《righting software》是 Pearson 出版社 2020 年出版的一本书,作者是 Juval Löwy,今年国内也引进了这本书,中文名是《架构之道》。
中秋期间读完了这本书里我比较关心的部分,本文将其中的一些核心观点进行摘录。
作者首先总结自己几十年的经验(先表达一下羡慕),提出了靠谱软件的设计方法,称为 The Method(中文译成了元方法):
The Method = System Design + Project Design
这本书也就被分成了这两部分,System Design 和 Project Design。
先说说 Project Design,这个其实就是项目规划,这部分大多数公司的项目管理培训中都有科普,就是通过对项目的工作任务进行拆分,绘制出网络图,找到迭代的关键路径,并为不同阶段分配不同的开发资源。看一下这张图你基本就懂了:
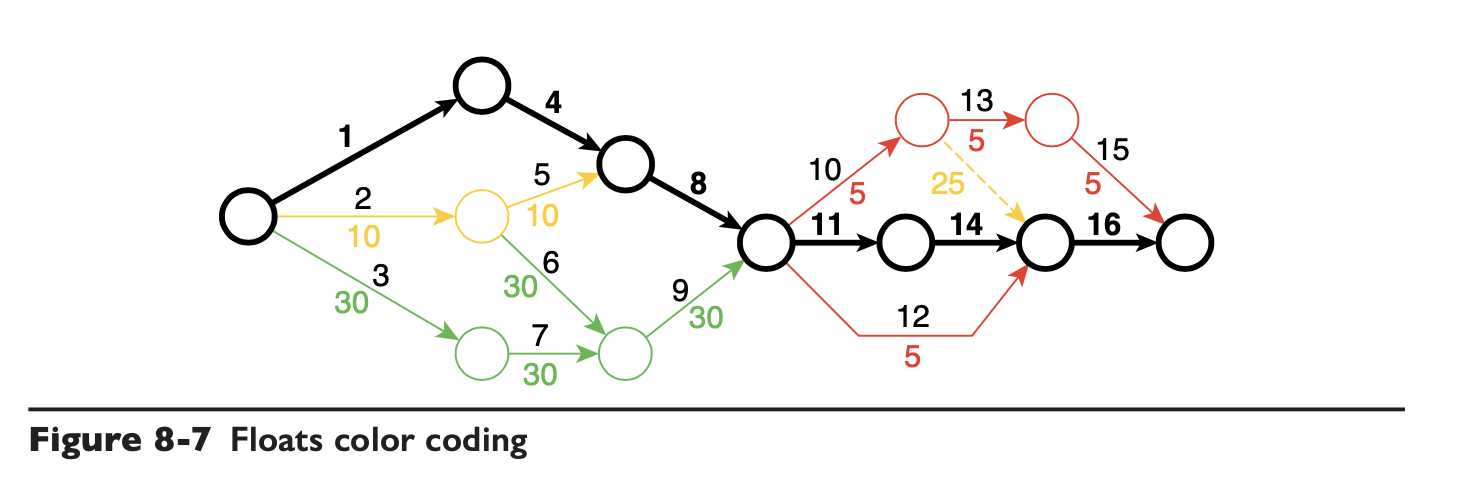
尽管作者把项目管理也放在了架构师的职责内,不过这些事情一般都是项目经理来干的(很多项目进了中后期,日常迭代其实都不需要做什么分析了,都是堆嘛),作者也没有提出让人眼前一亮的观点,本文会先忽略应该没什么人感兴趣的这个部分,大多公司的项目管理方式也比较粗放,循规蹈矩的做基于网络排期的公司很少很少。
System Design 对我们来说比较重要,一线软件开发和架构师每天的日常工作都会或多或少涉及一点设计。关于 System Design 的部分是这本书的上半部分,中文版总共 102 页,所以读起来也是比较快的。
微服务模式已经是后端架构模式的大前提,我们最耳熟能详的对微服务建模的观点一般是“基于功能”或“基于领域”拆分出来的微服务。实际的情况是,大多数一线工程师还在吵吵用不用 DDD,因为那几本 DDD 的书实在是写的太难读了。之后有机会我也写写 DDD 的科普文,应该没那么难的。
这本书就很神奇了,作者既不赞同基于功能进行拆分,也不赞同基于领域拆分。
为什么不赞同基于功能拆分?
这里给出了五个理由:
服务很难重用
比如拆分了三个服务 A、B、C,看起来是三个独立的服务,但在执行 B 的时候,其实需要 client 先去访问 A 拿到 B 所需要的参数。访问 C 需要先从 B 中拿一些参数。
这样 A、B、C 都不是独立的服务,他们是一组服务,你没法单独复用任何一个。
数量过度或规模过度
这个我们在大公司内见的比较多了,比如国内的几家规模比较大的公司,服务数量都超过 10 w 了,喜欢规模的人看到这些数字反而还会比较高兴。有些服务总共也就几千行代码,实现功能单一的简单逻辑。
还有那些没拆好的,单服务几十万行~100w 行代码的服务,本人也是实际见过的。
客户端臃肿耦合
服务数量爆炸会导致集成的难度变高,客户端的会随着服务数量的膨胀同步变复杂。作者这里没提到 BFF,不过 BFF 其实也没有降低集成复杂度,只是把这部分从 client 移到了 BFF 里。
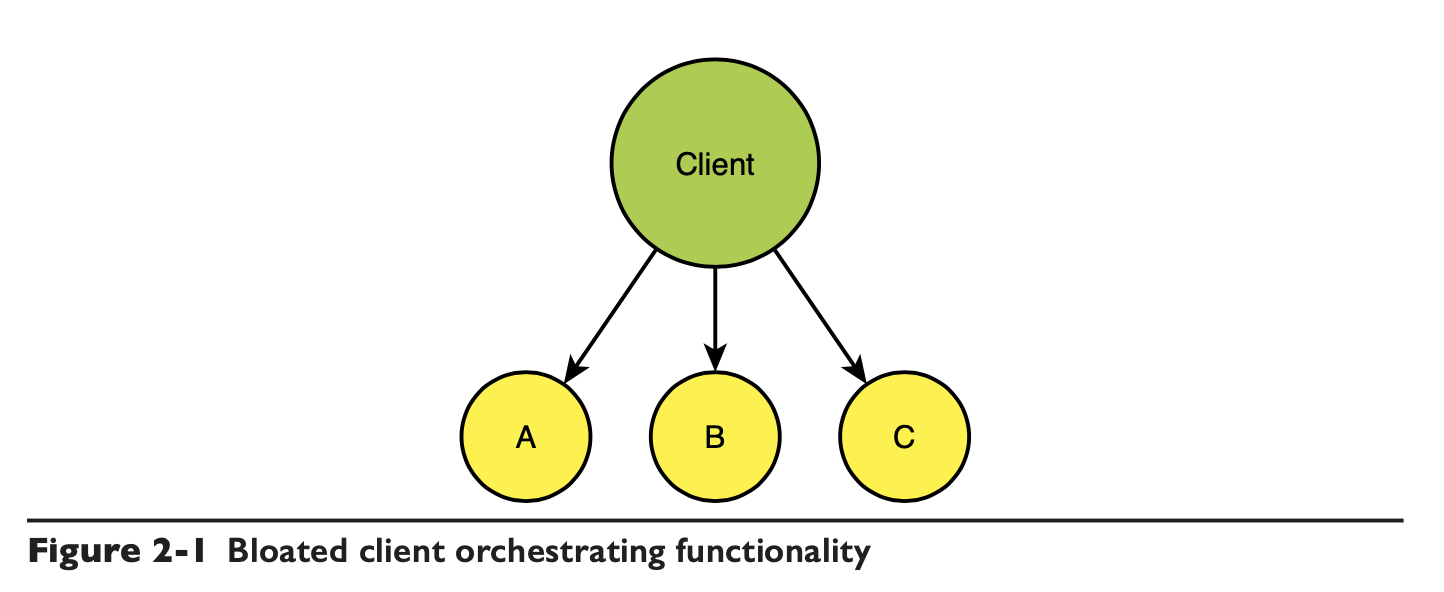
下面这张图是一个基于功能拆分的系统,在迭代一段时间后,客户端侧的圈复杂度的综合统计:
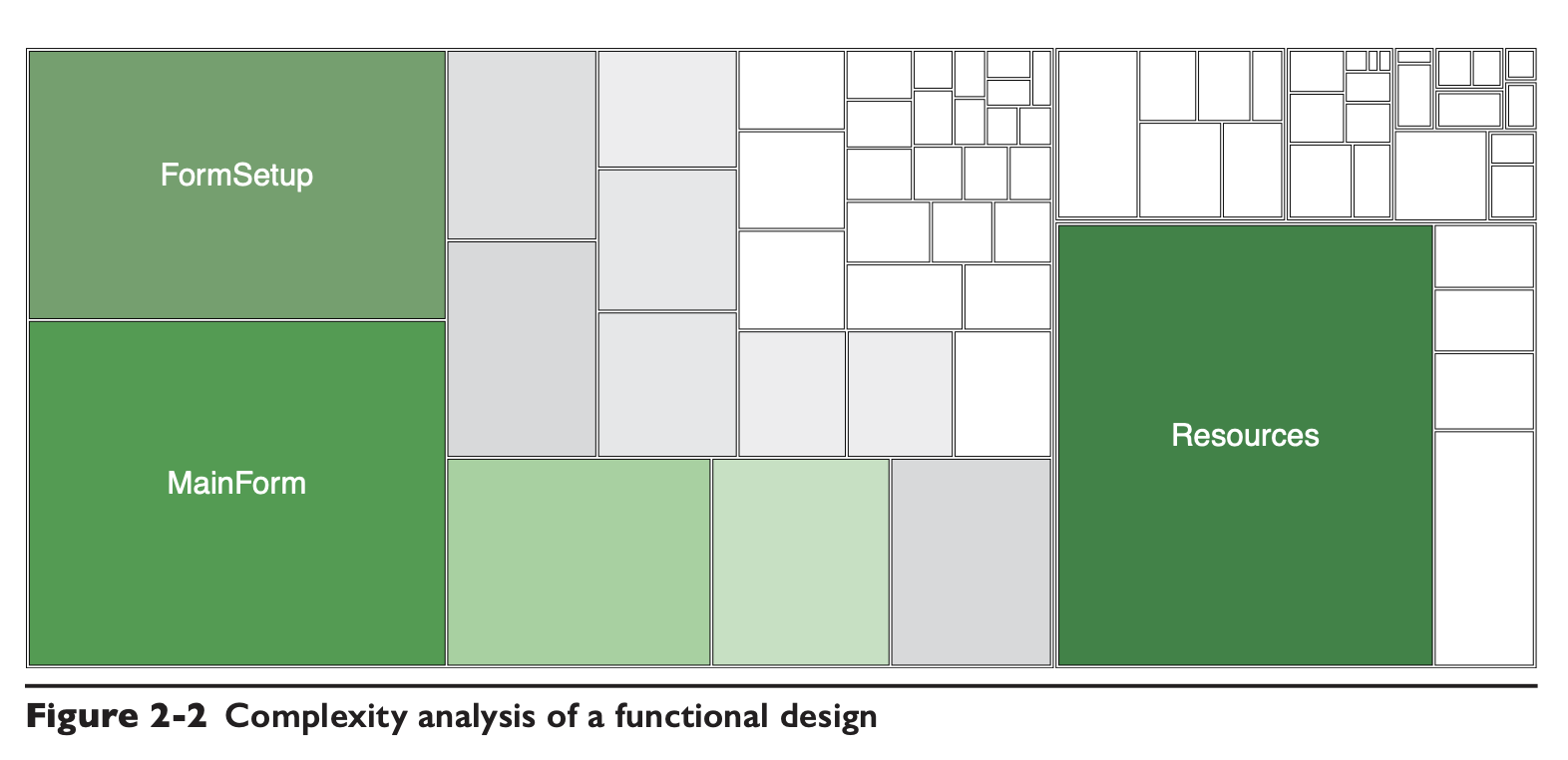
模块的复杂度分布极不均衡,组件极多,这里的 Resources 模块变得很大,就是因为后端服务数量太多造成的。
服务数量多导致的逻辑冗余
上面把很多服务都直接暴露给了客户端,导致每个服务都需要集成身份验证、授权、可伸缩、事务传播、等等等等。
这条其实有个 BFF 就还好了。
服务臃肿耦合
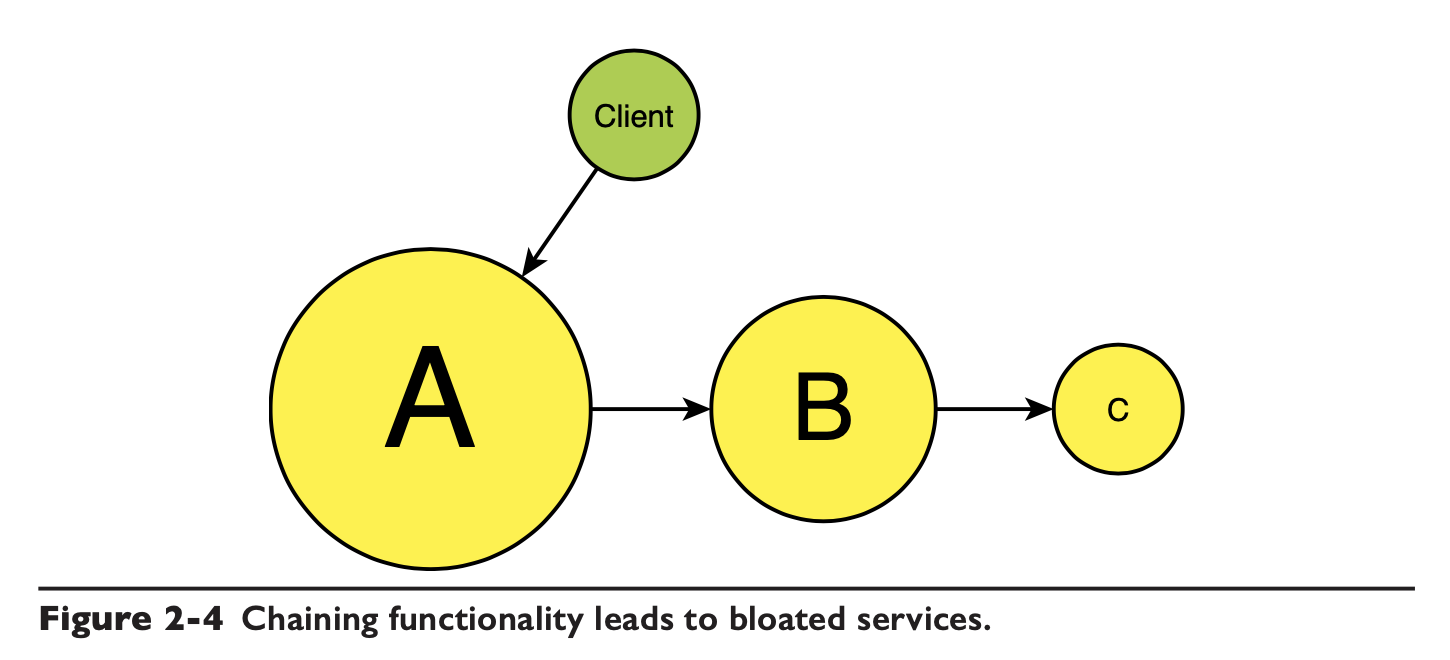
如果不想让 client 访问每个服务来实现业务,那可以让 client 只调用 A,但 A、B、C 自己要进行集成,比如这种链式的:
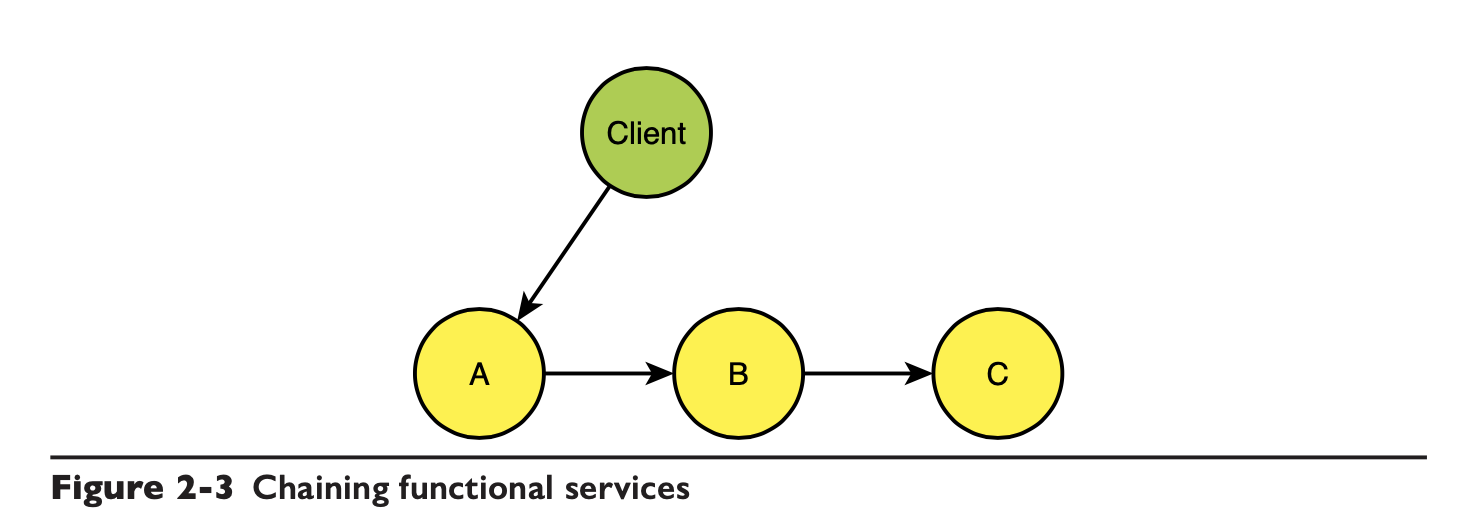
这样其实是让 A 完成了集成的角色,它需要准备后续服务需要的所有参数,集成的复杂度落在 A 上:
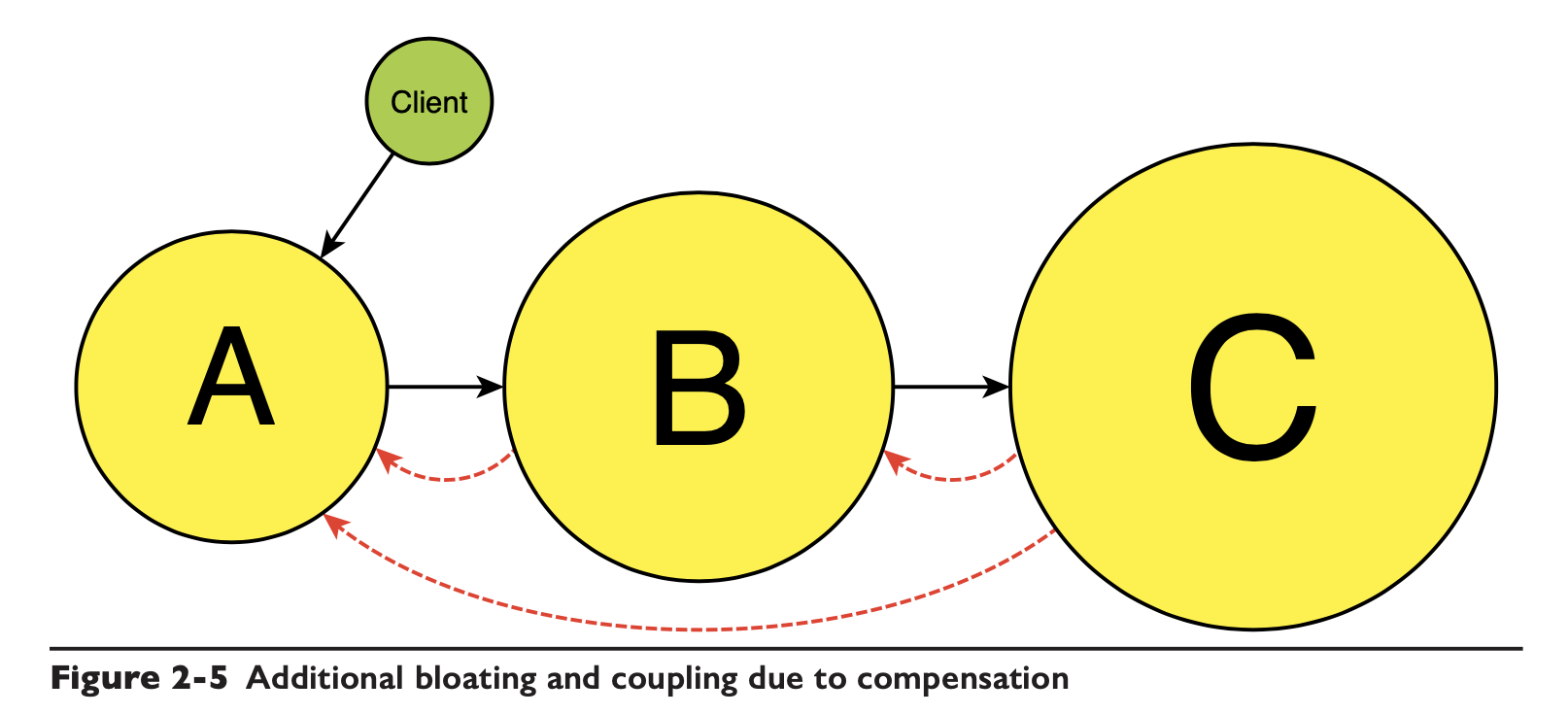
如果涉及到工作流、事务性质的业务,那可能 C 里还要关心 A、B 中的流程执行失败的时候,是不是要回调来进行逻辑补偿:
作者又举了一个真实生活的例子,如果我们要建造房子,是从房子的功能来考虑,那可能最后房子就变成这样了:
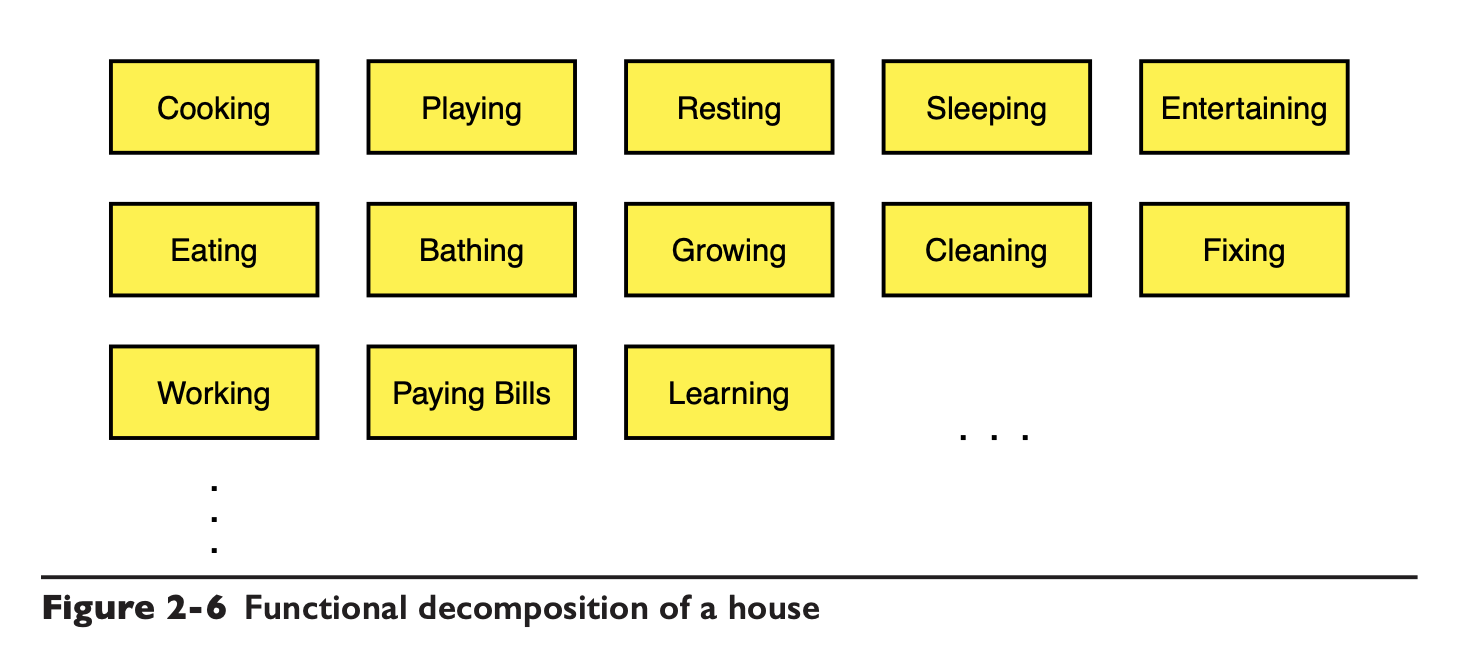
为每个功能需求建立一个模块,只要拿真实世界的房子设计和这里的图进行对比就知道这种设计是多荒谬了。
为什么不赞同用领域拆分?
还是那个房屋的例子,如果按照领域拆分,那么大概率会划分成下面这样的架构:

作者认为如果我们要在这样的建模下实现睡觉这个功能,那么就需要在每个领域里都实现一遍。(这里我其实觉得和软件领域类比稍微有点牵强)
领域本身无法独立运行,要交付必须完整交付,所以如果一开始就用领域建模,会导致一部分领域反复地被重建。比如你先把厨房做好了,在后面做其它模块的时候,发现排水管有问题,那厨房需要拆了重建。再后面又发现电器线路有问题,又需要拆了重建。这会产生很多资源浪费,且这种浪费是隐性的(这个倒是有道理,如果是比较大的项目,开发阶段某几个模块因为集成问题,反复地返工确实很常见)。
另外单元测试在领域中基本没什么用处,业务需求是不同领域共同作用的结果,即使某个领域的单元测试 100% pass,也不能保证业务逻辑能正常运行。(又一个和常规理念不太一样的观点)
基于易变性(volatility)的分解
1972 年 David Parnas 发表的 6 页论文 criteria for modularization 已经包含了现代软件工程的大部分元素,包括封装、信息隐藏、内聚、模块和松耦合。这篇文章指出,寻找变化点是分解的关键标准,功能本身不是分解的关键标准。
这也是《righting software》这本书的核心观点,基于易变性(volatility)的分解。这里也有一个反直觉的观点:我们的架构不应该按照需求来设计,因为需求一般都是对功能的需求,按部就班只能产生“根据功能分解”的系统。
考虑易变性,主要是从两方面考虑:
- 同一个客户的需求,随着时间迁移的不断变化
- 不同客户的需求,在同一时刻中的不同之处
书里管这两方面叫两个独立的轴,不过我个人觉得说成是时间、空间的影响可能更为恰当一些~
比如下面这个是同一房屋随着时间变化,可能会产生变化的一些要素,

家具变旧了要换掉,电器老了要换,后续卖给别人的话业主要换,哪天业主不开心了可能想刷个墙外观会变,以此类推。
下面是同一时刻不同的房屋之间可能存在的差别:

如房屋结构的易变性,不同房屋的邻居肯定也是不同的,不同的房屋也可能会处在不同的城市。
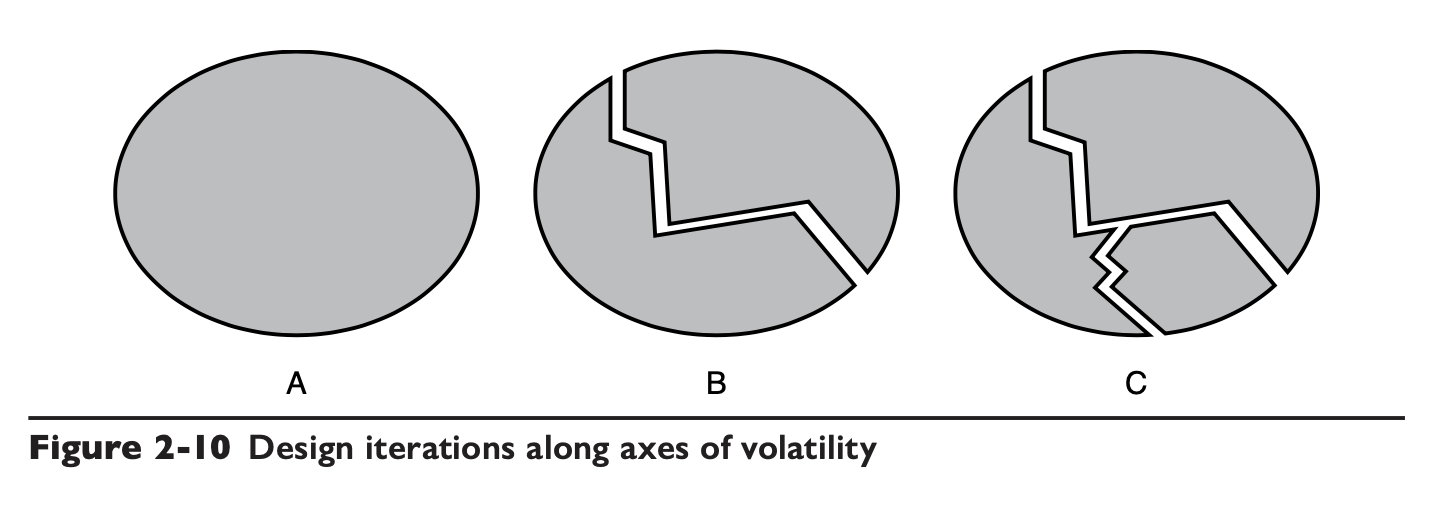
任何一种易变性都是可以被分类到第一方面(时间)或者第二方面(空间)的,我们根据这两个方面(或者叫轴)来对项目进行分析,一开始项目是单一的一块结构,我们沿着第一条轴询问自己,随着时间推移的某种易变性是否被封装好了?如果没有,那么就将该易变性封装进模块 B;然后可能接着问自己,同一时刻,是否所有用户都能使用相同的 B?如果不能,那么就需要继续封装这种差异性,形成 A、B、C:
在接到需求列表的时候,还应该注意有些需求描述的不是需求,而是解决方案,比如烹饪不是需求,吃饭才是需求,烹饪只是个解决方案,在做易变性分析的时候要把这些解决方案进行转换,要找到根源的需求,才能分析出可变性来,比如烹饪会被封装进进食的组件中,该组件负责处理进食的各种可变性(你也可以不自己做饭,点外卖嘛)。
项目设计阶段,应该把所有项目未来的易变性都列出来,比如一套交易系统,它的易变性包括:
- 用户易变性
- 客户端程序易变性
- 安全易变性
- 通知易变性
- 存储易变性
- 连接和同步易变性
- 持续时间和设备易变性
- 交易项易变性
- 工作流程易变性
- 地区和法规易变性
- 市场信息源易变性
关于每种易变性的说明大家去读原书就可以了,有了易变性之后,再根据这些易变性来设计系统,要保证每种易变性都尽量被封装到某一个模块里,比如书里给出的结构:
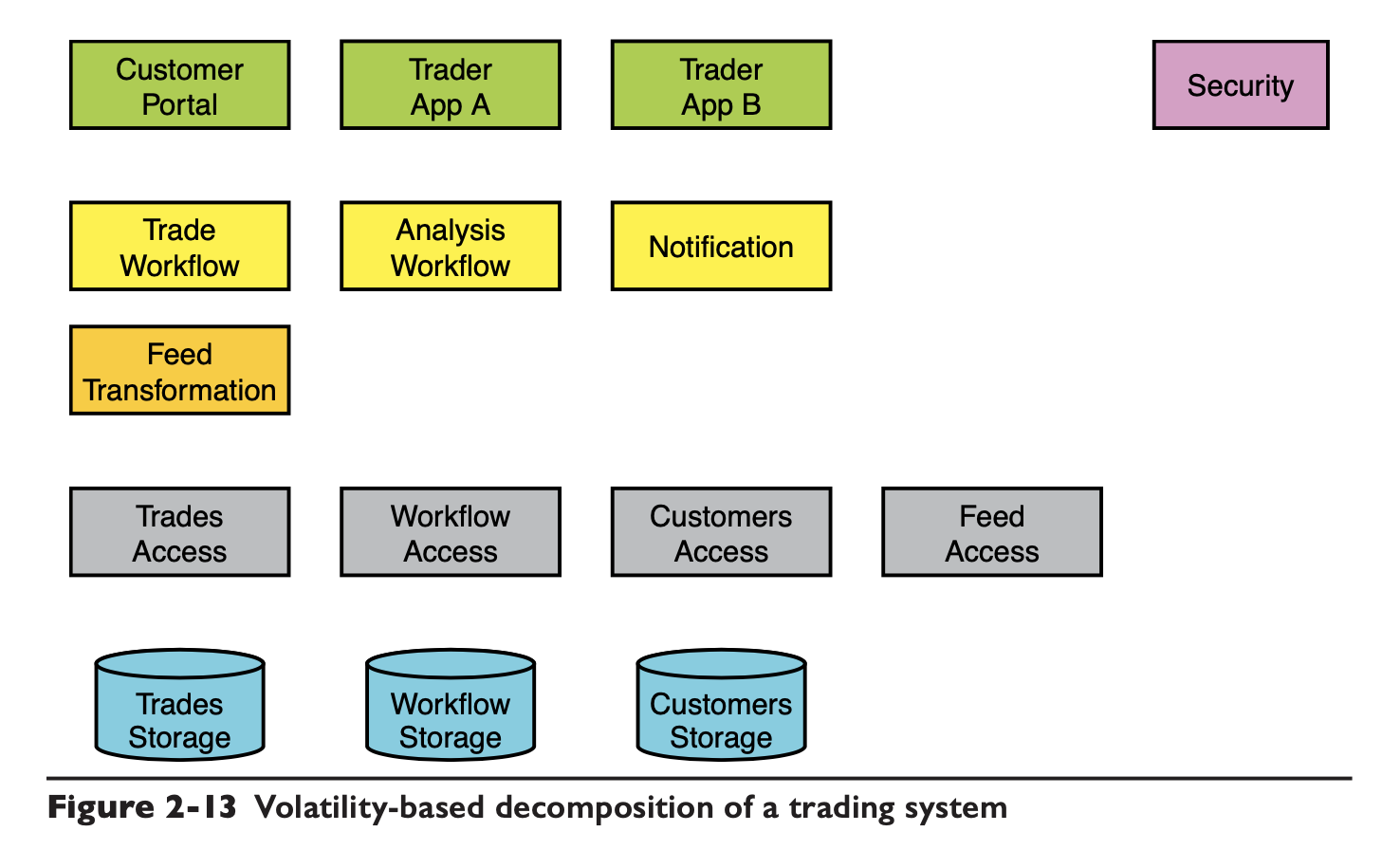
在设计架构的时候,要注意业务本身的性质是不应该被封装的,比如你们搞的是打车的业务,你还想在相同的架构下去做一套微博,这种不太可能,在老架构上迭代成本可能比新做一套都高。书里也给了两个判断标准:
- 如果某种变化是极其罕见,发生概率很低,那么不一定非得封装它
- 如果封装变更的尝试需要巨大的经济成本(就是说你设计个系统要花公司极多的钱),那么也不应该封装它
稍微具体一些
前面给的那个示例结构就是这本书里给出来的很典型的分层了:
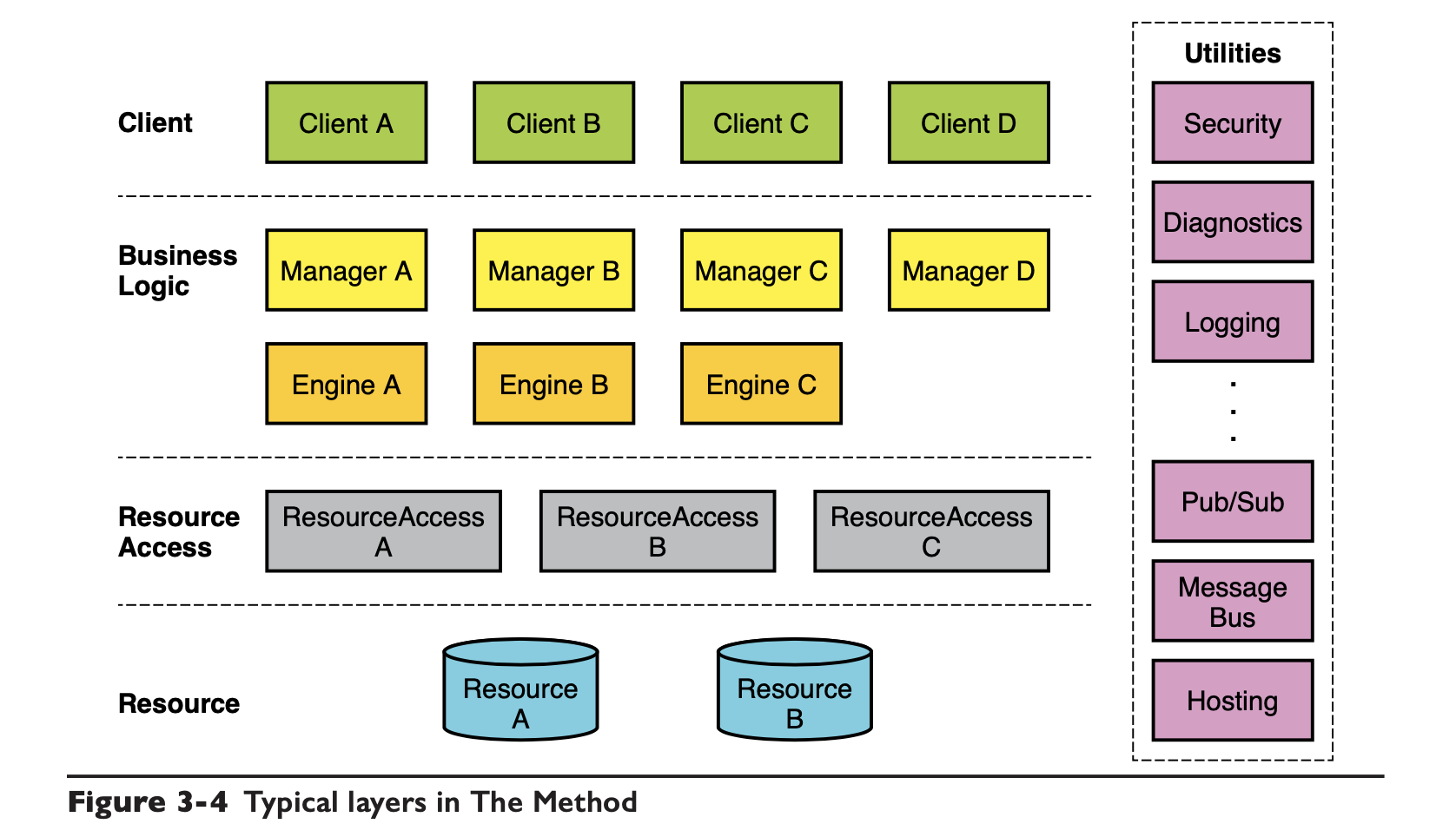
client 就不用说了,业务逻辑这层分成 Manager 和 Engine 层,Manager 负责管理流程类的易变性,Engine 负责某个活动节点本身的易变性。
流程易变性好理解,就是工作流嘛(这本书的作者应该和早期的 WCF 有渊源):
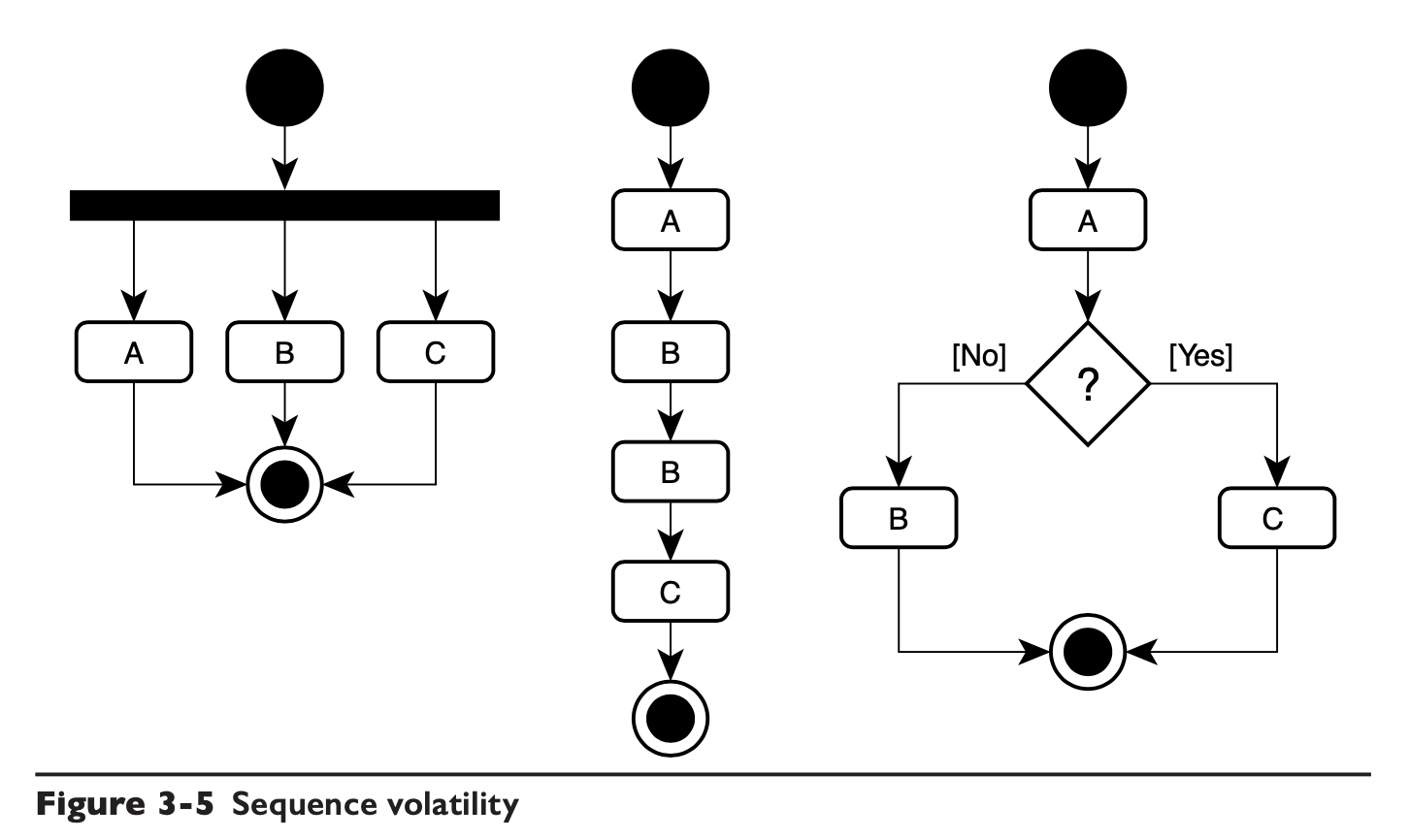
下面的两个流程是完全相同的,只是在第二步使用的活动不一样,如果 B 和 D 干的是同一件事情,那么 B 和 D 应该被封装进同一个 Engine 中。
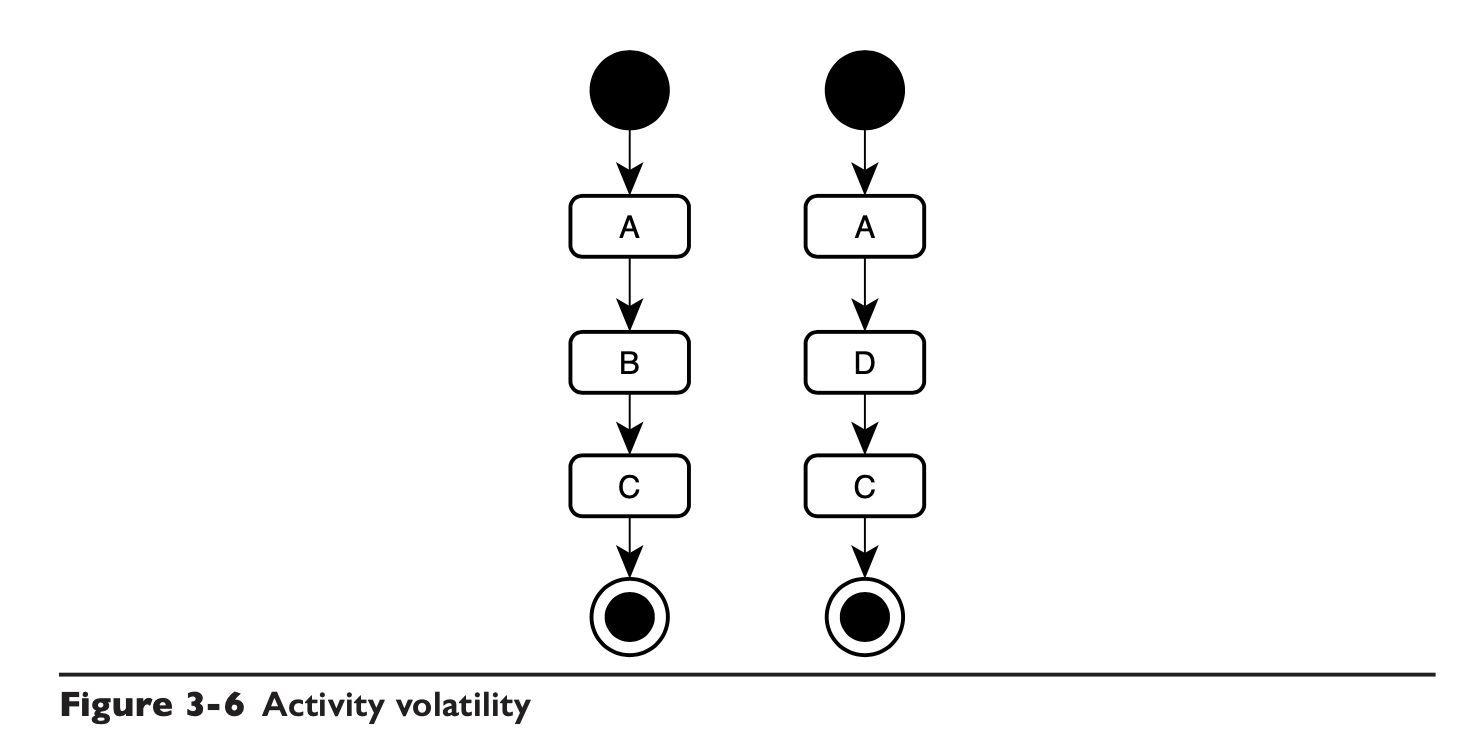
当然,如果 B 和 D 功能不一样,那这两个流程就不一样了,另论。
Resource Access 这一层是资源访问层,负责一些存储资源的封装,也就是说公司内的基础设施要变化的时候,不应该影响到上层的业务,这种在 DDD 社区也有 Repo Pattern 之类的,比较好理解。
Utilities 那些紫色的组件,一般是一些大家公用的非功能性 SDK,也比较好理解。
架构图里的模块大多是服务:
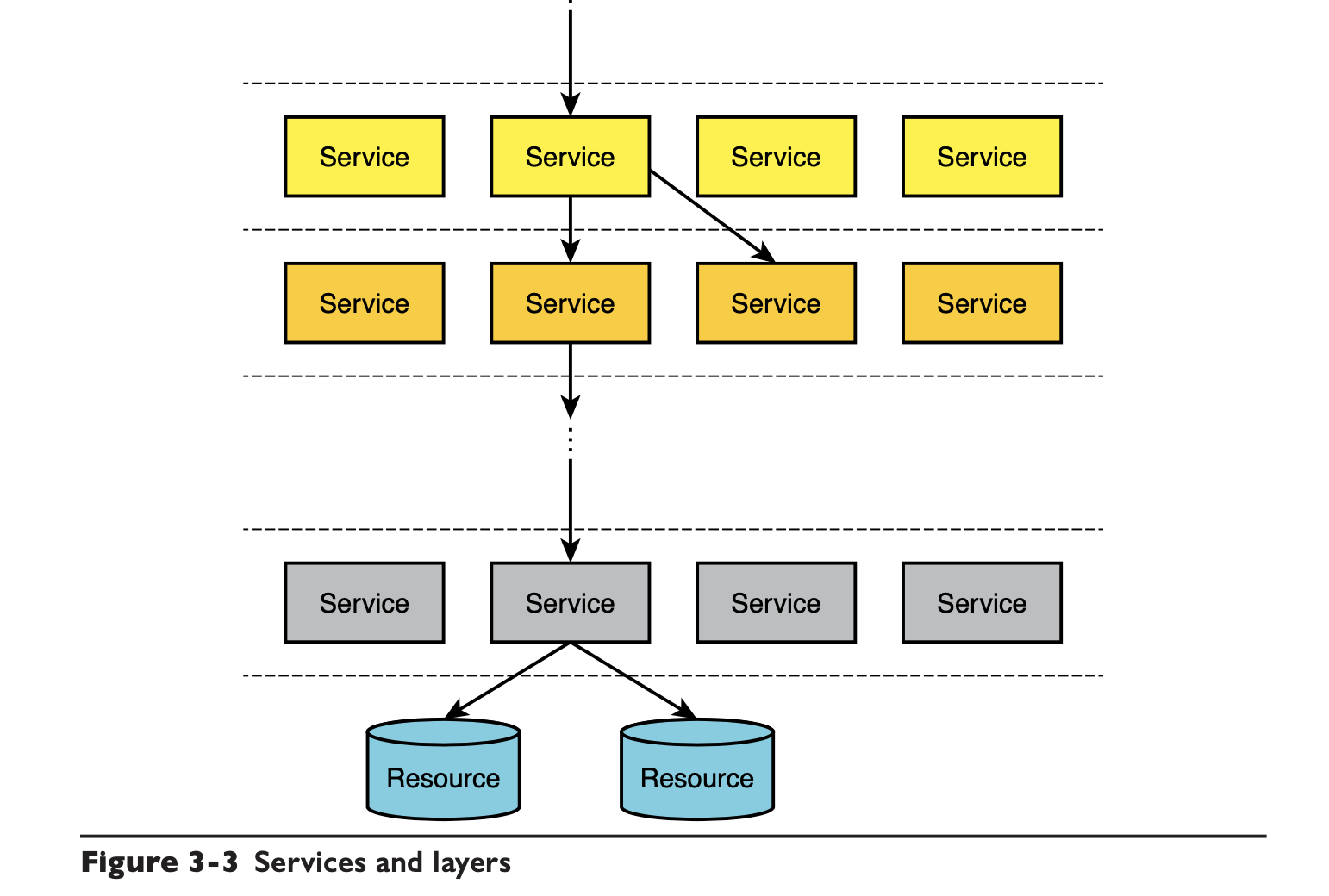
这样的分层每一次都是在解决 Who、What、How、Where 这四个问题:
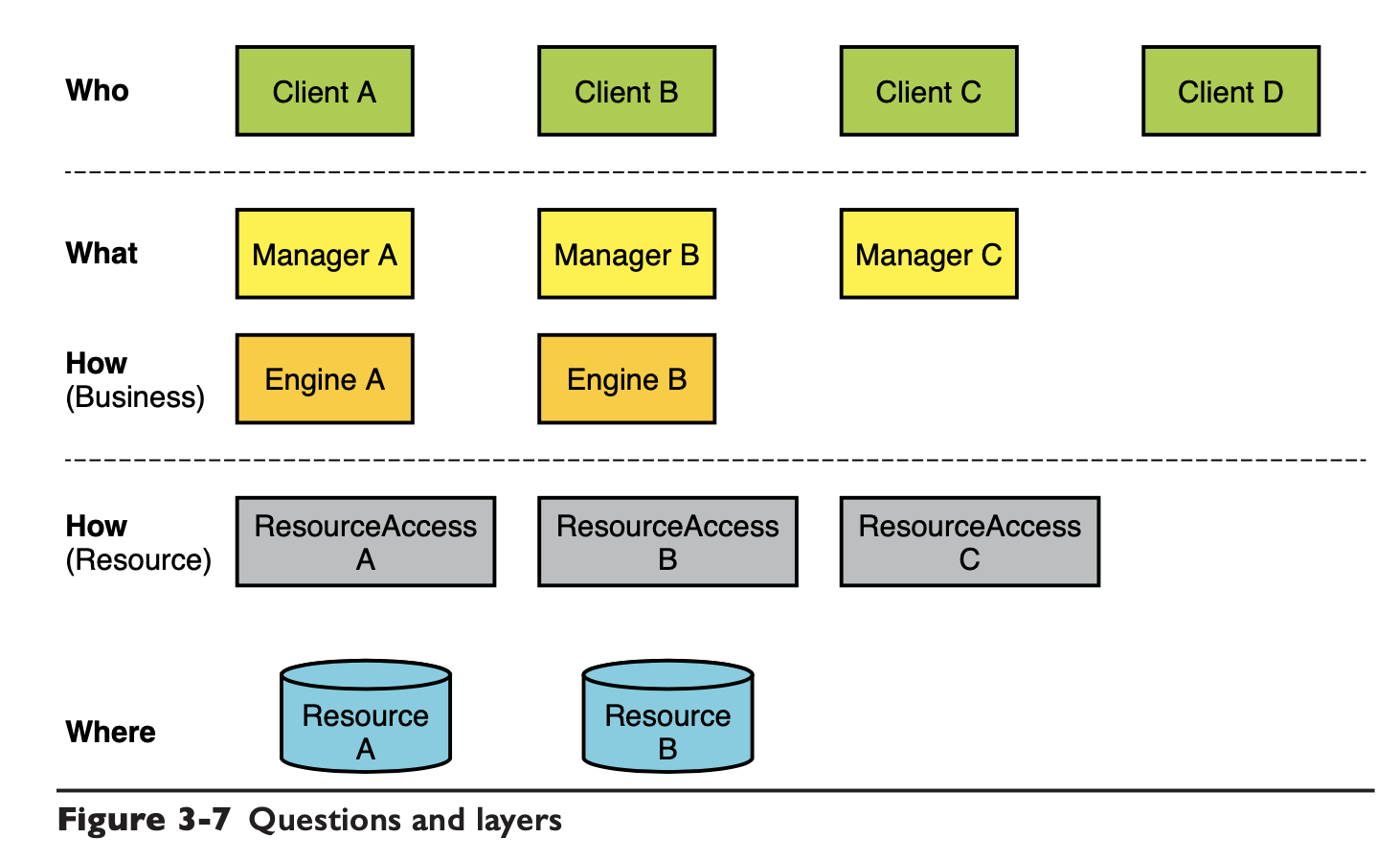
从上往下,易变性是逐渐降低的,我们可以想想,公司里最常修改的都是上面的一些业务逻辑,底层的基础设施几年变一次就不错了。
自上而下的重用性是逐渐增加的,Manager 经常做变更、重构、完全重写,都是挺正常的。
作者在这里又狠狠批判了一把按功能分解微服务,导致没有获得模块化任何好处的前提下,却要解决功能分解和面向服务的复杂性问题。这种双重打击超出了很多企业能承受的范畴。作者表示担心微服务将是软件史上最大的失败(嘿嘿)。
开放架构与封闭架构
开放架构
任何组件都可以调用任何其它组件,而不必考虑组件所在的层。可以向上向下调用。
开发架构有很大的灵活性,不过显然会导致层与层之间互相耦合,层内的横向调用也会导致层内的相互耦合,这样的项目是没法维护的。
作者认为产生横向调用是因为架构按照功能分解的恶果之一。
封闭架构
封闭架构禁止层内的横向调用,并且禁止下层调用上层系统。这样才能发挥分层的优势,将层与层之间解耦。封闭架构只允许一层的组件调用相邻较低层中的组件。下层的组件封装更下层的逻辑。
半封闭半开发架构
基础设施的关键部分,有时互相调用是难以避免的。因为基础设施要考虑性能问题,必须要进行最大优化,而有时向下转换会导致性能问题。
还有基本不怎么变的系统,耦合就耦合了,你管它呢。作者这里举了一个例子,网络栈就是基本不怎么变化的代码。
但大多系统不需要半开半闭,只要封闭就可以了。
放宽一点封闭架构的规则
因为封闭架构的要求太苛刻,实际开发中确实会遇到问题,在下面这些情况下也可以酌情放宽:
- 调用 utilities
- 按业务逻辑访问资源访问,即 manager 层直接调用 resource access 层
- manager 组件调用不太相邻的引擎
- manager 组件到其它 manager 组件通过 MQ 来通信,这种情况 manager 组件不需要知道其它组件,只要发 message 就可以了
设计禁忌
下面这些行为都是不能允许的:
- client 不应该在一个用例中调用多个 manager
- client 不应该直接调用 engine
- 同一个用例中,manager 不应该将等待多个 manager 的返回结果,这种情况下应该用 pub/sub 模型
- 引擎不应该订阅消息队列
- resource access 层不应该订阅消息队列
- client 不应该向消息队列发布消息
- 引擎不应该发布消息
- resource access 不应该发布消息
- resource 也不应该发布消息
- engine 不应该相互调用
- manager 之间不应该相互调用
可组合架构与架构验证
这里又提出了反直觉的观点,一定不要根据需求设计,而是要根据易变性来设计。
设计系统时,要从需求列表中找到核心需求,在设计完成之后,先用核心用例进行架构验证。举个例子,书里说的 Trade 系统,核心用例就是交易撮合。
增加新的需求时,应该不太需要变更架构,这才说明这套架构设计对了。
系统中的功能是集成的结果,而不是实现的结果。(有点抽象,想看明白的这里还是读读书好了)。
案例
系统设计的最后一部分,给出了前面说的 Trade 系统的相对完整的几个核心用例在按照易变性设计上的验证过程。
先是按照前面的四个问题的分析框架,把相关的概念进行罗列:
Who
- 技工
- 承包商
- TradeMe 客户代表
- 教育中心
- 后台程序 (i.e., scheduler for payment)
• What
- 技工和承包商会员资质
- 建筑项目 marketplace
- 教育证书和培训
• How
- 搜索
- 合规
- 访问资源
• Where
- 本地数据库
- 云端
- 其它系统
然后对易变性进行分析,并列出易变性列表:
- 客户端应用程序
- 管理会员
- 费用
- 项目
- 争议处理
- 匹配和批准
- 教育
- 法规
- 报告
- 本地化
- 资源
- 资源访问
- 部署模型
- 认证和授权
此外还有两个比较弱的易变性:
- 通知
- 数据分析
将易变性进行合理映射后,设计出的静态架构如下:
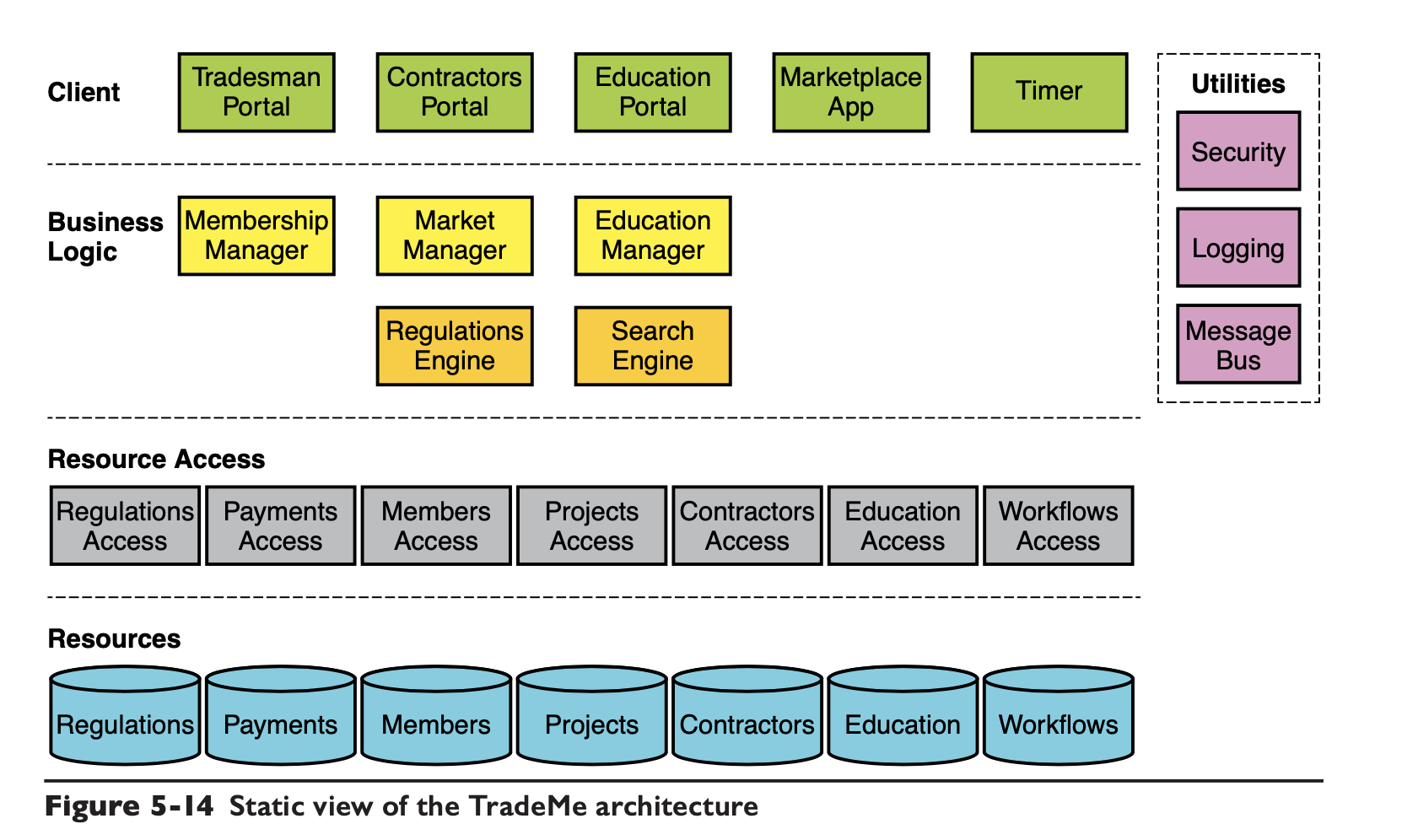
然后从需求中找出核心用例,分别是:
- 添加技工/承包商用例
- 请求技工用例
- 匹配技工用例
- 分配技工用例
- 终止技工用例
- 支付技工用例
通过泳道图,能够将核心用例一一进行验证即可。
总结
《righting software》这本书给了我们一种全新的设计系统架构的思路,只看作者的描述是比之前的功能分解和 DDD 要靠谱一些,但考虑到现在国内的互联网公司连用不要用 DDD 都要吵吵半天的实际情况,基于可变性的设计方法被众人所接受可能比较难。
作者没有像 DDD 社区那样拉一堆大佬上贼船站台,尽管也是几十年的从业经验,但相比 DDD 社区那些能嚷嚷的大佬,这套方法论应该还不是特别广为人知,相关的实践案例应该是比较少的。书里只给出了一个案例,后半部分都在讲项目管理了,稍微有点遗憾。
在阅读过程中,我也结合了之前公司内的开发经历不断地思考,能看出作者的理论在没有政治影响的情况下,应该是能自洽的。
不过这套理论有一个比较关键的问题,架构师在易变性分析的过程中,还是存在遗漏可变性的可能性的。这在我之前见过的无数项目中都发生过,架构师前脚走,后面一线的工程师就在吐槽架构师能力不行,设计出来的东西满足不了新需求。
如果是做创新业务,可能无时无刻不在做一些巅覆性的东西,想通过分析来做出稳定的架构还是挺难的。
上面的先不提,新观点还是值得学习的。
