流式计算系统是近些年发展较快的领域,虽然发展迅速,但实际上直到现在都没有能让所有人都满意的系统出现,哪怕是 flink/blink。
流式计算的理论基石是 leslie lamport 在 1985 年发表的论文《Distributed Snapshots: Determining Global States of a Distributed System》。首先将分布式系统中的进程定义为 process,然后将进程间的连接定义为 channel。当需要计算全局状态时,因为没有能够全局同步的时钟,所以需要有别的办法能够记录整个计算集群的状态值。
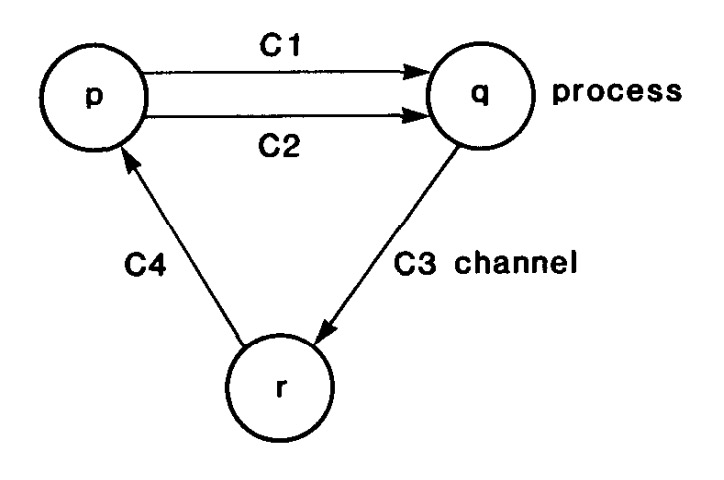
process 及连接 process 的 channel 共同组成一个计算的拓补图。因此这里说的全局状态,distributed snapshot,或者叫 global snapshot,其中不只包含各个 process 的状态,还需要包含连接 process 的 channel 的状态。如果只记录 process 的状态会导致那些正在 channel 中传输的信息丢失掉,这样所谓的全局状态是不完整的。而记录 channel 的状态也有讲究,比如我们可以由 channel 两端的 process 都记录其状态,但会导致全局的 event 数多发生计算。所以在 lamport 的论文中,把 channel 状态的记录任务分给了 channel 指向的 process 来做。即每个 process 负责记录自己的状态,以及指向自己的那些 channel 的状态。大概是下面这样:
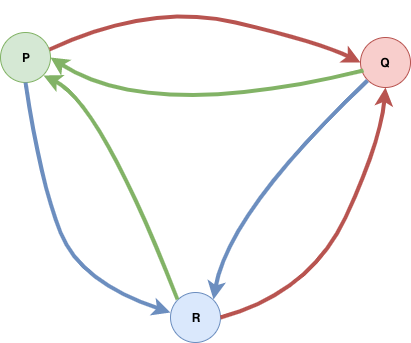
在这个模型中,每一个节点都有可能会触发 record global snapshot 的请求。这时候会由该节点记录其自身的状态,并发出一个特殊的 event,论文中称之为 marker。
所有收到 marker 的节点都需要做出一系列的判断和动作,直到 marker 从所有 channel 都经过了一遍之后,算法便得到终止。这时候可以通过采集所有节点的状态(其中记录了 channel 状态),拼起来就是整个系统的状态。
论文中对于 marker sending 和 receiving 流程的描述如下:

这几句话实在是读了很久都没读明白(汗),查阅了大量的解释说明之后,才终于搞明白了。。翻译版:
Marker 发送规则:
process p 先记录自己的状态,然后向所有从 p 指向其它节点的 channel 发送 marker。
在记录状态,发送 marker 这两个步骤中,不能发送任何后续的消息。
这里的发送规则,有两种情况:
- 一种是初始化节点,会记录自己的状态,然后向所有出 channel 发送 marker,这种比较简单
- 一种是非初始化节点,会在第一次收到 marker 时,向所有出 channel 发送 marker。但是如果在某些 channel 中又收到了相同的 marker 时,虽然会标记对应 channel 的状态,但不会再向出 channel 发送 marker 了,要不然没完没了。
Marker 接收规则:
当 process q 从 channel c 中接收到一个 marker 消息时:
if q 还没有记录过自己的状态
begin 那么马上记录状态
将接收到 marker 的 channel c 标记为 empty
end
else
q 开始 record 从 channel c 中来的所有消息,并将其记录为 channel c 的状态
算法的难懂之处主要还是在于描述,lamport 大佬写论文的时候显然没有考虑易读易理解性 orz。else 分支其实是说,如果 q 已经从 c0 中接收到了 marker,需要先将 c0 标记为 empty,然后开始 record 除了 c0 以外的其它 channel (c1,c2...cn)的状态,在没有从其它 channel 中收到 marker 之前,其它 channel 每一个 channel 都对应一个 fifo 队列,其队列中所包含的消息,就是这个 channel 的状态值。所以一个完整的快照是类似下面这种形式的:
p: state of p
q: state of q
r: state of r
cpq:
cpr: <e1, e2, e3>
cqr:
cqp:
crp: <e4, e5>
crq:
所有 process 的 state 和 channel 的 state 都记录到,才是完整的 global state。lamport 论文的状态记录法,能够使任意时刻得到的 global state 都保持一种一致性,这里的一致性,我个人思考的话,应该可以有两种解释:
- 如果是转账的场景,可以保证全局的金钱数额不变,即不多也不少。比如初始全局的总额为 rmb 100,没有外部输入的情况下,全局快照中求得的全局总额应该也为 rmb 100。
- 如果是发消息的场景,可以保证全局的消息与初始时的消息数目一致,不会发生消息重复,即特定的消息 ex,一定会被记录到某个节点或者某条 channel 的状态中,不会同时出现在多个地方。
lamport 的论文实际上就是在解决不重复记录的问题,并且对其进行了证明,对证明过程感兴趣的同学就自己去读论文吧。。
论文中对于算法所处的环境有一些假设,如:
- 系统中有 N 个进程
- 每两个进程之间有两条单向 channel
- channel 本身为 FIFO
- 系统中不会发生失败
- 所有消息完整地传输,不会在传输过程中发生失败
但显然这些假设对于实际的分布式系统来说是不现实的。所以后续的研究对某些假设进行了弱化。毕竟真实世界的分布式系统中,失败是不可避免的。
2015 年 flink 团队发表了一篇:《Lightweight Asynchronous Snapshots for Distributed Dataflows》,提出了比 lamport 高效简单的算法。
论文认为之前的算法需要对所有连接 process 的 channel 记录状态,需要记录大量的中间消息,从而导致 snapshot 大小膨胀。所以希望能够解决这个问题,提出更为 lightweight 的方案。
该论文首先将计算的模型分为了两类:即有向无环图,和有环图。分别针对两种情况设计了两套算法。无环图算法较为简单,有环图的算法是在无环图算法的基础上改进得到。先看看无环的情况:
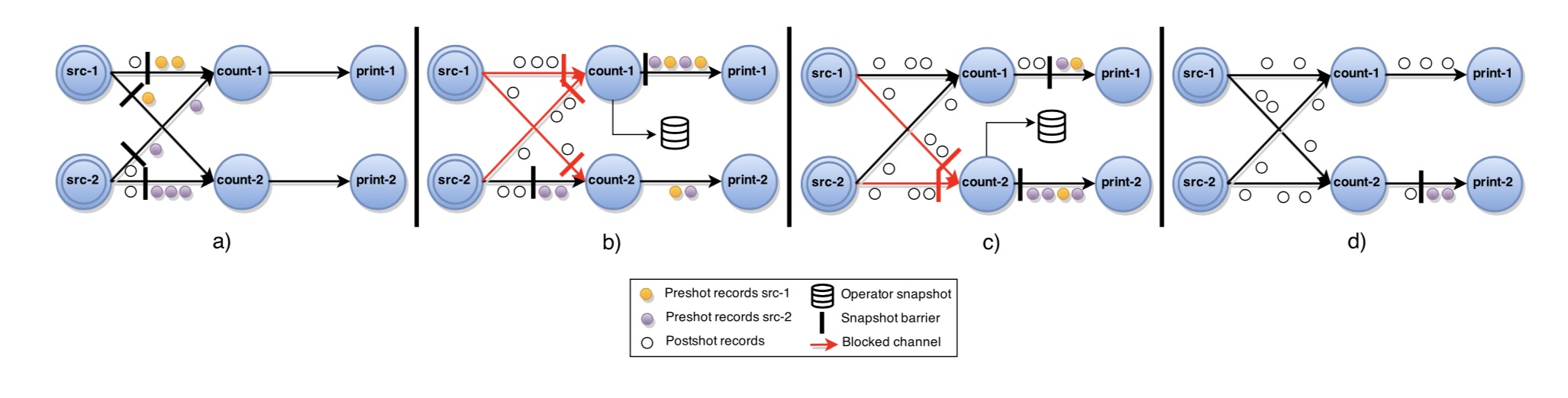
无环图中不需要对 channel 的 state 进行记录。flink 快照论文中提到了几个关键点:
- channel 可以认为相对可靠,遵循 FIFO 运输顺序,可以被 block 或 unblock。当 channel 被 block 时,所有消息都会被 buffer 住,并在执行 unblock 之前不进行传输。
- 任务能够在其 channel 上执行 block 和 unblock 操作,能向 output channel 发送消息。在所有 output channel 上可以执行消息广播操作。
- 消息会从 source 任务进行注入。从 source 节点来看的话,这些输入 channel 是特殊的 "Nil" channel。
中心 coordinator 周期性地将 stage barrier 注入到所有 source 节点。当 source 节点接收到一个 barrier 时,会对其自身的状态进行一次快照,然后向所有 output 广播 barrier (Fig.2(a))。当非 source 节点从指向它的某个 input channel 中收到了 barrier 时,会对该 input channel 执行 block 操作,阻塞一直持续到该节点从所有 input channel 均接收到了该 barrier(Fig.2(b)),然后该节点对当前状态记录一次快照并将 barrier 广播到所有的 output(Fig.2(c))。然后该节点对所有 input channel 执行 unblock 操作继续其计算过程(Fig.2(d))。完整的全局快照只包含各个 operator(可以理解为 flink 中的 process)的状态。
完整的算法伪代码:

还是比较好理解的。有环的过程会稍微复杂一些:
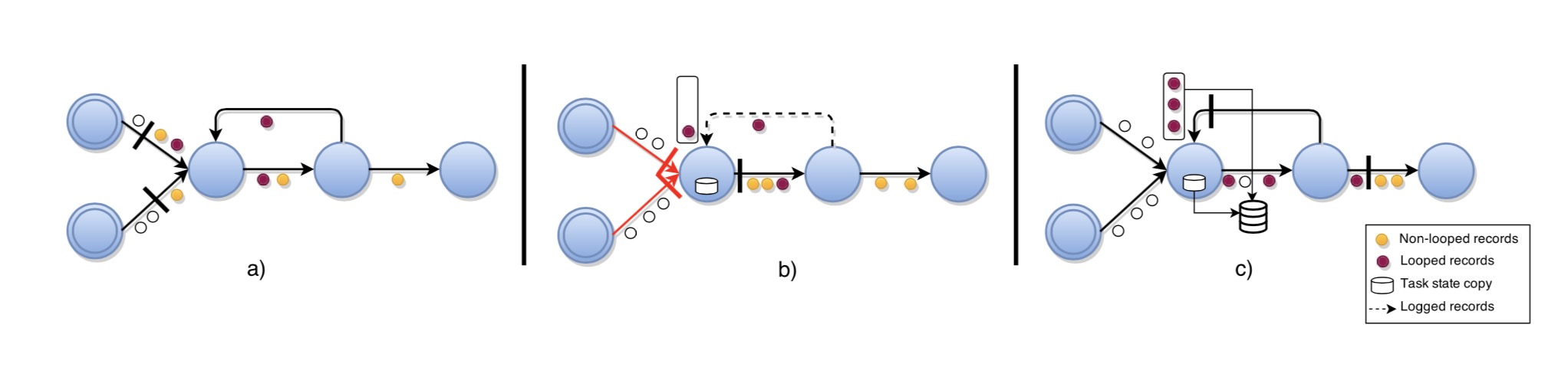
首先需要对用户的计算拓补图进行静态分析(static analysis),然后根据分析结果判断图上是否有环。有环图指向环起点的那条被被称为回边(back-edge)。干掉所有回边之后的图和之前的无环图处理方式基本一致。而回边指向的节点需要做一些特殊处理,具体细节为:
有回边的任务节点在将 barrier 向所有 output channel 广播出去之后,会先创建一个其本身状态的快照(Fig.3 (b))。然后,从这个时间点开始,需要开始 log 所有从回边发来的数据,直到从所有指向本节点的回边收到了 barrier。如 Fig. 3(c)所示,这样可以将该节点执行 snapshot 之前,已经进入循环过程的那些事件也记录下来。最终的快照包含所有节点的状态,以及所有回边上的状态(内容是收到 barrier 之前的数据)。
伪代码:

ps. 大致研究明白了分布式快照,才明白很多架构师嘴里的最终一致性就是放屁。
参考资料:
