Gopher China 讲师尘埃落定,可惜今年没有获得去讲的机会,把之前的内容总结在 Blog 里吧~
由于 MySQL 类带 Schema 类存储系统的设计问题,不支持快速的列扩充,实际业务中,一个业务实体的属性随着业务的发展是一定会膨胀的。这样持续在 MySQL 上加列往往就会捉襟见肘。比如我的历史业务订单表有 50 个字段,虽然会对历史数据进行归档,但在线上还是会有千万甚至亿级的数据,这时候在 MySQL 上加列一般使用 PTOSC 或者 Ghost 来改表,两者设计有区别,但缺点都一样:慢。
比如在我们公司的订单表加一个字段,都是天级别。如果没记错的话,之前听说是一周(错了的话欢迎指出),其间可能还会因为磁盘空间不足之类的原因在升级过程中失败(汗)。虽然 MySQL 本身也在发展,在 8.0 之后已经可以秒加列了,但市面上的存量系统在存储上是不可能轻易升级的(历史上我司升级数据库导致过一整天的数据错乱),如果升错了会导致非常大的事故,可能 DBA 们都要卷铺盖走人了。所以在经历过 DB 导致的大事故的公司,DBA 们肯定是慎之又慎的,你不应该强求他们追求新技术。
如果业务要在实体上增加核心属性(如要求强一致,有事务需求)时,需要忍受数据库的加列成本,这没有办法。但增加一些额外的非核心属性,对一致性要求也不高的字段,那就不应该去忍受这种按周来记的加列成本了。大多数公司会有额外的存储系统来存储这些非核心字段,有时也叫“特征”。
简单的特征,就是简单的 kv 对,或者 hash。以订单 ID 为例,我们可以以订单 ID 作为 key,然后以其属性作为 subkey,这样就可以在核心存储之外额外地存储更多字段。虽然从数据结构上来讲,这样的数据可以存储在 Redis 里,但 Redis 基于内存,成本很高,并且其持久化方案并不靠谱。这时候就需要有类似 PIKA 的系统来帮助存储这些数据了。因为 kv 的研发成本不像 dbms 那么高,所以大多数大公司都会有自己的持久化 kv 存储系统,并且对业务暴露 Redis 协议,以方便接入。
这时候作为特征系统,就是对存储中的 kv 和 hash 进行封装,并对业务暴露同样的 set/get 接口,业务就可以 happy 地不用关心存储的具体实现了。
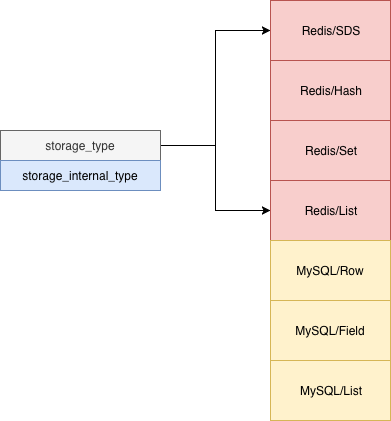
有了 kv 和 hash 之后还不够,有时业务希望能够有幂等的计数,这时候我们可以将一些可以做唯一 ID 的内容作为 set 的 member 塞到 kv 存储,并用 scard 进行计数。因为有了过往的数据结构,慢慢业务也希望你的系统能够支持其它类型的存储,对于大多数微服务系统的流程环节来说,这样可以使它们变成完全的无状态服务,而数据系统作为下层支撑系统对其进行支持。这之后甚至业务希望你的系统能够帮他们做一些外部门的系统代理,这样他们就可以不用同时接一大堆 SDK 了,我们对“存储”本身的定义进行了扩展,之前的存储接口,我们定义为 set、get,外部系统对于我们来说实际上是可读不可写的一种特殊的“存储”,我们可以用下面的方式对其中所存储的数据进行描述:
业务通过 RPC 同步写入、读取的数据可以保证最低限度的延迟(从写入到读取,其实没延迟)。但其也有缺点,如果下游有 N 个系统需要这些数据,那么我需要在业务流程进行的中途挨个写给下游系统,并且这让流程系统对其它非流程系统间接产生了依赖,依赖的系统越多,稳定性就越成问题。这时候我希望那些实时性要求没那么高的数据,直接通过 MQ 发出去,下游系统通过 MQ 订阅以达到上下游依赖的反转。即:
流程系统 -- 依赖 --> 其它系统
变成:
流程系统 <-- 依赖 -- 其它系统
相对来说后者是更为合理的架构。这样事后的现场还原或者反作弊的需求迭代不会影响到核心系统的稳定性。
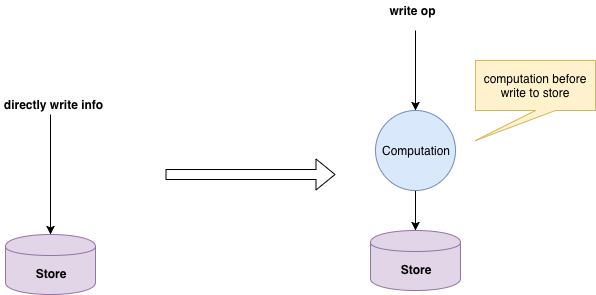
先期的时候,特征系统的数据来源只有 RPC,这时候,特征系统的数据源又增加了 MQ,所以我们需要将 MQ 订阅、数据清洗、写入,也以某种形式接入到特征系统本身。接入 MQ 初期的需求也比较简单,我们能把 MQ 的某个 topic 的字段从 msg 中清洗出来,并且当作一个特征写入即可,如下图:

我们实现了用 jpath 对源数据内容进行描述的能力,这样只要指定一个目标字段名和其在源数据中的 jpath,那就可以实现将源数据打平成一层 map 的目的。
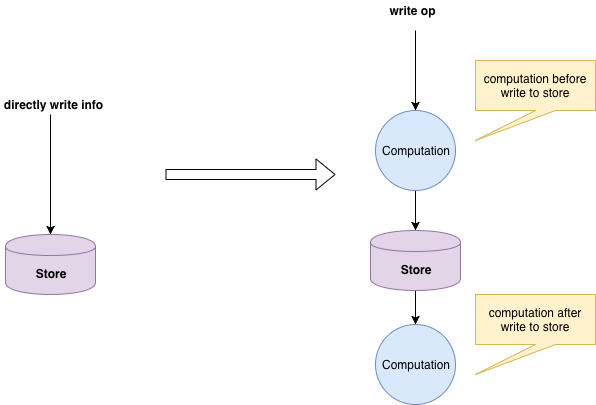
相比最初通过 RPC 进行的 set/get,通过 MQ 进入系统的流程只是在入口稍有区别,读取流程和以前差不多。再之后,除了直接从 MQ 中清洗字段。我们还需要对 MQ 来的数据进行计数。这时候整个流程不再是简单的 ETL 和写入,需要在写入前进行计算,如下图:
老的模型没有支持这样的需求,所以这时候由各种人在该系统上编写了大量的计算代码,大多数其实也比较简单,就是做一些简单的判断,调用存储提供的 incrBy 接口。
在编写了大量的重复代码之后,我们对存储流程进行了改进,增加了“算子”的概念,并且使算子可以对存储操作进行环绕,如下图:
在之前接过的需求基础上,我们做了一些通用的算子来进行复用,只要简单提供一些配置项,就可以在不写代码的情况下完成计算和存储流程。比如其中的表达式算子,可以支持下面这些形式的“计算”:
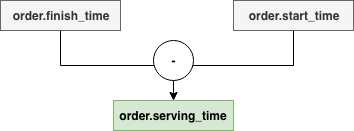
表达式求值我们用了 govaluate 来做,基本的 if/else,加减乘除都可以支持,并且可以通过自定义函数来扩展其功能。当然,这种东西使用要适度,如果过度了,你的代码大头跑数据库里去了,那肯定不行。
虽然已经实现了一些通用算子。但在实在没有可复用的算子时,也只要霸占一个算子 ID,并以相同的 interface 实现并注册到全局的算子表里即可。
之后的需求迭代过程中,这套算子流程可以很好地解决之前的 90% 的问题,但业务总是会变得复杂,又出现了很多单一算子解决不了的问题,但是这些需求拆分成细粒度之后又显得不那么复杂,理论上能组合两个算子就可以完成,但不支持的情况下就需要写定制算子。所以这个阶段又产生了一些没什么意思的重复劳动。在这个基础上,我们马上将算子流程拆分成了 pipeline,以支持这种简单的组合需求,所以痛苦只持续了很短一段时间就结束了。在修改完成后,我们的算子 pipeline 可以任意地排列,并且可以支持在运算失败后进行静默跳过(或者整体失败),如下图:
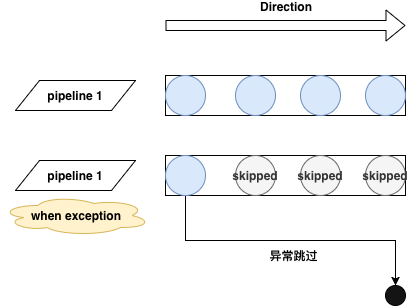
看起来似乎问题都解决了。但是在老系统迁移的过程中,我们碰到了比较麻烦的写放大问题,特别是从 MQ 中清洗数据时,有些 topic 中字段繁多,会一次性清洗出大量 value 需要写入,如图:
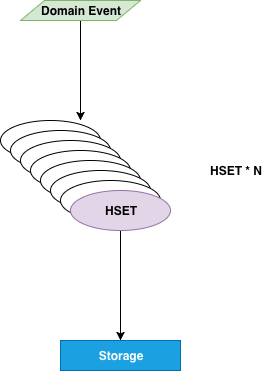
对于大多数存储系统来说,写入时进行 batch 是行之有效的优化办法,但每种存储系统能不能做 batch 的依据又不太一样。以我们的系统设计为例,引擎层负责整个 ETL 到存储、计算流程的串联,但引擎层对下层存储的具体细节并不了解。实现具体存储逻辑的时候,我们可以知道怎么样进行 merge 最合适,但怎么把这种逻辑表达给引擎层呢?这时候我想了个简单的办法,在存储层提供一个字符串,暂且称为 merge sign,引擎依据 merge sign,对同层的特征进行排序和分组,存储需要保证的是 merge sign 相同的前提下,get 和 set 操作一定可以合并。而之前的 get set 接口也由单独的写入接口变成了 mget 和 mset,单独写入和批量写入走同一套逻辑,这样引擎在分组完成之后,只要调用一致的 mset 和 mget 接口即可,逻辑上可以做到统一。
上面这段描述可能比较抽象,我举个简单的例子。当整个系统的输入特征在存储层面存在某些共性的时候,我们就可以把存储操作进行合并。比如当多个特征满足下面条件的时候:
- 输入参数一致
- 特征存储类型和内部类型均为 redis/hash
- 特征的 key template 一致
- 特征存储的集群一致
那么我们就可以将这些特征的读/写进行合并,写入用 hmset,读取用 hmget。对于存储的具体实现(这里是 redis/hash),需要能返回一个字符串将这种可以合并的指示告诉更上层的模块,所以我们可以以下述规则拼接一个字符串:
redis#hash#cluster_xfs#key_tpl_{{driver_id}}#param[driver_id]
更上层的模块在拿到这个字符串之后,就可以知道怎么对当前正在执行读/写操作的特征进行分组了。非常简单的算法问题。
看起来大部分问题都解决了,但是系统迭代的过程中又出现了新的问题,以一个虚构的例子来说,有些数据在我们的存储中存储的是 driver_id => 字段的映射,但某些业务方可能没有 driver_id 字段,只有用户的手机号,并且这些系统在使用我们时,也希望我们能够直接提供“手机号” => 字段的功能。这种情况下,我们对 driver_id => 手机号建立了一种映射,用 driver_id 来查询手机号可以理解为另外一个独立的特征。这个场景就变成了特征之间彼此的依赖问题。但这样的设计将我们最早的设计完全的破坏了,在存储、获取特征时,我们最初的设计可以理解为只有两层的树,如下图:
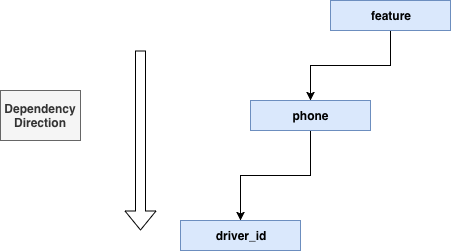
有了特征依赖之后,就没这么简单了,整个树变为了更复杂的结构:
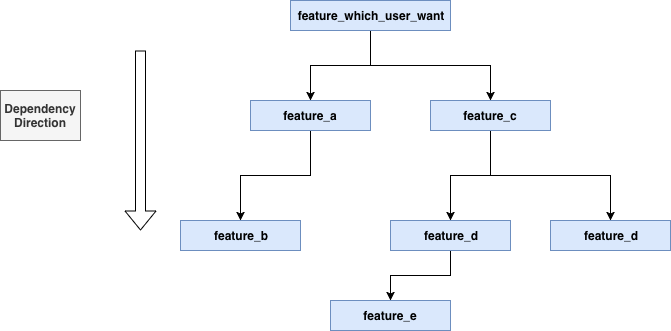
这时候对特征求值(get)会变为 N 棵树从叶子到根部的求值过程,比如下面这样:
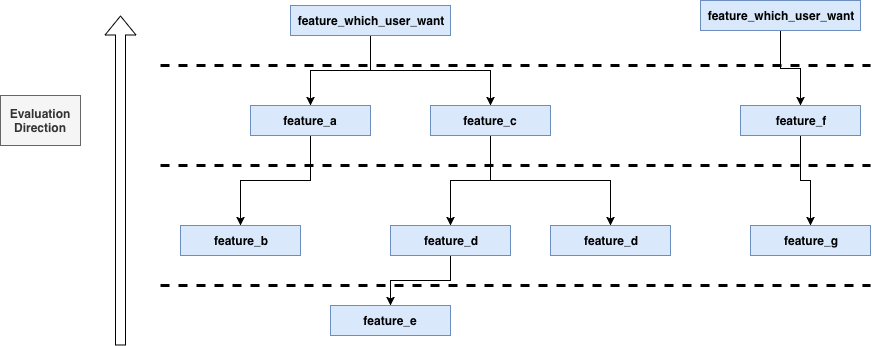
如果我们要对根部的 2 个元素进行求值,那么可以先对所有的叶子节点求值,然后对依赖叶子节点的节点求值,然后一层层向上,直到根部节点全部求值完成,即可将值返回给业务。如果是 set 流程也类似。这实质上是一个拓补排序的场景。
使用拓补排序,可以将拓补序一致的特征获取过程进行合并,减轻存储压力。合并后,如果所有特征都在相同存储中(且可合并的话),访存次数为最高的树的高度。但我们没有采用拓补排序,使用了上图这种逐层求值的方式。因为实现相对更简单,而且总的访存次数与拓补序是一致的。
做到这个地步,大部分的业务需求都可以比较方便地解决了。七八个月边接业务边迭代,最后的结果还是不错的。
当然,这个系统依然存在一些问题。前面说到我们的系统有一些数据是从 MQ 中来的,这套系统能够解决的是一些没有上下文依赖的计算流程。如果有上下文依赖怎么办呢?例如一个订单,整个订单的生命周期,事件的时间跨度会持续很长时间,甚至跨天,那么这套模型就很难在订单中止的时候对其进行计算。
接入到 MQ 之后,我们知道,现代的 MQ 会有很多问题,如果没有提供事务消息的话,首先上游和 MQ 之间的链路就会变成一条不稳定的链路。即使消息稳定地到达了 MQ,在 MQ 中同一订单的事件也可能是乱序的,除非在 MQ 中根据订单 ID 进行了 hash,但这个也不太现实,因为订单相关的数据并没有明确的 schema,可能每条订单事件的 order_id 都不在同样的数据层级。要求 MQ 帮你擦这个屁股,那显然是不可能的。Out-Of-Order 是在异步场景下必然需要解决的问题,目前我们的系统是难以解决这样的问题的。另一方面,Exactly-Once 的语义对于我们来说也很难保证,虽然我们可以用 redis 中的 lock 来实现消息去重,但写 redis 和写持久化 KV 的两步操作并不能保证 atomic。所以也存在下面这种可能性:
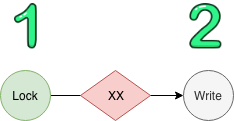
lock 成功之后程序 crash,那么之后写永远不成功,这条数据就永远地丢失了。所幸的是目前计数需求还没有需要严格一致的场景,所以从业务上来讲暂时还可以接受。
可以看到,我们所做的特征系统实质上可以理解为:
- 存储管理
- 外部代理
- 流式计算
几种系统的融合系统,我们的系统的职责在前两者上做得还算不错,用统一的模型把大部分的业务场景都进行了囊括。但流式计算方面,目前的模型并不合格,如果需要保证数据计算的绝对准确。则需要引入更为专业的流式计算系统。
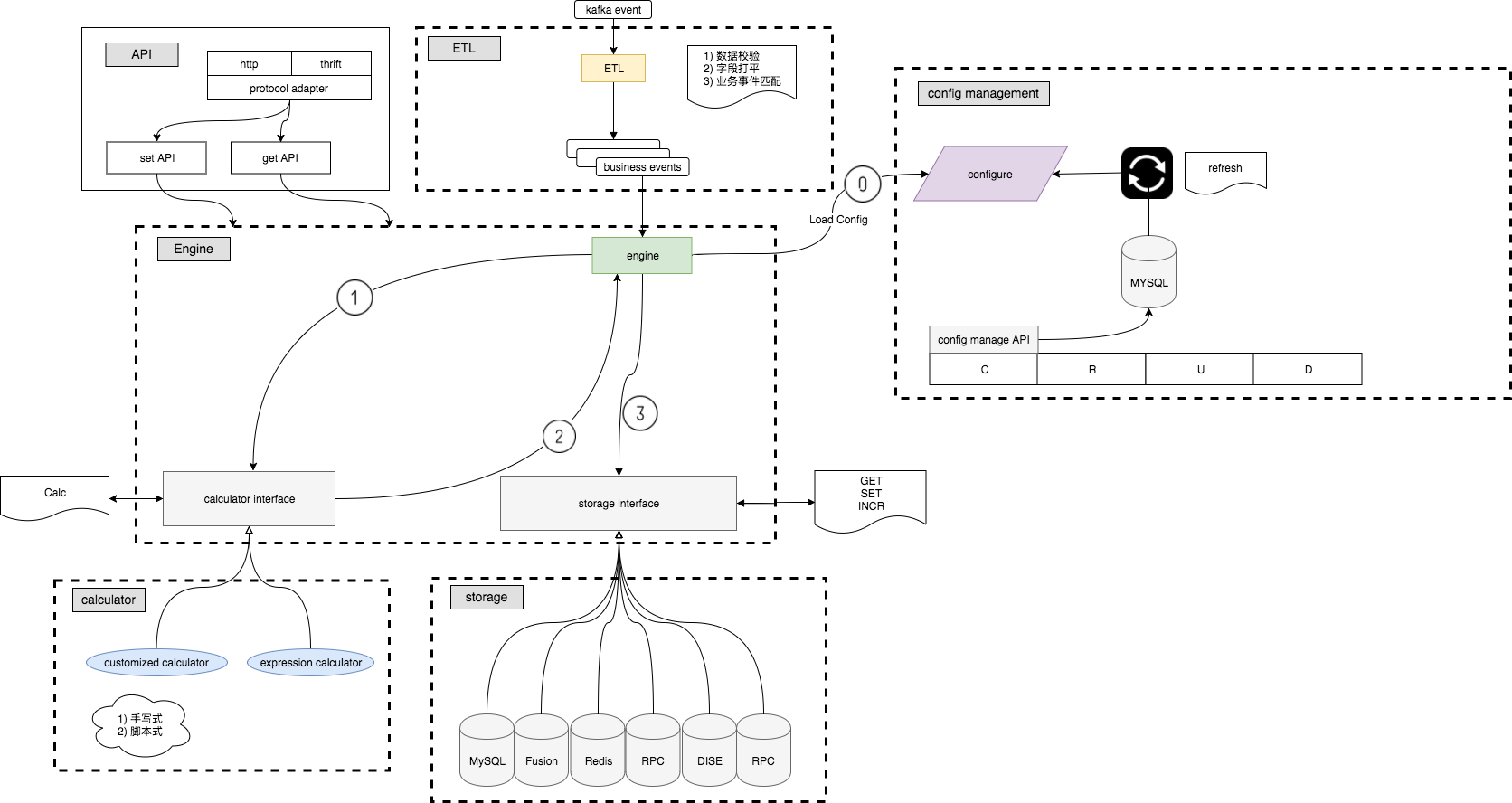
最后,放上一张我们的特征系统的全貌: