breaking change,就是说 API 有修改,那么必须要发布新的 release 版本。同一模块内类、组件的修改应该被一起发布(废话),拥有共同的版本号。
4. 同模块内的类和组件应该是为了达成共同的目的而形成这样的内聚关系。模块不应该是随机选几个类就归到一块成为一个模块。
CCP 里比较核心的观点:
1. 把那些会在同样的时机和原因修改的代码聚合在同一个模块内,把那些不会在相同时机和原因修改的代码拆分到不同的模块中去。
2. 对于大多数的模块了说,可维护性都比可重用性要重要。如果必须发生改变,你肯定希望这些修改是发生在同一个模块中,而不是发布在一大堆模块中。这样同时也能减少因为修改模块太多而导致的部署方面的困难。
3. 如果两个类经常被绑定在一起,并经常一起被修改。那这两个类应该属于同一个模块。
CCP 和面向对象五大原则中的 OCP 和 SRP 有一些相近的思想,可以认为是面向对象思想在模块划分上的一种推广。
CRP 的一些核心观点:
1. 不要强迫用户依赖他们不需要的那些模块。
2. 只要发生依赖,哪怕是只要依赖了模块中的一个类,那么被依赖方发生变化,都需要依赖方进行依赖升级和重编译。所以引入更多依赖就意味着更多的麻烦。
3. 非紧耦合的应该放在另外的模块中。
CRP 和面向对象五大原则中的 ISP(接口分离原则) 非常类似。都要求你不要去依赖那些你不需要的东西。
然而上面的三条原则并不是能够和平相处的。REP 和 CCP 这样的原则都是包容性的原则,鼓励你往一个模块里尽量塞更多的东西。但 CRP 却是非包容性的原则,鼓励你把模块做得尽可能小。所以三者显然不能和平更存,来看图:
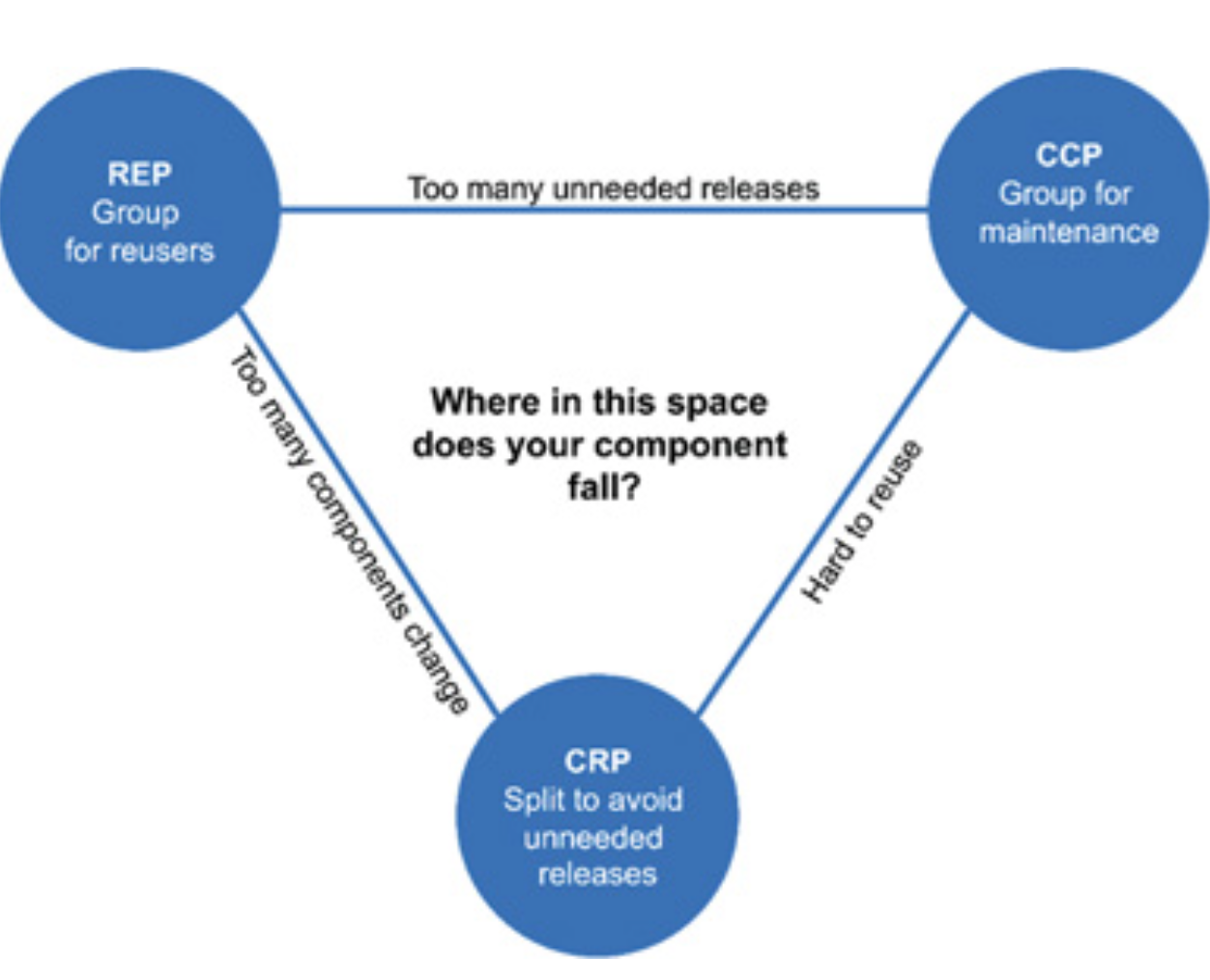
每一条原则对面的边上写了完全抛弃该原则时会导致的情况。可以根据该图来简单评估你的模块分布到了哪个位置。几条原则里主要矛盾的就是依赖(一变都变)的从属问题,没有什么银弹,结合自己的项目综合平衡就好。
模块的耦合
架构
架构的定义比较虚,主要是说软件的“形状”,这个形状包含:系统如何划分模块;模块之间的组织关系;模块间彼此如何通信。
为软件设计架构的目的是为了能够让软件的“形状”能最好地帮助软件生命周期内的开发、部署、运维和维护。
很多软件看似也可以工作,但实际上因为架构问题,会导致在部署、维护和运维方面困难重重。所以好的架构非常重要。
开发角度
软件架构同时也是一个公司的组织架构的反映。
如果一个公司人很少,可能就三四个人,那么他们的系统一定是从一个模块开始的。这也就是目前说的很多的单体模式。很多小团队的项目实际上就没有什么架构可言,因为一开始就没有任何架构方面的考虑。
如果一个公司一开始就被划成了五个组。那必然会要求你的软件架构能够使五个组在分开的情况下正常干活。系统至少也是分成了五个模块,彼此之间通过接口之类的稳定“契约”来沟通,否则的话也会寸步难行。
部署方面
系统的部署应该做到非常简单,如果一个系统的部署成本奇高无比,那说明这系统没救了。
可惜现在的软件开发阶段往往都不考虑部署问题,这样会让一个系统很容易开发,却难以部署。比如现在大行其道的微服务架构,如果尽信,则会给部署带来巨大的麻烦。创业公司不宜过早引入微服务架构。
如果在开发阶段就考虑后续的部署问题的话,那么可以选择:少量的服务数,进程内的模块划分和进程内通信。
运维
很多时候对系统的硬件进行升级都可以解决一些运维方面的问题。因为这年头机器要比工程师更便宜,但实际上运维对架构的可扩展能力有一定的要求。
不单是能升级硬件解决问题,最好是能够通过加机器来解决问题。也就是常说的 scale up 和 scale out。现阶段软件系统依然不能够做到完美的 scale out。大多数时候还是因为存储。
维护方面
按模块合理拆分系统,使变动尽量发生在同模块内。已经在一定程度上可以降低未来系统的变动风险。
因为最前面我们已经知道,对于软件系统来说,维护阶段要花的钱是最多的。所以可维护性是架构中要考虑的最多的方面。
clean architecture
业界目前已经有了一些架构方面的方案。不管是六边形架构、DCI、洋葱型架构、BCE 之类的,都会对架构进行分层,并且都在分层的基础上获得了下列优点:
不依赖任何框架。只把框架当作工具,而不是让框架入侵自己的业务,把自己的系统绑定到外部框架中。
具有良好的可测试性。业务逻辑可以在没有 UI、数据库、Web 服务器,或者其它外部元素的情况下进行测试。
不依赖于 UI。UI 层可以在不修改系统其它部分的前提下轻易替换掉。例如 Web UI 可以被 console UI 换掉,而不修改任何的 business rules。
不依赖于数据库软件。你可以轻易地把 db 从 Oracle 换成 SQL Server,换成 Mongo,BigTable,CouchDB,或者其它的任何东西。你的业务逻辑不应该绑定到数据库上。
不依赖任何外部的 agency。也就是说你的业务逻辑不应该知道任何外部世界的细节。
将所有的思想大概集成起来,就是 clean architecture 的思想了。如图:
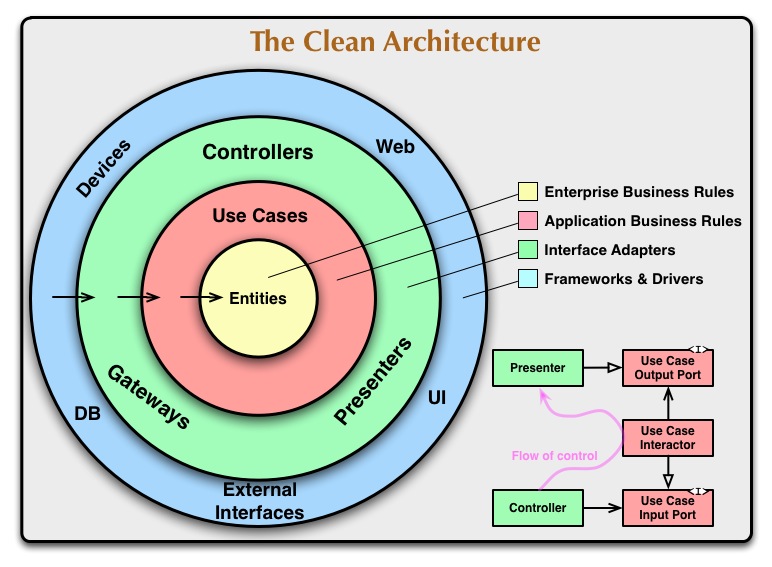
每一层具体的解释可以参考这里:
https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html
细节
数据库软件是细节
数据库在架构的角度只是 detail,还没有上升到架构中所包含的元素。所以数据库也不是业务相关的 entity。
这里说的是数据库本身,数据库软件。不指代 data model。从这个角度讲,database 是 utility 或者说 mechanism,提供访问数据的工具和手段。所以只能算 low level detail,好的架构不应该让 detail 污染系统的架构。
数据库软件把文件按照特殊的形式组织,例如 b+ 树,这样克服了树形文件系统不利于内容检索的缺点。基于内容组织数据可以使查询比全局搜索快的多,所以这么多年来关系型数据库非常的流行。
但换个角度思考的话,如果没有硬盘的话,我们怎么组织程序中的数据呢?那当然是多种多样的数据结构了,例如数组,链表,树,map 等等。
对我们来说,数据库软件的用途就是把文件系统里的内容映射到我们程序中的数据结构。所以数据库系统只能算是 detail。
有人可能会觉得我们日常工作和 db 打交道非常多,为了 db 方面的性能也是心力交瘁。性能方面的问题确实很重要,但这些是 low-level concern,在架构的角度来讲,依然是 detail。
web 是细节
关于一些计算任务是在浏览器端来做,还是在服务器端来做,这么多年来一直都在摇摆。
web 完全可以被当作一种 IO device,这样思考的话,就和六七十年代 unix 解决输出设备花样繁多的问题一样了。只要定义好接口,展示的事情随意。
所以 web 也是 detail。
框架是细节
同上面说的差不多,web 框架也不应该是架构的必须组成部分,尽管有一些框架从设计上会尝试对业务逻辑进行侵入。
从这些框架的作者角度来讲,他们把自己写的框架贡献给社区,也是希望能够帮助到更多的人方便开发。但是从业务的角度讲,这些框架的作者只知道他们自己在业务开发中所面临的问题,但他们不可能去了解你的业务场景和你遇到的问题。所以框架的作者为了解决他和他同事的问题,才产出了这些框架。而这些问题并不一定是你的问题。
尽管你的问题领域和框架作者的会有交叉,如果这些框架和你的问题一点交叉也没有的话,那也不会像现在这样流行了。
但对于框架的使用者来说,与框架绑定是一种“不对等的婚姻”。框架的作者往往会在文档里建议你将自己的业务和框架尽可能集成在一起。对于框架的作者来说,你把自己的架构绑定到他的框架上对他来说没有任何风险。而他自己的系统肯定会尽可能的耦合他的框架,因为作者对于自己的框架具有绝对的控制权。作者也希望你能耦合他的框架,贼船一上,那想离婚自然就难了。如果用户在开发中继承了框架里提供的各种基类,那说明对框架本身也是一种认可。
所以框架的作者就是想让你和他的框架结婚,而这种婚姻是单向的,一旦完成。那离婚的自由基本就不在你这里了。
对于你来说,这种婚姻关系显然是有风险的:
1. 框架本身的架构一般都不很 clean,而且倾向于破坏依赖规则。它们希望你把他们提供的类直接集成到你的 business rule 中,并且一旦你这么做了,以后想分离就非常难了。
2. 在你业务开发早期的时候,框架可能会提供一些特性帮助你的开发,但随着你的项目成熟,你可能会发现框架本身提供的功能不够用,并且可能在很多情况下反而障碍你的功能开发。这时候想离婚就难了。
3. 框架自己也会进化,但进化的方向不一定与你的预期相符。可能你用得很爽的功能在新版本中直接消失了,但新增加的功能你又完全不需要。
4. 有了更好的框架,你可能希望能够切换到新的框架上去。
解决方案是不要和这些 web 框架耦合,尽量让框架待在你架构的外圈,而不要侵入到核心的 business rules。如果框架推荐你继承它们的内部类,千万不要这么做。
在你的核心代码(business rule)中,不要集成任何和框架相关的内容。而这些框架的组件封装为 component,然后以插件的形式集成到你的系统中,遵循依赖原则。比如用 Spring 的时候,Spring 提供了 @Autowired 这样的依赖注入工具。你可以直接用 @Autowired,但不要让这种注入直接侵入到你的 business object。你的业务逻辑对象不应该知道有 Spring 这种框架存在。前面讲到的 main 模块中集成 Spring 是没啥问题的。因为 main 模块就是用来干脏活儿的。
在使用框架的时候,一定要让框架被圈在架构的边界后面。并且不要做需要牛奶的时候还得买头牛回来这种蠢事。
