大多数编译型的语言都逃不开词法分析,语法分析(语义分析)、编译链接几个阶段。学生时代如果学习过编译原理,啃过龙书,接触过 lex 或者 yacc 的话,一定还对当初要求一周做出一个编译器这种任性大作业的噩梦记忆犹新。编译原理这个领域本身有一定的门槛,随便给你一段程序,你也不太好说就能很快地给出一个可用的词法分析器语法分析器(里面还有相当的体力活成分)。
幸运的是,我们抱到了亲爹 google 的大粗腿。在 golang 里官方已经提供了一套非常友好的词法分析和语法分析工具链。可以很方便地帮助你得到你想要的语法分析的结果:ast。有了 ast 我们就可以上天了(笑。正经点说,是我们可以基于 ast 做很多静态分析、自动化和代码生成的事情。
这篇文章会简单介绍 golang 的 ast,并在此基础上教会你完成一个从 request struct 生成 api 项目中的 controller 层的主要代码所需要的手段。
从一个简单的例子开始,
package main
import (
"fmt"
"go/parser"
)
func main() {
expr, _ := parser.ParseExpr("a * -1")
fmt.Printf("%#v\n", expr)
}
这个例子会输出:
&ast.BinaryExpr{X:(*ast.Ident)(0xc42000a3e0), OpPos:3, Op:14, Y:(*ast.UnaryExpr)(0xc42000a420)}
什么鬼啊,赶紧看看官方文档:
type BinaryExpr
A BinaryExpr node represents a binary expression.
type BinaryExpr struct {
X Expr // left operand
OpPos token.Pos // position of Op
Op token.Token // operator
Y Expr // right operand
}
理解了 binary expression 就豁然开朗了,实际上就是你的 a * -1 表达式,Op 代表二元表达式的操作符,而 OpPos 代表操作符在表达式中的偏移。这里的 Op 类型是token.Token,实际上是个枚举值:
const (
// Special tokens
ILLEGAL Token = iota
EOF
COMMENT
// Identifiers and basic type literals
// (these tokens stand for classes of literals)
IDENT // main
.....
// Operators and delimiters
ADD // +
SUB // -
MUL // *
QUO // /
REM // %
AND // &
.....
ADD_ASSIGN // +=
.....
AND_ASSIGN // &=
.....
LAND // &&
.....
EQL // ==
.....
NEQ // !=
.....
LPAREN // (
.....
RPAREN // )
.....
// Keywords
BREAK
...略...
)
很好理解,就是一些特殊符号,比较符号,关键字,和理论上的 token 是一回事。X 和 Y 就更好理解了,左操作数,右操作数。
这里还没有看出抽象语法树的意思,再来一个稍微复杂一点的:
// example.go
package main
var a = 1 + 2
// parse.go
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
fset := token.NewFileSet()
// if the src parameter is nil, then will auto read the second filepath file
f, _ := parser.ParseFile(fset, "./example.go", nil, parser.Mode(0))
for _, d := range f.Decls {
ast.Print(fset, d)
}
}
>>> go run parse.go
会有下面这样的输出:
0 *ast.GenDecl {
1 . TokPos: ./example.go:3:1
2 . Tok: var
3 . Lparen: -
4 . Specs: []ast.Spec (len = 1) {
5 . . 0: *ast.ValueSpec {
6 . . . Names: []*ast.Ident (len = 1) {
7 . . . . 0: *ast.Ident {
8 . . . . . NamePos: ./example.go:3:5
9 . . . . . Name: "a"
10 . . . . . Obj: *ast.Object {
11 . . . . . . Kind: var
12 . . . . . . Name: "a"
13 . . . . . . Decl: *(obj @ 5)
14 . . . . . . Data: 0
15 . . . . . }
16 . . . . }
17 . . . }
18 . . . Values: []ast.Expr (len = 1) {
19 . . . . 0: *ast.BinaryExpr {
20 . . . . . X: *ast.BasicLit {
21 . . . . . . ValuePos: ./example.go:3:9
22 . . . . . . Kind: INT
23 . . . . . . Value: "1"
24 . . . . . }
25 . . . . . OpPos: ./example.go:3:11
26 . . . . . Op: +
27 . . . . . Y: *ast.BasicLit {
28 . . . . . . ValuePos: ./example.go:3:13
29 . . . . . . Kind: INT
30 . . . . . . Value: "2"
31 . . . . . }
32 . . . . }
33 . . . }
34 . . }
35 . }
36 . Rparen: -
37 }
在视觉上不太像一棵树啊,我们把它画出来~
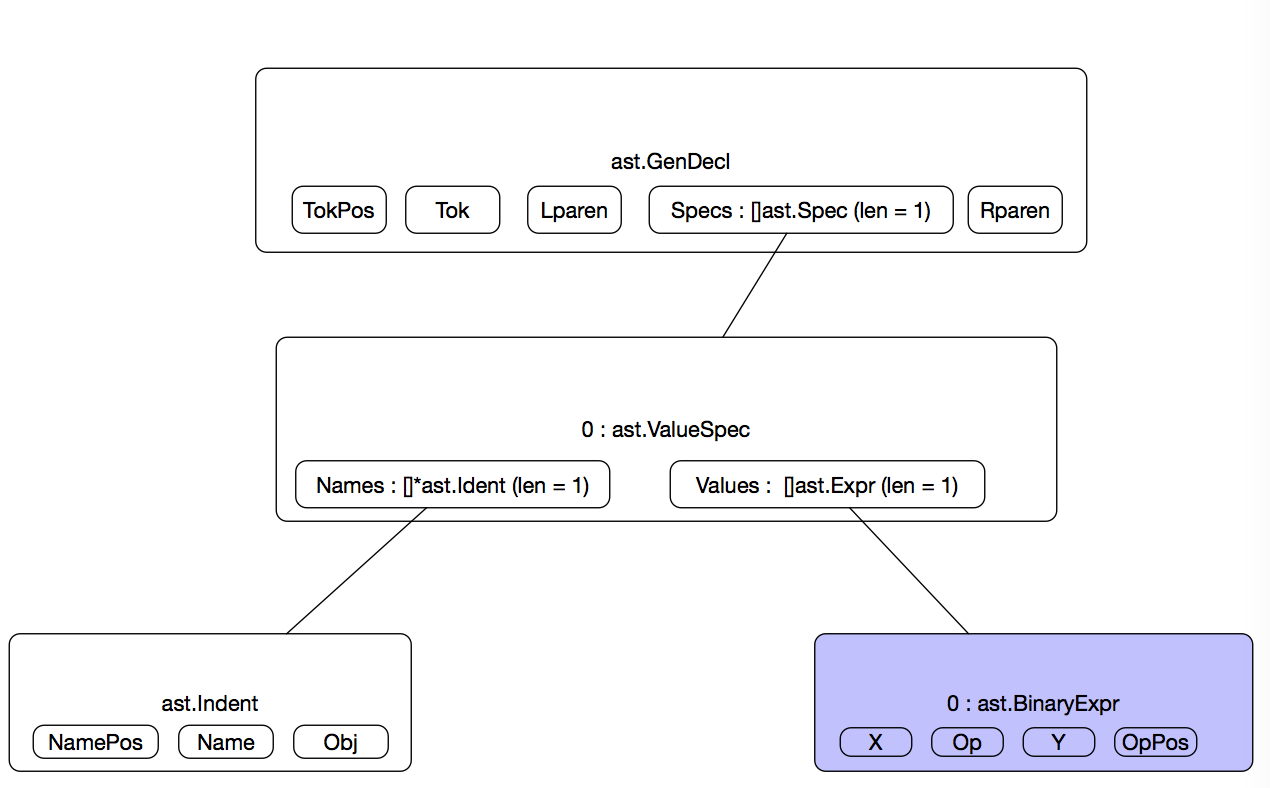
这下就像是一棵真正的树了(虽然实际上更严格意义上就是一个node)。
如果表达式再复杂一些,例如:
var a = 1 + 2 + 3
ast.BinaryExpr 这一部分会产生下面这样的变化:
19 . . . . 0: *ast.BinaryExpr {
20 . . . . . X: *ast.BinaryExpr {
21 . . . . . . X: *ast.BasicLit {
22 . . . . . . . ValuePos: ./example.go:3:9
23 . . . . . . . Kind: INT
24 . . . . . . . Value: "1"
25 . . . . . . }
26 . . . . . . OpPos: ./example.go:3:11
27 . . . . . . Op: +
28 . . . . . . Y: *ast.BasicLit {
29 . . . . . . . ValuePos: ./example.go:3:13
30 . . . . . . . Kind: INT
31 . . . . . . . Value: "2"
32 . . . . . . }
33 . . . . . }
34 . . . . . OpPos: ./example.go:3:15
35 . . . . . Op: +
36 . . . . . Y: *ast.BasicLit {
37 . . . . . . ValuePos: ./example.go:3:17
38 . . . . . . Kind: INT
39 . . . . . . Value: "3"
40 . . . . . }
41 . . . . }
显然外层的 X 结点现在变成了存储 1 + 2,+3 则存储在了外层的 Y 。实际上就是在语法分析的时候,按照优先级提前帮你把 1 + 2 进行结合并存入一个 ast 的 node 了。
这里提出一个思考题,如果让你对这个带有嵌套的 ast.BinaryExpr 进行求值,你觉得应该怎么做呢?(答案在文末)
了解了基本的二元表达式解析之后感觉自己已经无敌了,马上来个更复杂的实际代码的例子:
// parsefile.go
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
)
func main() {
fset := token.NewFileSet()
// if the src parameter is nil, then will auto read the second filepath file
f, _ := parser.ParseFile(fset, "example.go", src, parser.Mode(0))
for _, d := range f.Decls {
ast.Print(fset, d)
fmt.Println()
}
for _, d := range f.Imports {
ast.Print(fset, d)
fmt.Println()
}
}
var src = `package pppppp
import _ "log"
func add(n, m int) {}
`
ParseFile 的原型:
func ParseFile(fset *token.FileSet, filename string, src interface{}, mode Mode) (f *ast.File, err error)
会返回一个 ast.File 的结构体:
type File struct {
Doc *CommentGroup // associated documentation; or nil
Package token.Pos // position of "package" keyword
Name *Ident // package name
Decls []Decl // top-level declarations; or nil
Scope *Scope // package scope (this file only)
Imports []*ImportSpec // imports in this file
Unresolved []*Ident // unresolved identifiers in this file
Comments []*CommentGroup // list of all comments in the source file
}
如果看到这里还没有弃坑的话,那你已经赢了一半了,我们来看看parsefile.go的输出结果:
0 *ast.GenDecl {
1 . TokPos: example.go:2:1
2 . Tok: import
3 . Lparen: -
4 . Specs: []ast.Spec (len = 1) {
5 . . 0: *ast.ImportSpec {
6 . . . Name: *ast.Ident {
7 . . . . NamePos: example.go:2:8
8 . . . . Name: "_"
9 . . . }
10 . . . Path: *ast.BasicLit {
11 . . . . ValuePos: example.go:2:10
12 . . . . Kind: STRING
13 . . . . Value: "\"log\""
14 . . . }
15 . . . EndPos: -
16 . . }
17 . }
18 . Rparen: -
19 }
0 *ast.FuncDecl {
1 . Name: *ast.Ident {
2 . . NamePos: example.go:4:6
3 . . Name: "Add"
4 . . Obj: *ast.Object {
5 . . . Kind: func
6 . . . Name: "Add"
7 . . . Decl: *(obj @ 0)
8 . . }
9 . }
10 . Type: *ast.FuncType {
11 . . Func: example.go:4:1
12 . . Params: *ast.FieldList {
13 . . . Opening: example.go:4:9
14 . . . List: []*ast.Field (len = 1) {
15 . . . . 0: *ast.Field {
16 . . . . . Names: []*ast.Ident (len = 2) {
17 . . . . . . 0: *ast.Ident {
18 . . . . . . . NamePos: example.go:4:10
19 . . . . . . . Name: "n"
20 . . . . . . . Obj: *ast.Object {
21 . . . . . . . . Kind: var
22 . . . . . . . . Name: "n"
23 . . . . . . . . Decl: *(obj @ 15)
24 . . . . . . . }
25 . . . . . . }
26 . . . . . . 1: *ast.Ident {
27 . . . . . . . NamePos: example.go:4:13
28 . . . . . . . Name: "m"
29 . . . . . . . Obj: *ast.Object {
30 . . . . . . . . Kind: var
31 . . . . . . . . Name: "m"
32 . . . . . . . . Decl: *(obj @ 15)
33 . . . . . . . }
34 . . . . . . }
35 . . . . . }
36 . . . . . Type: *ast.Ident {
37 . . . . . . NamePos: example.go:4:15
38 . . . . . . Name: "int"
39 . . . . . }
40 . . . . }
41 . . . }
42 . . . Closing: example.go:4:18
43 . . }
44 . }
45 . Body: *ast.BlockStmt {
46 . . Lbrace: example.go:4:20
47 . . Rbrace: example.go:4:21
48 . }
49 }
0 *ast.ImportSpec {
1 . Name: *ast.Ident {
2 . . NamePos: example.go:2:8
3 . . Name: "_"
4 . }
5 . Path: *ast.BasicLit {
6 . . ValuePos: example.go:2:10
7 . . Kind: STRING
8 . . Value: "\"log\""
9 . }
10 . EndPos: -
11 }
ast.GenDecl 和 ast.FuncDecl 都实现了 ast.Decl 这个 interface,所以可以统一地存在 ast.Decl 的数组中(golang的特性)。看看这个 interface 长啥样:
type Decl interface {
Node
// contains filtered or unexported methods
}
type Node interface {
Pos() token.Pos // position of first character belonging to the node
End() token.Pos // position of first character immediately after the node
}
可以看到,任意类型只要实现了这里的 Pos 和 End 方法,就可以被当作一个 ast.Decl 的 node 来操作(golang 特性)。证据在此:


另外一点值得注意的是,我们这个例子中的函数声明的参数列表使用了:
func add(n, m int) {}
n, m int 这种偷懒形式(其实从规范的角度来讲,这样写不太好,变量和类型的视觉距离变远了)。在被 go 的 parser 解析过之后被合并到了同一个 ast.Field 里,用不同的 name 来表示不同的参数,感兴趣的话你可以试试用 n int, m int 来修改这个程序,看看输出会有什么变化~
这个例子里的函数体里没有逻辑,所以 body 部分基本是空的,只有左括号和右括号。
不过到了这一步,我们已经拿到了一个程序的梗概。我们可以从 golang 的源码中提取出这个文件中的 import 信息,doc 信息,comment 信息,声明(类型、函数)信息,也可以通过遍历这些 AST 来获取到 struct 内的字段名、字段类型、tag 值,函数的 body,函数内的语句块。
我们这里举的例子相对真实场景下的代码来说还要简单的多,下面是 ast 包中的结构体们的一个继承/实现关系:
Node
Decl
*BadDecl
*FuncDecl
*GenDecl
Expr
*ArrayType
*BadExpr
*BasicLit
*BinaryExpr
*CallExpr
*ChanType
*CompositeLit
*Ellipsis
*FuncLit
*FuncType
*Ident
*IndexExpr
*InterfaceType
*KeyValueExpr
*MapType
*ParenExpr
*SelectorExpr
*SliceExpr
*StarExpr
*StructType
*TypeAssertExpr
*UnaryExpr
Spec
*ImportSpec
*TypeSpec
*ValueSpec
Stmt
*AssignStmt
*BadStmt
*BlockStmt
*BranchStmt
*CaseClause
*CommClause
*DeclStmt
*DeferStmt
*EmptyStmt
*ExprStmt
*ForStmt
*GoStmt
*IfStmt
*IncDecStmt
*LabeledStmt
*RangeStmt
*ReturnStmt
*SelectStmt
*SendStmt
*SwitchStmt
*TypeSwitchStmt
*Comment
*CommentGroup
*Field
*FieldList
*File
*Package
你体会一下。
。。。蛋定,先静静心,把上面这个继承关系忘掉(要不你会崩溃的)。我们继续来回忆第一次 ParseFile 操作了一个弱智文件的喜悦,在这里问一个问题,有了之前得到的函数声明啊,类型声明啊,评论之类的信息,我们可以做些啥事呢?
相信你已经想到了,我可以按照自己制定的字段命名规范去检查出所有不符合规范的变量、函数名。但是我们发现,这件事情似乎已经有人帮我们做了。。。golint。
那么还有 Doc 和 Comment,如果我们按照规范来组织这些信息,可以直接给我们的 golang 程序生成文档!然后发现这件事情官方已经做了。。。godoc
哦,还可以检查文件里有哪些没有 import 没有被用到(pia,好好好不逗比,说正经的。
先说最简单的,如果我提供一个只有形如
type Person struct {
age int `json:"age"`
}
的定义的文件,那么我们就可以通过 ParseFile 轻而易举地拿到这个 struct 的全部信息,对于我们来说,这个 struct 的字段的名字、类型、tag 就都是可见的了。
看到这里可能你还是懵逼的,我再改一下这个 struct 的定义:
// for api @post @/user/create
type createAccountRequest struct {
Age int `form:"age"` validation:"gte=18"`
Name string `form:"name" validation:"length>0"`
}
是不是感觉恍然大悟了?
在每一个 web 开发的入口层 api,一般会做统一的参数绑定和校验,实际上这些工作大多数情况下都是让人比较烦躁的重复劳动。
比如你的代码可能是这样的:
func createAccount(w http.ResponseWriter, req *http.Request) {
req.ParseForm()
var createRequest = createAccountRequest{}
if createRequest.Age, ok = req.Form["age"];!ok {
return someErrorResponse
}
if createRequest.Name, ok = req.Form["name"]; !ok {
return someErrorResponse
}
......
}
生活真是不美好,如果这个 Request 有 50 个字段,我真的有点想跳楼。
我们怎么用现在刚学到的黑科技偷懒呢?
很简单,我们只要先写一个带有 tag 的 request 的 struct 定义的 go 文件,然后对它进行 ParseFile。拿到所有顶级的GenDecl,再根据 Tok == type? ,简单判断一下是否是我们想要的类型的文件。
然后通过遍历这些顶级的 request struct 定义,我们可以得到每个 request 对应每个 field 的 tag 下的对应的 value。有了这些 value 之后,结合 Names 和 Type 字段根据 value 就可以生成我们想要的东西了。比如这个例子里的 form 字段,我们完全可以自动生成 ParseForm,req.Age = Form["age"]代码。还可以根据他来生成某个 api 的 swagger 文档的 spec。至于 tag 里的 validation 字段,则要麻烦一些,我们虽然可以根据它来生成 struct 的 validation 函数(有反射洁癖或者确实有“高性能”要求的人大概喜欢这么干,实际上 validation 有现成的基于反射的轮子),但 validate 的轮子造起来比较体力活。。。建议直接使用开源工具。
完成了参数的绑定和 validation,对于通常的 Web 开发
controller 层就没有什么复杂的任务了。在生成的代码基础上,我们还可以补充一些自己的 validate 逻辑。举例来说,XXXID 可能需要去外部系统验证合法性,只要在生成的函数中补上这一步缺失逻辑即可。
这里不得不提到 golang 的类型默认值导致的麻烦问题,例如下面的 struct:
type req struct {
Age int
}
如果你声明了这样的 struct,并把 http 的请求数据绑定到了这个 struct 的 Age 字段。
那么当 Age == 0 的时候,你就再也没有办法判断这个 0 到底是 go 的类型默认值还是调用方压根儿没有传这个参数了。解决方法倒也是有,你可以把 Age 变成 *int,然后在每次取 req.Age 的时候都去解引用。估且算是可以解决。这个场景在一些从 0 开始计的 Type/Status 会存在这样的问题。所以请务必留意。
有点跑题。高谈阔论了一堆,我们以一个实例结尾吧:
// example.go
package lp
type CollectRequest struct {
Star int `form:"star" validation:"gte=1,lte=5" doc:"formData"`
}
// parse.go
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
"strings"
)
var codeTemplate = `
func getReqStruct(r *http.Request) (*{{requestStructName}}, error) {
r.ParseForm()
var reqStruct = &{{requestStructName}}{}
// bind data
{{bindData}}j
// bind partial example
// reqStruct.{{fieldName}} =
// {{transToFieldType}}(r.Form['{{fieldTagFormName}}'])
if bindErr != nil {
return nil, err
}
// validate data
{{validateData}}
// validate partial example
// validateErr = validate(reqStruct.{{fieldName}}, validateStr)
// if validateErr != nil
// return nil, err
return reqStruct, nil
}
`
func getTag(input string) []structTag {
var out []structTag
var tagStr = input
tagStr = strings.Replace(tagStr, "`", "", -1)
tagStr = strings.Replace(tagStr, "\"", "", -1)
tagList := strings.Split(tagStr, " ")
for _, val := range tagList {
tmpArr := strings.Split(val, ":")
st := structTag{}
st.key = tmpArr[0]
st.values = strings.Split(tmpArr[1], ",")
out = append(out, st)
}
return out
}
type structTag struct {
key string
values []string
}
func main() {
fset := token.NewFileSet()
// if the src parameter is nil, then will auto read the second filepath file
f, _ := parser.ParseFile(fset, "./example.go", nil, parser.Mode(0))
// ast.Print(fset, f.Decls[0])
tagList := getTag(f.Decls[0].(*ast.GenDecl).Specs[0].(*ast.TypeSpec).Type.(*ast.StructType).Fields.List[0].Tag.Value)
fieldName := f.Decls[0].(*ast.GenDecl).Specs[0].(*ast.TypeSpec).Type.(*ast.StructType).Fields.List[0].Names[0].Name
fieldType := f.Decls[0].(*ast.GenDecl).Specs[0].(*ast.TypeSpec).Type.(*ast.StructType).Fields.List[0].Type.(*ast.Ident).Name
requestStructName := f.Decls[0].(*ast.GenDecl).Specs[0].(*ast.TypeSpec).Name.Name
fmt.Println(tagList)
fmt.Println(fieldName)
fmt.Println(fieldType)
fmt.Println(requestStructName)
}
go run parse.go
然后看看输出结果,是不是豁然开朗了~
doc 生成的部分我想暂时保留,因为明年还指着这个升Dx(pia
唔,等我们写完了分享出来吧。
这篇文章本来的目的是抛砖引玉,也可以说是授人以渔。有了这些知识储备,你就可以撸起袖子开始造自己的轮子了,当然希望你不要造出来方的。
除此之外,我们还可以再做一些代码生成功能之外的畅想。
这里再次出个思考题,是否可以通过 ast 分析来规避之前线上 golang 系统出现的几次事故呢?欢迎来讨论。
文中思考题的答案:
递归遍历即可,递归终结条件 node.X is ast.BasicLit && node.Y is ast.BasicLit。下面是 ast.BasicLit 的定义:
type BasicLit struct {
ValuePos token.Pos // literal position
Kind token.Token // token.INT, token.FLOAT, token.IMAG, token.CHAR, or token.STRING
Value string // literal string; e.g. 42, 0x7f, 3.14, 1e-9, 2.4i, 'a', '\x7f', "foo" or `\m\n\o`
}
除了 ast 我们还可以利用其它工具帮助我们进行代码生成,如果有空的话,可能会再介绍一下如何使用 mysql 的 information_schema 来帮助我们完成 dao 层的代码。减少重复工作,提高幸福感。
最后引个战:如果一个依赖不多的项目的 dao 层和 controller
层代码都可以自动生成,只需要完成 logic 的代码,三十分钟内我可以完成一个项目的一个 api 的编写。这种情况下还有谁能够责难静态语言的开发效率低呢?
