Go 项目做的比较大(主要说代码多,参与人多)之后,可能会遇到类似下面这样的问题:
- 程序老是半夜崩,崩了以后就重启了,我也醒不来,现场早就丢了,不知道怎么定位
- 这压测开压之后,随机出问题,可能两小时,也可能五小时以后才出问题,这我蹲点蹲出痔疮都不一定能等到崩溃的那个时间点啊
- 有些级联失败,最后留下现场并不能帮助我们准确地判断问题的根因,我们需要出问题时第一时间的现场
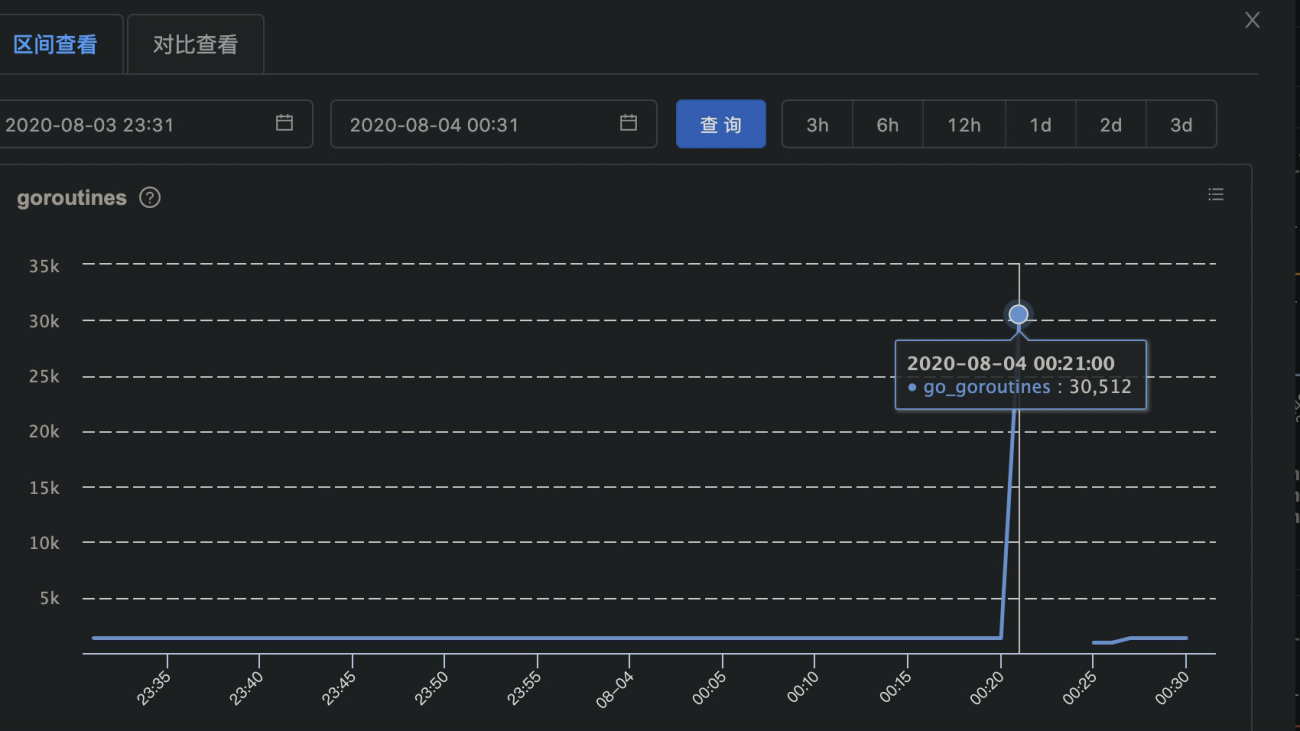
Go 内置的 pprof 虽然是问题定位的神器,但是没有办法让你恰好在出问题的那个时间点,把相应的现场保存下来进行分析。特别是一些随机出现的内存泄露、CPU 抖动,等你发现有泄露的时候,可能程序已经 OOM 被 kill 掉了。而 CPU 抖动,你可以蹲了一星期都不一定蹲得到。
这个问题最好的解决办法是 continuous profiling,不过这个理念需要公司的监控系统配合,在没有达到最终目标前,我们可以先向前迈一小步,看看怎么用比较低的成本来解决这个问题。
从现象上,可以将出问题的症状简单分个类:
- cpu 抖动:有可能是模块内有一些比较冷门的逻辑,触发概率比较低,比如半夜的定时脚本,触发了以后你还在睡觉,这时候要定位就比较闹心了。
- 内存使用抖动:有很多种情况会导致内存使用抖动,比如突然涌入了大量请求,导致本身创建了过多的对象。也可能是 goroutine 泄露。也可能是突然有锁冲突,也可能是突然有 IO 抖动。原因太多了,猜是没法猜出根因的。
- goroutine 数暴涨,可能是死锁,可能是数据生产完了 channel 没关闭,也可能是 IO 抖了什么的。
CPU 使用,内存占用和 goroutine 数,都可以用数值表示,所以不管是“暴涨”还是抖动,都可以用简单的规则来表示:
- xx 突然比正常情况下的平均值高出了 25%
- xx 超过了模块正常情况下的最高水位线
这两条规则可以描述大部分情况下的异常,规则一可以表示瞬时的,剧烈的抖动,之后可能迅速恢复了;规则二可以用来表示那些缓慢上升,但最终超出系统负荷的情况,例如 1s 泄露一兆内存,直至几小时后 OOM。
而与均值的 diff,在没有历史数据的情况下,就只能在程序内自行收集了,比如 goroutine 的数据,我们可以每 x 秒运行一次采集,在内存中保留最近 N 个周期的 goroutine 计数,并持续与之前记录的 goroutine 数据均值进行 diff:
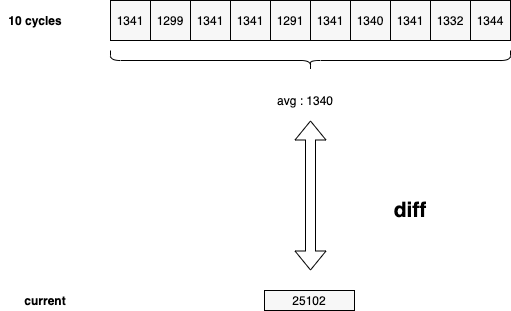
比如像图里的情况,前十个周期收集到的 goroutine 数在 1300 左右波动,而最新周期收集到的数据为 2w+,这显然是瞬时触发导致的异常情况,那么我们就可以在这个点自动地去做一些事情,比如:
- 把当前的 goroutine 栈 dump 下来
- 把当前的 cpu profile dump 下来
- 把当前的 off-cpu profile dump 下来
- 不怕死的话,也可以 dump 几秒的 trace
文件保存下来,模块挂掉也就无所谓了。之后在喝茶的时候,发现线上曾经出现过崩溃,那再去线上机器把文件捞下来,一边喝茶一边分析,还是比较悠哉的。
这里面稍微麻烦一些的是 CPU 和内存使用量的采集,现在的应用可能跑在物理机上,也可能跑在 docker 中,因此在获取用量时,需要我们自己去做一些定制。物理机中的数据采集,可以使用 gopsutil,docker 中的数据采集,可以参考少量 cgroups 中的实现。
更具体的代码会在之后的文章讲,我们编写的 lib 也会在不久后开源,当然,这篇文章其实已经把大部分实现思路讲完了~
