内网使用服务发现后,服务与其它服务的实例之间使用一条 TCP 长连接进行通信。这种情况下常见的做法是按照 registry 下发的 host:port 列表来直接建连。
简单来说就是下图这样:
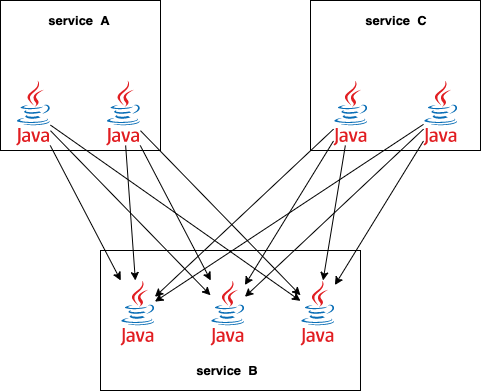
每一个服务实例都需要和它依赖的服务的每一个实例都把连接给建上。如果各个服务的规模不大,这样没什么问题。
互联网公司的核心服务规模都比较大,几千/万台机器(或几千/万个实例)的单一服务并不少见,这时候 client 要和所有 server 实例建连,会导致 client 端的 conn pool 里有大量连接,当然,server 端自然也少不了,这么多连接可能会产生一些问题:
- 活跃的连接管理需要使用连接池,依赖 5~6 个大服务就得建出几万条连接来,如果是在 Go 里,那我们就得有一堆 goroutine 了
- 同理,client 端的连接和 server 端都是对应的,server 端也好不到哪里去
- 连接保活需要收发应用层心跳以应对网络的异常情况,这也是有成本的,极端情况下可能服务没有请求的前提下,心跳请求就消耗了 40% 的 CPU
如果让我们自己去设计一个新的方案,挑选一些实例来建连的话,还是有点难的,这里面要考虑:
- 连接分布应该均衡,不能这个实例 10 条,那个 199 条
- server 和 client 上下线,不能造成大量的连接重建和迁移
- 连接要够用,不能影响客户端
Google 的 subset 算法
好在 Google 爸爸给我们提供了一个解决方案:subsetting。当然,SRE 书里是先说了随机的 subset 不可以,这里的算法被称为 deterministic subsetting:
func Subset(backends []string, clientID, subsetSize int) []string {
subsetCount := len(backends) / subsetSize
// Group clients into rounds; each round uses the same shuffled list:
round := clientID / subsetCount
r := rand.New(rand.NewSource(int64(round)))
r.Shuffle(len(backends), func(i, j int) { backends[i], backends[j] = backends[j], backends[i] })
// The subset id corresponding to the current client:
subsetID := clientID % subsetCount
start := subsetID * subsetSize
return backends[start : start+subsetSize]
}
抄作业有点丢人,我们还是管这个叫借鉴业界先进经验好了。算法非常的短,不过需要还是需要解释清楚。
入参:backends 指的是你的 server 端列表,client_id 我们可以给 client 分配一个 id,subsetSize 其实就是你的 client 端的连接量需求,也就是我一个 client 端对应的一个外部依赖,建立多少条连接合适,那么最终也就会从这个大 backends 列表中挑出 subsetSize 个项来。
为什么是均匀的
首先,shuffle 算法保证在 round 一致的情况下,backend 的排列一定是一致的。
因为每个实例拥有从 0 开始的连续唯一的自增 id,且计算过程能够保证每个 round 内所有实例拿到的服务列表的排列一致,因此在同一个 round 内的 client 会分别 backend 排列的不同部分的切片作为选中的后端服务来建连。
Round 0: [0, 6, 3, 5, 1, 7, 11, 9, 2, 4, 8, 10]
Round 1: [8, 11, 4, 0, 5, 6, 10, 3, 2, 7, 9, 1]
Round 2: [8, 3, 7, 2, 1, 4, 9, 10, 6, 5, 0, 11]
上面是不同 round 的 backends 排列,如果我的 client id 计算出的 round 是 0,且这个 client 需要 4 条连接,则说明每个 round 可以分为 3 组,client id % 3 = 0,那么这个 client 则应该选择 [0, 6, 3, 5] 这 4 条连接。如果 client id % 3 = 2,则应该选择 [2, 4, 8, 10] 这 4 条连接。
Round 0: [0, 6, 3, 5, 1, 7, 11, 9, 2, 4, 8, 10]
第 0 组 第 1 组 第 2 组
比较好理解,只要我的 client id 能保证连续,那么 client 打到后端的连接则一定是均匀的。
上下线的情况
client 上下线
client 上下线用滚动更新的方式,并不会影响其它 client 的连接分布,所以每个 client 下线时,只是对应的后端少了一些连接,暂时会导致某些 backend 的连接比其它 backend 少 1。
上线 client 从尾部开始,client id 依然是递增的,按照该算法,这些 client 会继续排在其它 client 后面,一个 round 一个 round 地将连接分布在后端服务上,也必然是均匀的。
server 上下线
与 client 上下线类似,server 的滚动升级和上下线也是不会有大影响的,因为每个 server 会随机地分布在不同 client 的子集中,不会因为该 server 上下线,导致计算结果有大变化。
这个算法的问题
这个算法看上去比较完美,但是问题在于它需要一些前提。
每个服务都能被分配从 0 到 N 的连续唯一 id,这一点在没有外部依赖的情况下比较难做到。绑定了外部基础设施的方案又可能比较难推广。比如 k8s 的 statefulset,也没办法强制所有服务都使用?
服务下线时,并不一定能保证下线的服务的 client id 是连续的,这样就总是可以构造出一些极端情况,在拿到一些 client 之后,让某台 backend 的连接数变为 0。
现在大规模的服务节点很多,有些批量发布一次性发布几百个节点,Google 的这个算法说一般 100 条连接(We typically use a subset size of 20 to 100 backend tasks)就够了?如果正好批量发布的后端都被同一个 client 选中了,那这个 client 就废掉了。
client 服务是需要知道 backends 的 id 的,否则当 backend 发生下线时,会导致 client 端的连接重新排部。
因此想要应用该算法,我们还是要进行一些特殊情况的考量和处理。
参考资料:
