大多数应用开发人员(特别是php开发人员,不是我黑php orz)对锁可能都没什么概念,如果说有,那大概也只知道数据库 transaction 里的锁。即使是知道 db 的锁,了解也非常得粗浅(比如去年的我)。
实际上数据库的锁非常的复杂,和 os 的锁的概念完全不是一回事,具体实现还和存储引擎、事务的隔离级别相关。所以这里还是不谈这个orz。等我有机会总结了之后再说。
我们这里要说的是分布式锁。分布式锁是什么呢?
在分布式系统中,某个任务可能会因为正确性或者效率两方面的考量,在同一个时刻内只允许一个实例执行。
正确性:例如有个游戏,每天凌晨0点,向所有玩家发放20金币的奖励,防止玩家输光了家当对游戏失去性趣。注意了,我们只给你发20个金币,这个任务被执行两次的话,所有玩家会收到40金币而不是20金币。从业务逻辑的角度讲,这显然是不可接受的错误。
效率:例如一个对账程序,会在每天半夜2点业务低峰期,把当天的所有用户数据捞出来,进行一些总体数值的计算和核对。这个计算任务很繁重,可能需要一个进程跑4个小时才能结束。多个计算结点实际上只需要有一个结点在跑就行,因为这个计算集群不只有这一个对账任务。如果同时有两个以上的程序执行计算,那对于计算集群实际上就是一种资源浪费。老外们举个更实际的例子,如果计算任务被 aws 上的其它进程执行相当于消耗了更多的计算资源,说明你要付更多的钱给 amazon 了~
问题来了,我们设计的可随意横向扩展的系统/计算集群在分布式系统的前提下,实例都是无状态的,所谓无状态,即每个结点不会在本地保存任何数据,只有可以运行的代码逻辑。在这种无中心的系统中,你没有办法判断当前某个任务正在被集群中的哪一个结点所执行。或者换个说法,你连这个任务到底有没有正在被执行,被谁执行都不清楚。
这时候就轮到分布式锁出场了。假如你的任务数据是存储在 db 里,最简单的分布式锁其实可以就是 db 里的一个字段。举个例子:
+-------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| executor_ip | varchar(20) | NO | | | |
| task_status | tinyint(4) | NO | | | |
+-------------+-------------+------+-----+---------+----------------+
只要使用这个表里的 task_status 字段,就可以实现一个最简单的抢占式的分布式锁。实际的运行流程是下面这样的:
process A: update task set task_status = {{running}}, executor_ip = {{my_ip_addr}} where id = {{task_id}} and task_status = {{not_running}}
process A: if affected_rows == 1, then execute the task
process B: update task set task_status = {{running}}, executor_ip = {{my_ip_addr}} where id = {{task_id}} and task_status = {{not_running}}
process B: affected_rows = 0, find another task.
process A: task done, update task set task_status = {{finished}} where id = {{task_id}} and task_status = {{running}}
看起来很完美,只要 process B 是在 A 拿到了锁之后再来 update,那无论如何都是不可能拿到这个锁的。但是这种模式存在一个很明显的问题,如果 process A 在拿到了锁之后挂掉了怎么办。不要觉得这个挂掉了不可能,很多时候我们就是要面对这样的情况进行编程。在现在都是低成本机器当服务器的时代,一台机器挂掉太正常了。如果是写分布式程序,那几乎就是无时无刻不在考虑这种机器挂掉,网络分区,时间序列错乱导致的问题。
上面的假设的结论其实很简单,这个任务在没有强制介入的情况下就没有办法继续跑下去了。即使挂掉的实例恢复以后,因为“无状态”,所以任务运行的中间态数据肯定是全部丢失掉了,也没有办法主动把锁置位(当然了,你也可以自己写一些恢复判断,比如db里有当前我这个实例占有的锁,在进程启动的时候全部置为初始状态,但是请别打岔啊)。要说怎么解决问题,大概很多人会手动地把 db 里的任务置为 not_running,等待这个任务下一次被其它的实例重新抢占。
看起来是不是好麻烦。不用担心,分布式领域的研究早在20多年前就有人帮我们想好了解决办法。lease的论文,虽然lease的论文本身是为了解决缓存的一致性问题,但是他的核心概念“租期”是很多理论的基础。具体到我们这里,实际上就是给锁加上超时时间。基于 db 的锁是没有办法去给他加上超时时间的,除非你再去加一个超时时间的字段,再让另一个程序建立计时器的小顶堆,然后定时去释放这些锁(啊,那我岂不是完全可以在另外的程序里去实现这个锁了?是的,你说的对)。多了另一个程序你是不是还又增加了系统的复杂度。。
因为用 db 来加锁没有办法很轻松地满足我们的超时时间的需求,就有人想出了用 redis 的 setnx 的办法,来看看我最近接手的一个项目里的分布式锁的实现:
func Lock(params) {
if codis.IsOk != nil {
strCmd := "SETNX"
var sStrVal []interface{}
sendCmdToRedis()
if err != nil {
err = lockFailed
return
}
if nSetRet == 0 {
//has locked
return
}
strCmdExp := "EXPIRE"
expireTime := []interface{}{lockDuration}
sendCmdToRedis()
if err != nil {
err = expireFailed
}
} else {
err = xxxx
}
return
}
用上 golang 时髦的 defer 在 lock 完马上 defer 一发:
defer func(){
redis.del(lockKey)
}()
先 setnx,判断是否成功,然后 expire,判断是否成功,业务处理完毕后del lock。看起来天衣无缝?
显然是有问题的。
在上面讨论数据库锁的时候提到,在代码执行过程中进程可能挂掉,而这里加锁的过程中你的代码就不会挂了么?像下面的场景:
setnx lockKey
====== instance down =======
expire lockKey 3600s
显然,你的超时时间就加不上了。如果后续有其它进程想要完成这个计算任务就变成了不可能。你只能自己手动到线上再手动连上 redis,再手动把这个 lock 给 del 掉。
实际上我们需要让 setnx 和 expire 成为一个原子操作才可以。在 redis 2.6 之后,官方支持直接在 set 命令中加 ex 和 nx 参数,即在一个 set 命令中完成 setnx 和 setex 的功能。看起来非原子操作的问题是解决了~
但这样依然是有问题的,使用 setnx 和 setex 的对我们的 redis 进程本身的可靠性是有要求的,如果 redis 进程在业务加锁之后挂掉了,那么之后所有的进程就都获取不到锁了。这样会导致你的锁服务不可用。但是这里引入 redis 的主从似乎也不正确,因为 redis 的主从同步是异步行为,在主上加锁成功,数据没有同步之前 master 挂掉了,那之后就可能会由多个实例持有锁,这显然不是我们希望的。
为了解决这个问题,redis 的作者提出了 Redlock 的加锁方法,详见redlock。如果你不想看长文,我摘出了在官方推荐的 golang 版 redlock 客户端中的 lock 函数来一探究竟:
// Lock locks m. In case it returns an error on failure, you may retry to acquire the lock by calling this method again.
func (m *Mutex) Lock() error {
m.nodem.Lock()
defer m.nodem.Unlock()
value, err := m.genValue()
if err != nil {
return err
}
//实际上每次NewMutex的时候就可以直接指定重试的次数,代码里默认32。。。
for i := 0; i < m.tries; i++ {
if i != 0 {
//如果是重试,那么最好先delay,再重试
time.Sleep(m.delay)
}
start := time.Now()
n := 0
for _, pool := range m.pools {
//获取锁,实际上就是set nx px
ok := m.acquire(pool, value)
if ok {
n++
}
}
until := time.Now().Add(m.expiry - time.Now().Sub(start) - time.Duration(int64(float64(m.expiry)*m.factor)) + 2*time.Millisecond)
// quorum 选项是结点数/2+1
if n >= m.quorum && time.Now().Before(until) {
m.value = value
m.until = until
return nil
}
for _, pool := range m.pools {
m.release(pool, value)
}
}
return ErrFailed
}
func (m *Mutex) acquire(pool Pool, value string) bool {
conn := pool.Get()
defer conn.Close()
reply, err := redis.String(conn.Do("SET", m.name, value, "NX", "PX", int(m.expiry/time.Millisecond)))
return err == nil && reply == "OK"
}
看完代码就很明了了,因为作者觉得你单实例始终解决不了锁服务的高可用问题,那我就多个实例,然后按照常见的 node num / 2 + 1 这种方式来做高可用,每次加锁都去所有节点上加锁,只要获取到半数以上,那我就认为这次加锁成功了。如果加锁失败,我也会在重试的过程中主动 release,即使我不 release,在 set 的时候也已经设置了超时时间。我这个加锁的进程挂了也大丈夫对不对?
对我们凡人来说看起来是真的天衣无缝了。不过还是有分布式领域的专家提出了置疑,详见how to do distributed locking。这位专家搞事情的理由是现在分布式系统里有一些程序是用带有 gc 功能的语言完成的,而这在这些语言里,gc 属于不可控的行为,完全有可能发生下面这样的事情:
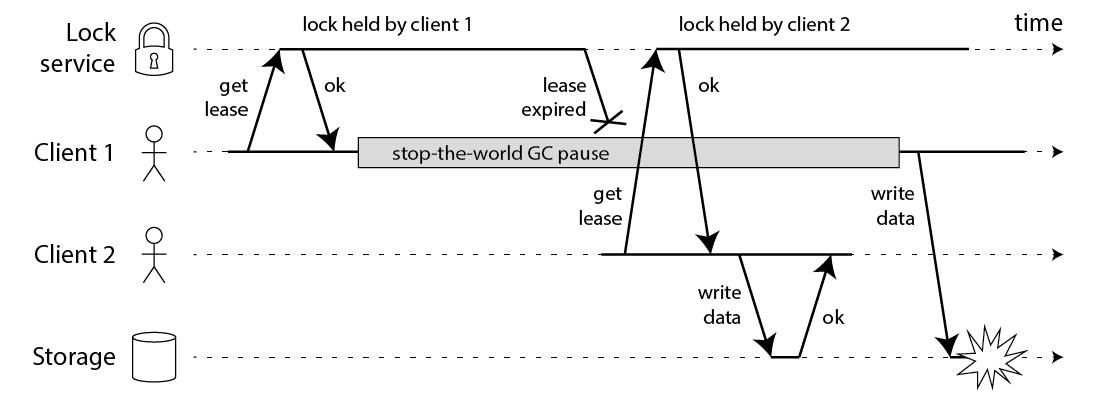
我只能说不愧是专家,就是能搞事情!专家又提出了一个解决方案:
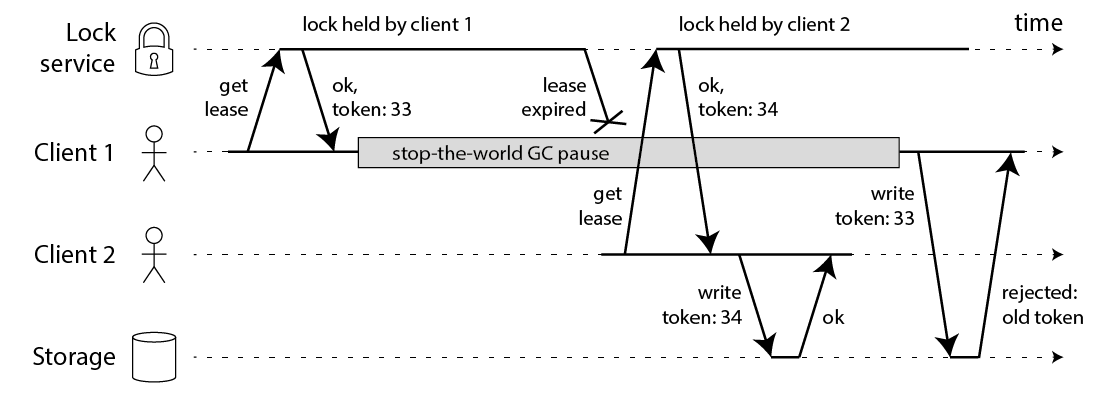
大致的意思就是说你的锁还需要提供一个每次获取锁都能叠加的 token,而在向存储系统写入的时候,应该要把这个 token 也写到你的数据里,这样在 gc 发生后,stale 的老数据会因为 token 过期而写失败。
这件事情在 hacker news 上激起了激♂烈的争论:
hacker news上的争论。各种大佬各执一词。
实际上这位专家所说的是另一个范畴的问题,就是获取锁与写入的顺序以及数据安全的问题。如果说你的加锁是像这样的流程:
lock
do something without check
unlock or lock timeout
实际上不管你用 redis 还是其它服务,比如 zookeeper 还是 etcd 还是 consul,那结局都是一样的。都会遇到这种 gc 的问题。只是这次恰好中枪的是 redlock 而已233。专家从正确性和数据安全的角度举出这个 case 完全没有什么问题。但是如果我们现在就是拿 redis 的 setnx 或者 redlock 来做锁,那么为了解决专家提出的这个问题就只能把短时间锁的时间加长,或者再加上更多的判断逻辑,比如在获取了锁之后,再调用 get 方法去获取当前的 fencing-token。redis 的作者认为自己生成个 uuid 其实就差不多了。这里也是有一些争议的。
当然了也不是说 redlock 真的没有问题,因为每次 redlock 每次获取锁都要去所有机器上获取,那如果有某台实例响应慢,那就是会拖慢整体获取锁的速度,这在某些场景下获取是不太可以接受的,但如果是计算类型的任务,其实也无所谓,超时时间不是那么长就好了。剩下的唯一的缺点大概就是每次都要去一堆结点上获取锁在某些场景下不现实的问题了,比如现在很多公司里会用 redis proxy,而 proxy 常常会屏蔽掉后端的 redis 结点,这种情况下 redlock 就变得完全不可用了。我们也不太可能只是为了一个锁服务再额外地去搭五台以上的 redis 实例。
所以更靠谱的做法还是用zookeeper/consul/etcd来做。实例稍后补充~
