经常翻阅微服务材料的话,总会碰到 microservices.io 这个网站,总结了微服务方方面面的设计模式。网站的作者是 Chris Richardson。
这些相关的经验在 2018 年成为了《Microservices Patterns》这本书,并且 2019 年引进国内。当时我第一时间购入了这本书,不过那时候很懒,所以没看完。最近在准备分享内容的时候又翻到了这本书,这次完整地读完了一遍。感觉应该是目前微服务领域最好的一本书了。另一本《Building Microservices》也不错,不过内容还是稍微单薄了一些。
这本书为我们提供了宏观上俯瞰微服务整个生态的大图,比如:
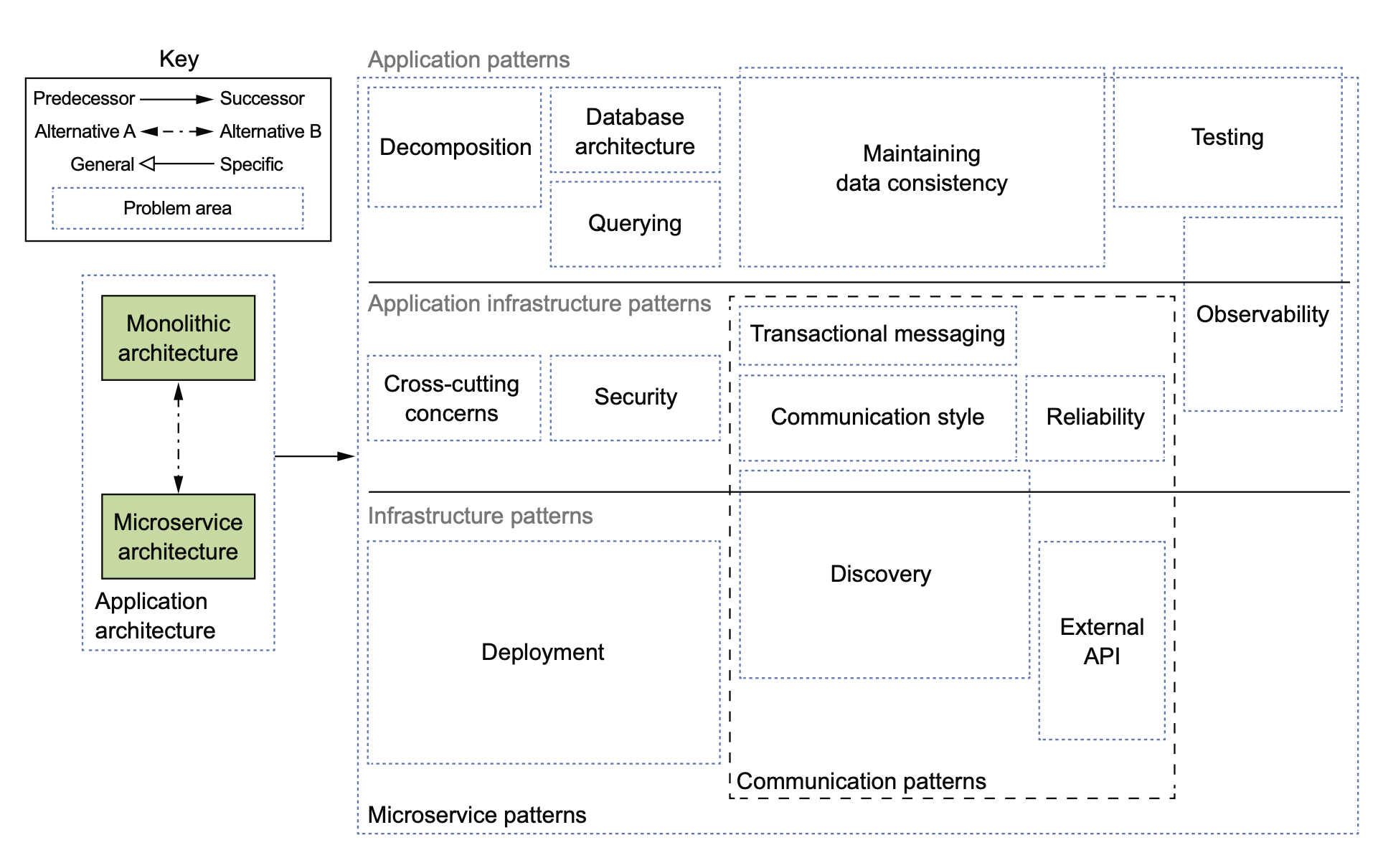
当然,18 年的时候,service mesh 之类的东西还没有太火,所以后来在网站上有个更新的版本:
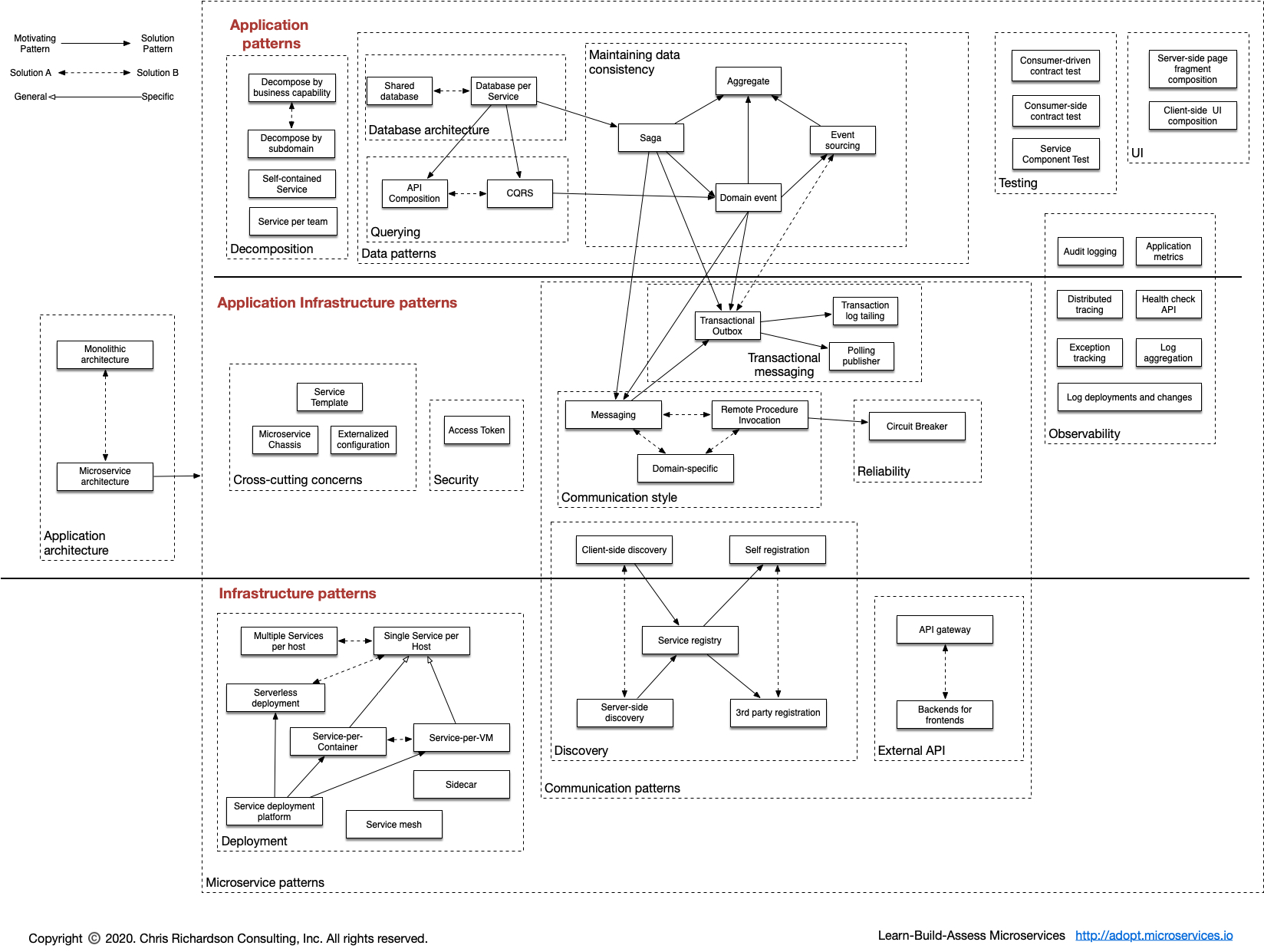
个人很喜欢这种大图,不管什么领域,我只要照着图去一点一点填坑就行了,没有这样的图,总觉得是在望不见头的技术森林里兜兜转转,找不到北。
下面简单写一写我对这本书的总结,里面 saga 和测试的部分我就先省略了。
单体服务的困境
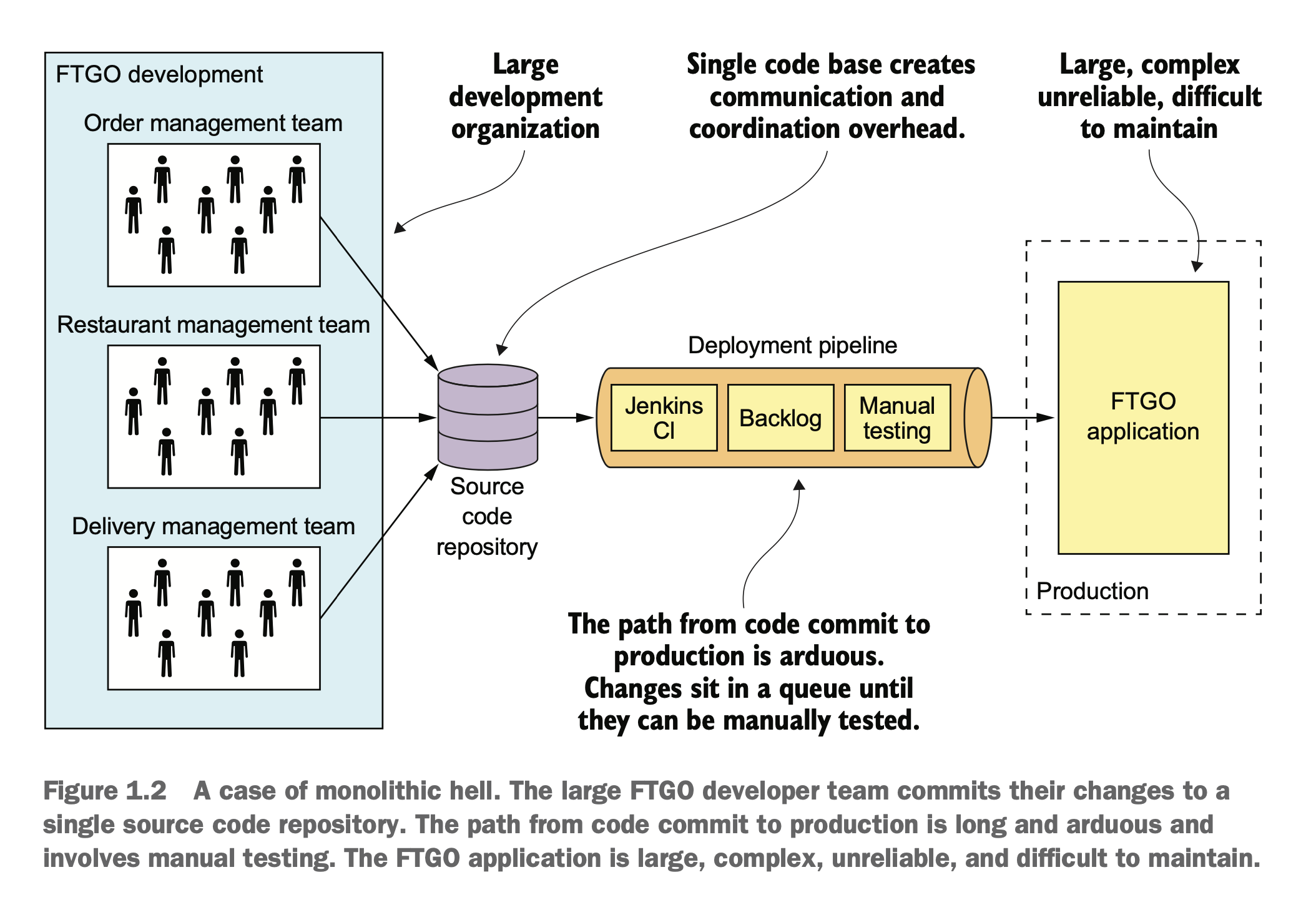
在单体时代,大家在一个仓库里开发,代码冲突解决起来很麻烦,上线的 CI/CD pipeline 也是等待到死。
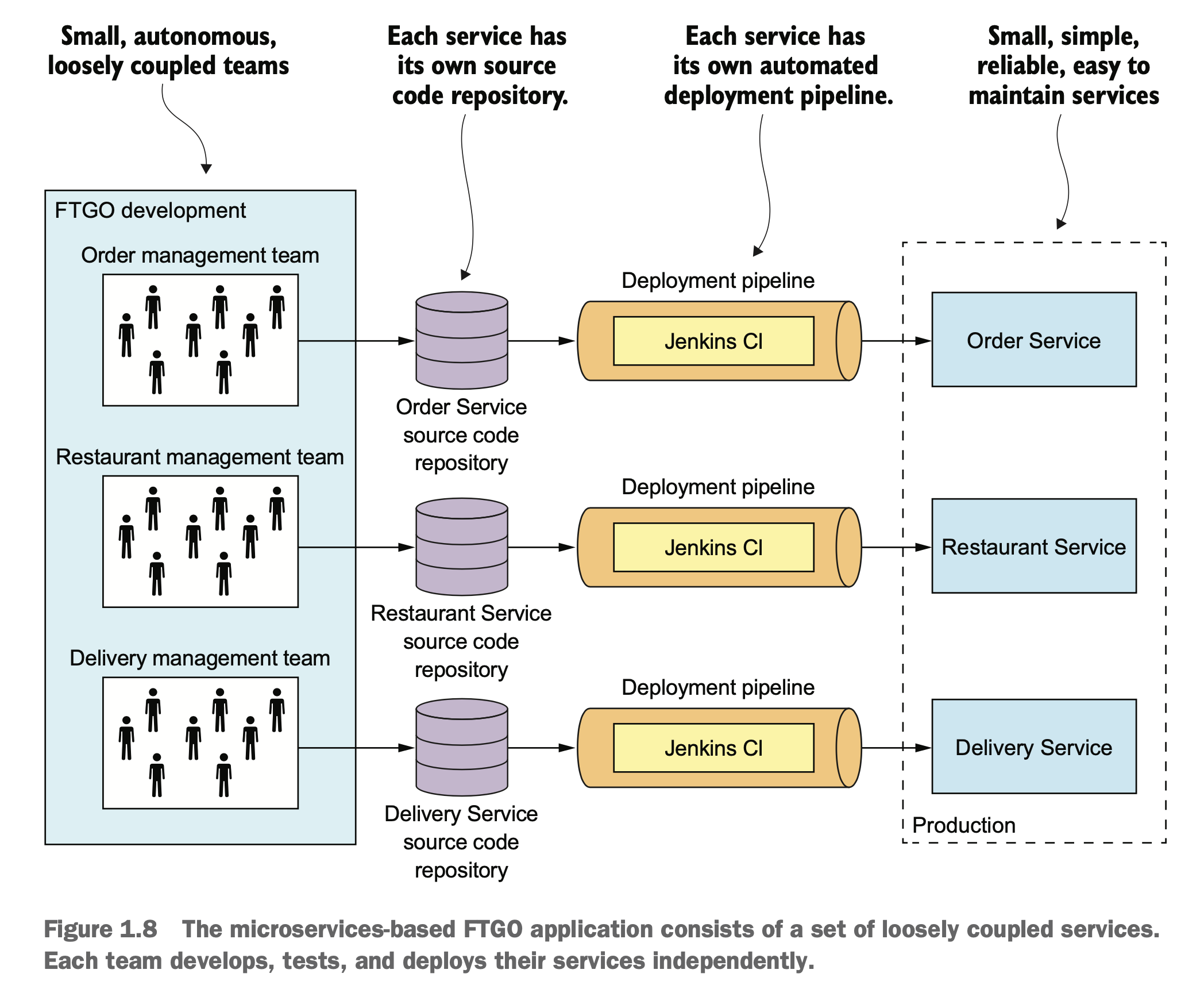
拆分了以后,至少大家有各自的代码库,各自的上线流程,各自的线上服务。这样上线不打架了,上线以后也可以自己玩自己的灰度流程,一般不会互相影响。
服务拆分
虽然说是拆了,不过拆分也是要讲究方法的。
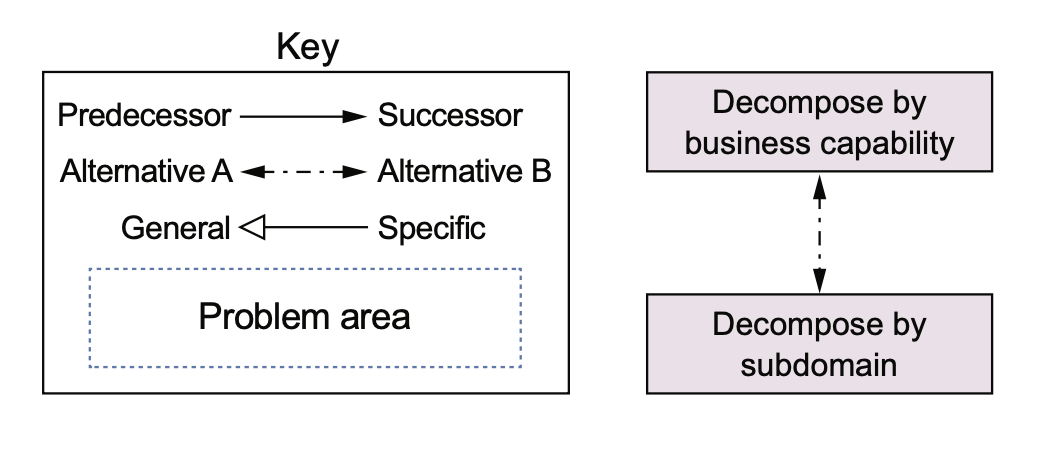
书里提供了两种思路,一种是按照业务/商业能力拆分,一种是按照 DDD 中的 sub domain 拆分。
- 供应商管理
- 送餐员信息管理
- 餐馆信息管理:管理餐馆的订单、营业时间、营业地点
- 消费者管理
- 管理消费者信息
- 订单获取和履行
- 消费者订单管理:让消费者可以创建、管理订单
- 餐馆订单管理:让餐馆可以管理订单的准备过程
- 送餐管理
- 送餐员状态管理:管理可以进行接单操作的送餐员的实时状态
- 配送管理:订单配送追踪
- 会计
- 消费者记账:管理消费者的订单记录
- 餐馆记账:管理餐馆的支付记录
- 配送员记账:管理配送员的收入信息
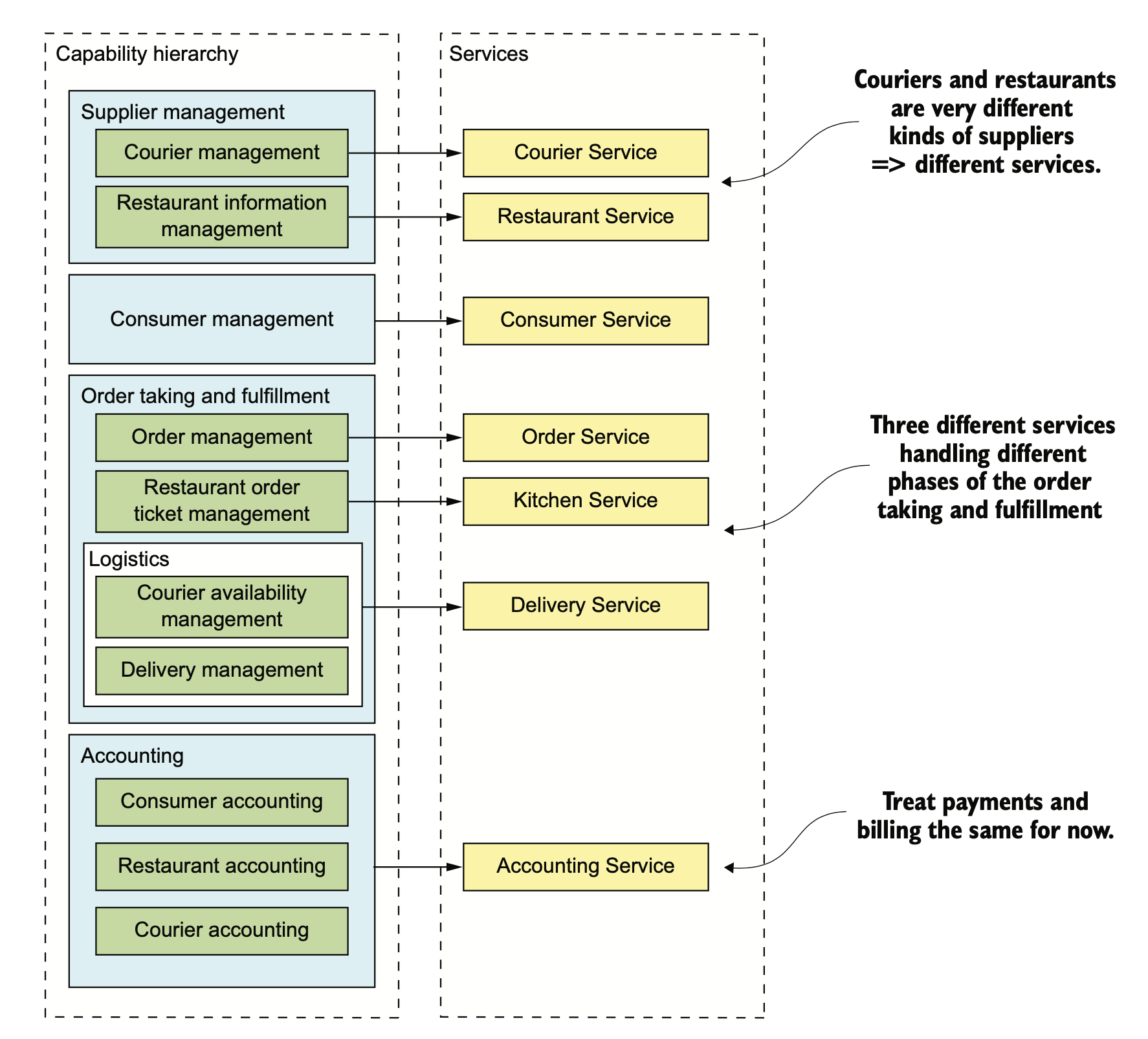
最终大概会形成上面这些服务。
用 DDD 来做分析,其实我们得到的结果也差不多:
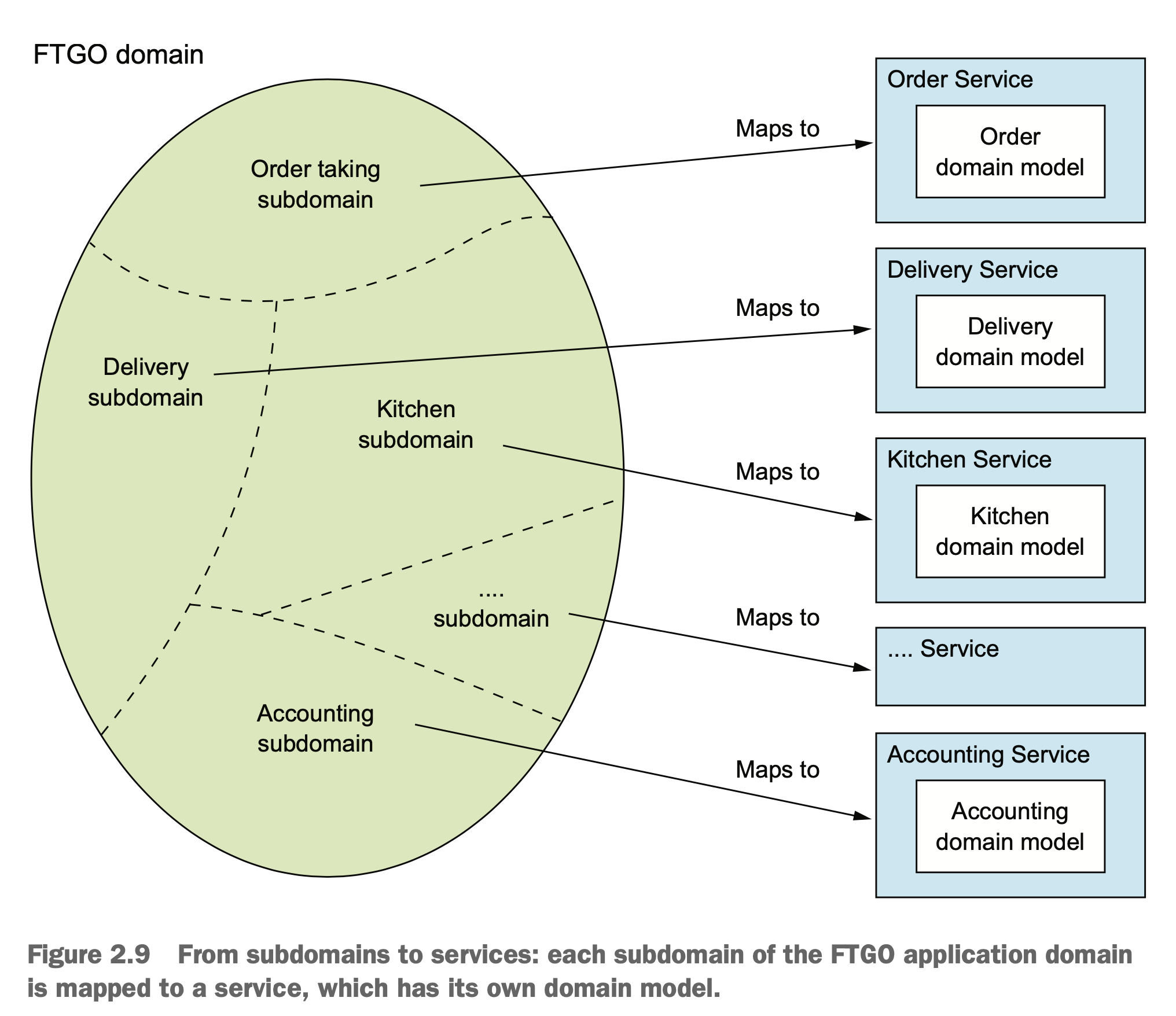
在拆分时,我们还应该用 SOLID 中的 SRP 原则和另外一个闭包原则 CCP(common closure principle) 来进行指导。
在拆分后,也要注意微服务的拆分会额外给我们带来的问题:
- 网络延迟
- 服务间同步通信导致可用性降低
- 在服务间维持数据一致性
- 获取一致的数据视图
- 阻塞拆分的上帝类
服务集成
分布式服务通信大概可以分为 one-to-one 和 one-to-many:

RPC 很好理解,同步的 request/response。异步通信,一种是回调式的 request/response,一种是一对多的 pub/sub。
具体到 RPC 的话,可以使用多种协议和框架:
不过当 API 更新时,应该遵循 semver 的规范进行更新。社区里 gRPC 很多次更新都没有遵守 semver,给它的依赖方都造成了不小的麻烦。感兴趣的同学应该可以搜到一些相关的事件。
不得不说 Google 的程序员也并不是事事靠谱。
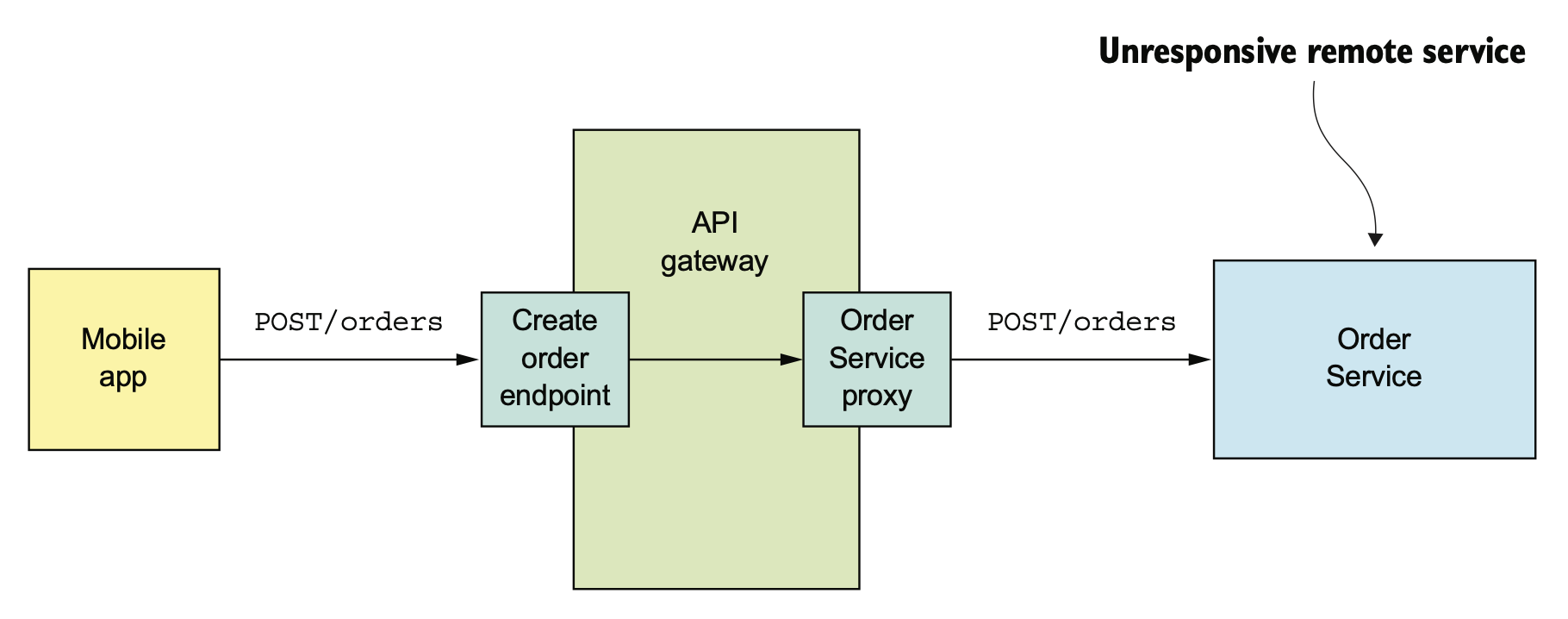
RPC 进行服务集成的时候,要注意不要被某些不稳定的服务慢响应拖死,要注意设置超时,熔断。
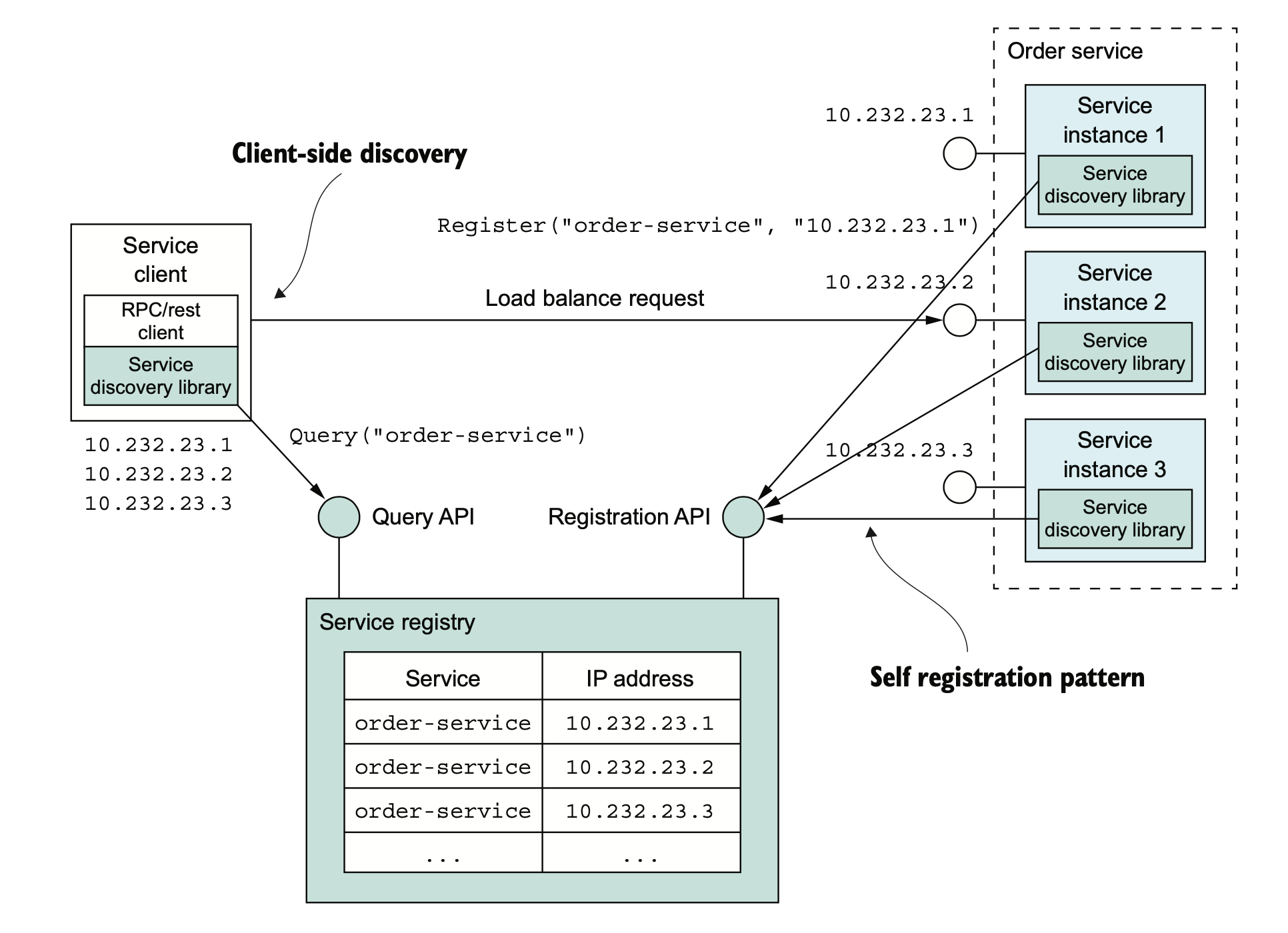
服务与服务之间要能找得到彼此,有两种方式,一种是基于服务注册中心的服务发现。
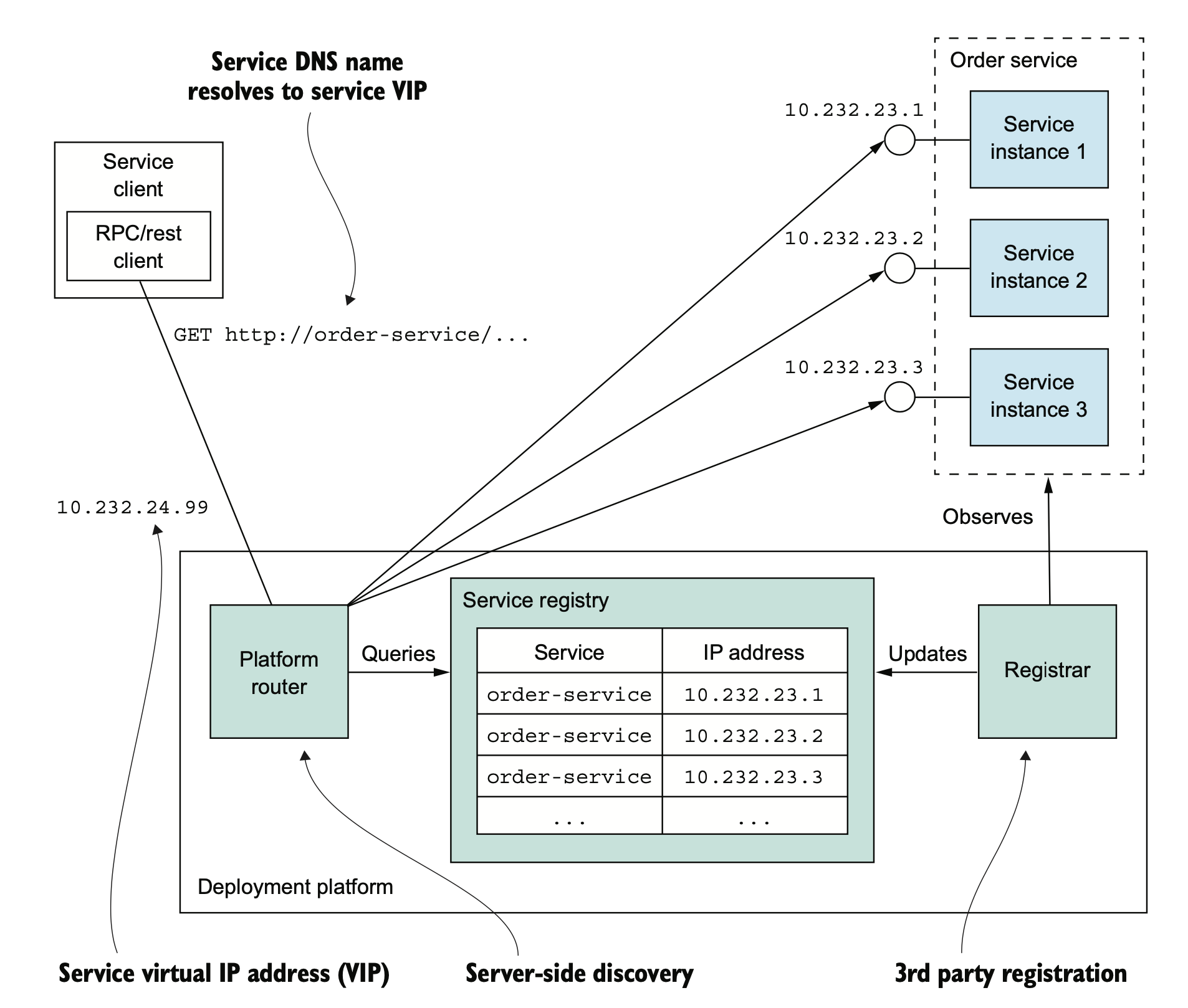
一种是基于 dns 的服务发现。基于 DNS 的现在应该不太多了。
除了 RPC 以外,还可以使用消息来进行服务间的集成。
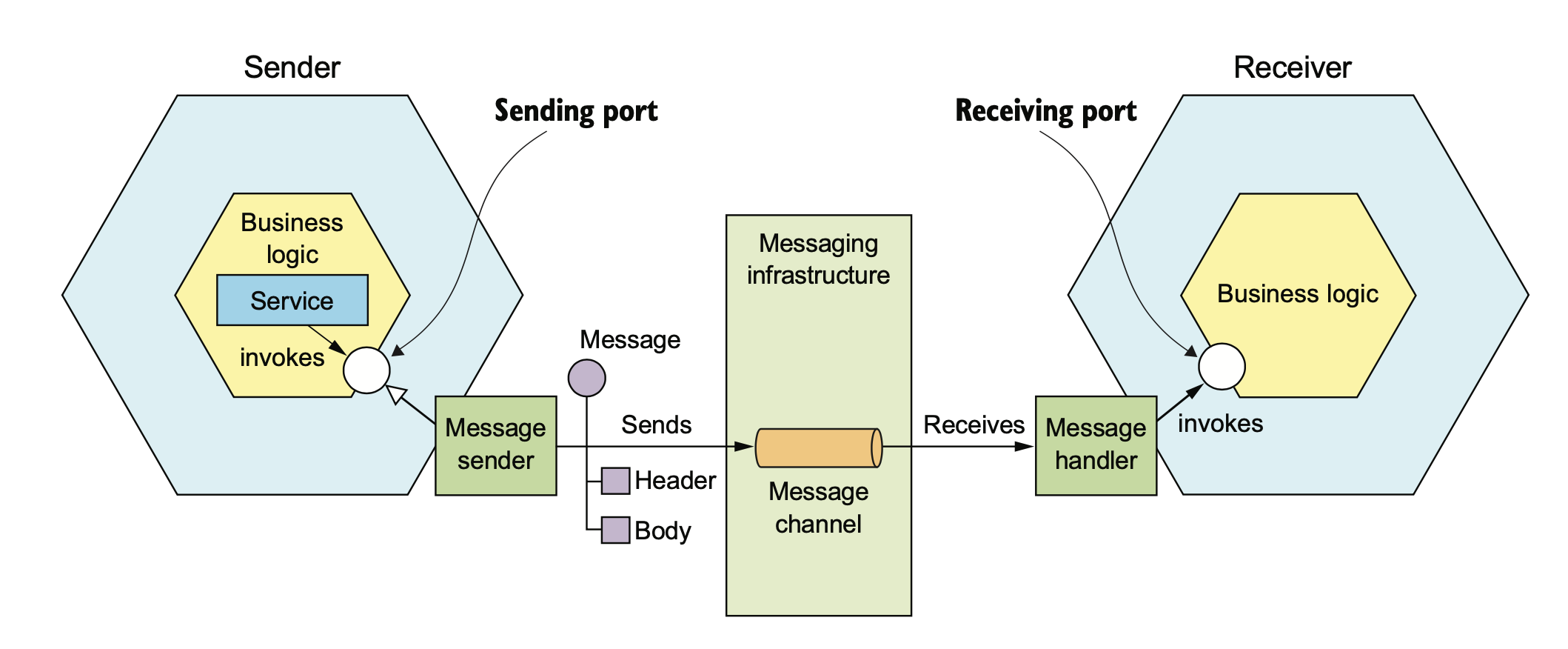
使用 MQ 也可以模拟 RPC 的 request/response,不过这样会使你的服务强依赖于 MQ,如果 MQ 故障,那整个系统随之崩溃。
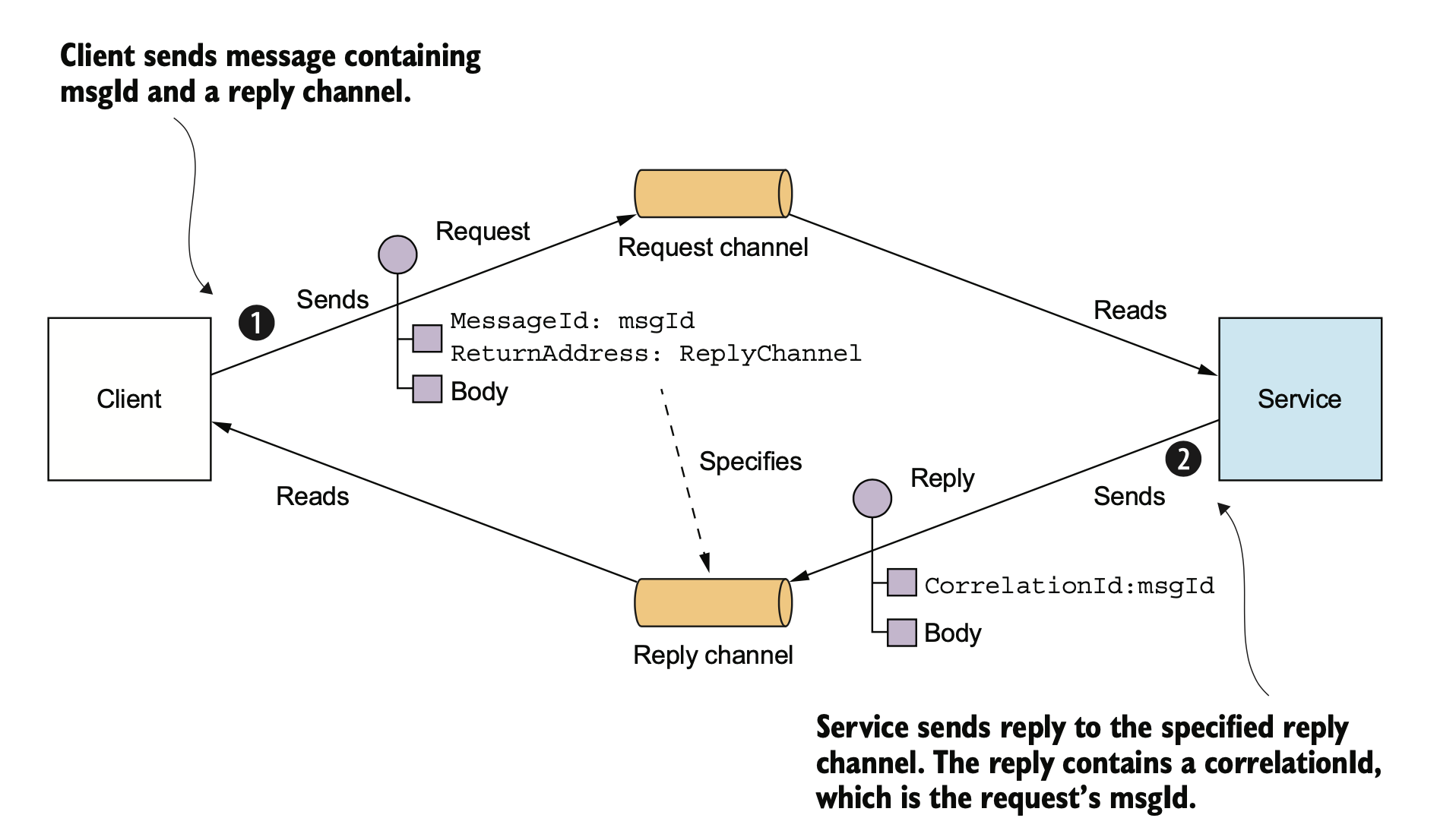
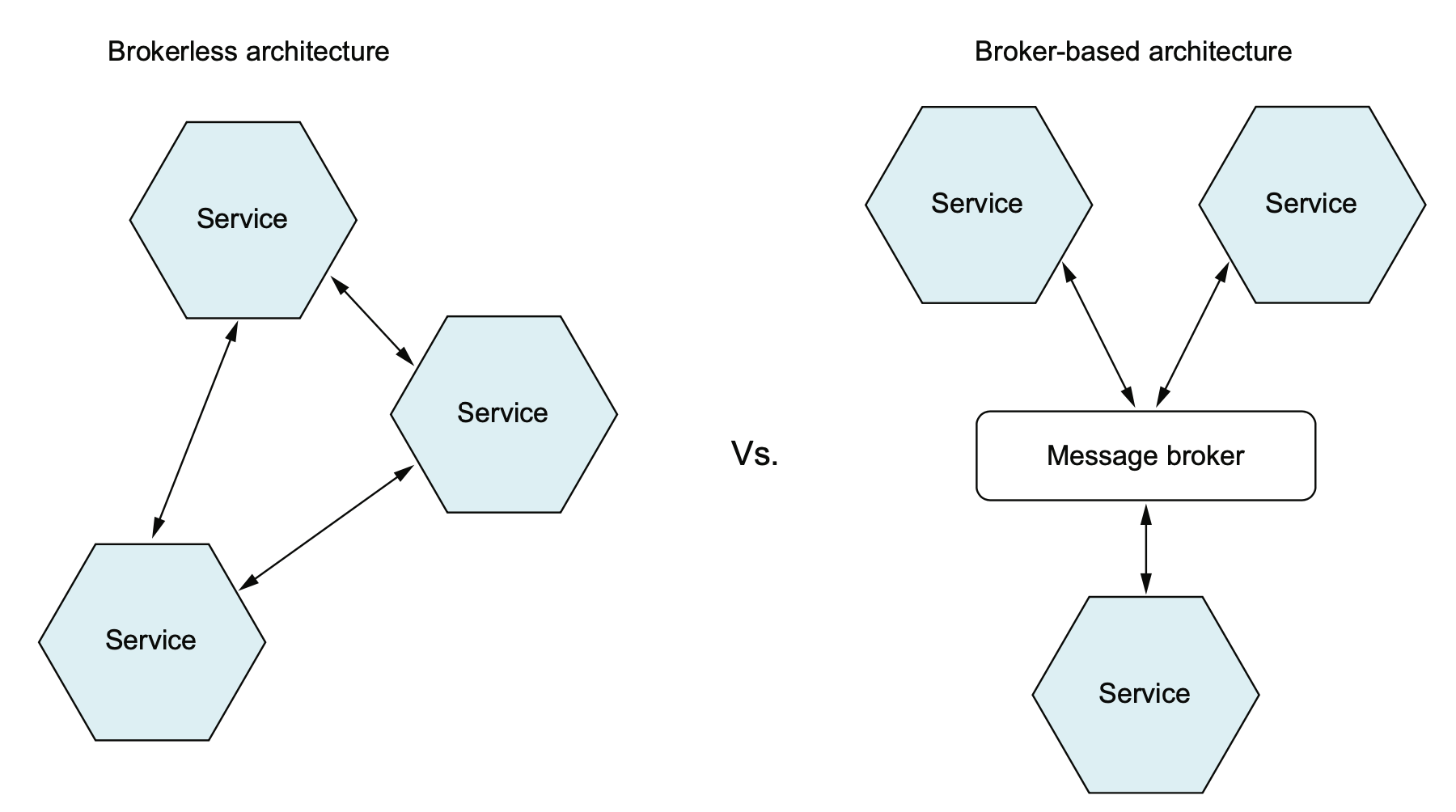
一般我们使用的是 broker-based mq 通信,但也有无 broker 的异步通信,书中这里举了个 ZeroMQ 的例子,之前个人不是很了解,需要再调研一下。
Event Sourcing
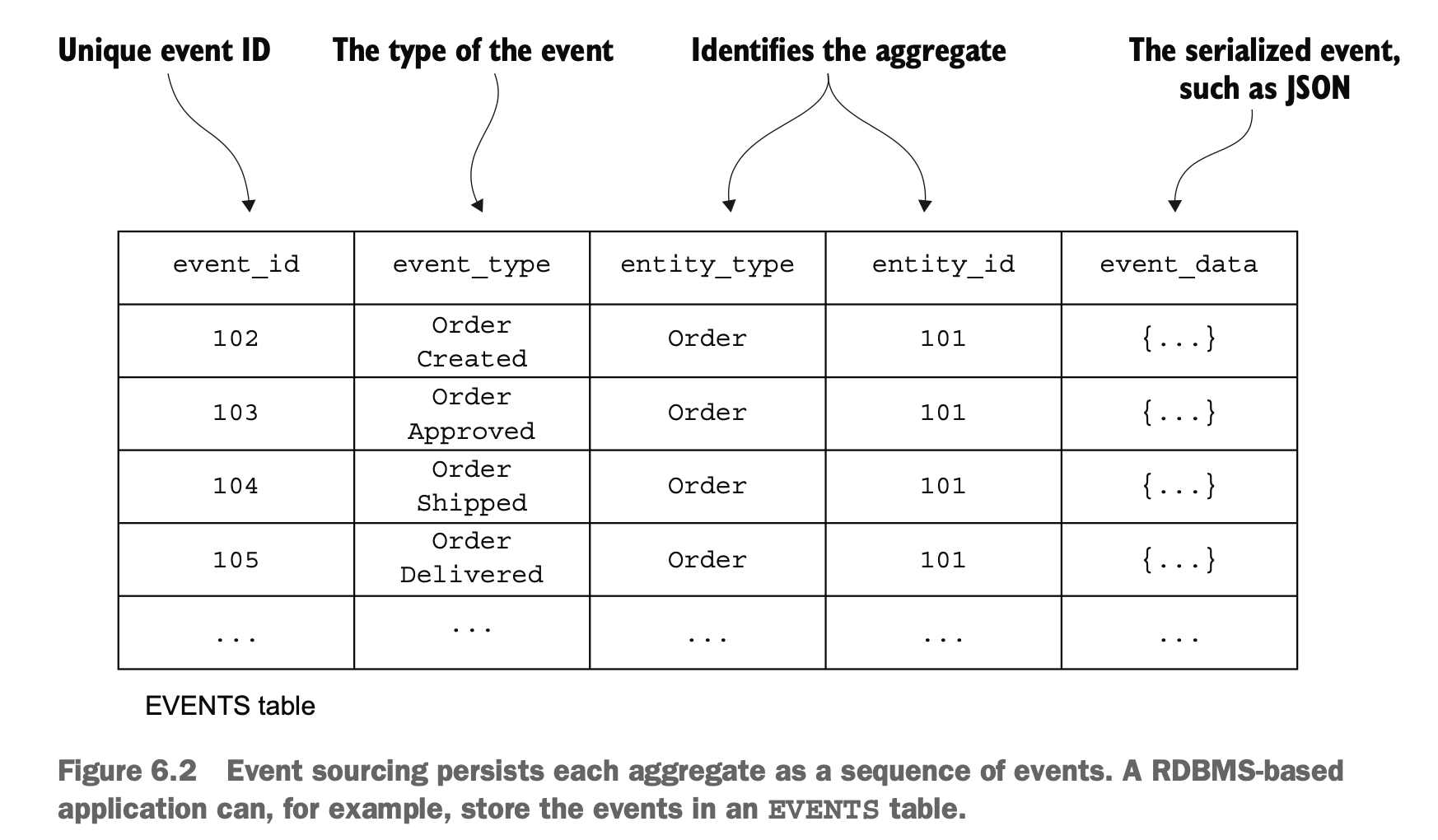
event sourcing 是一种特殊的设计模式,不记录实体的终态,而是记录所有状态修改的事件。然后通过对事件进行计算来得到实体最终的状态。
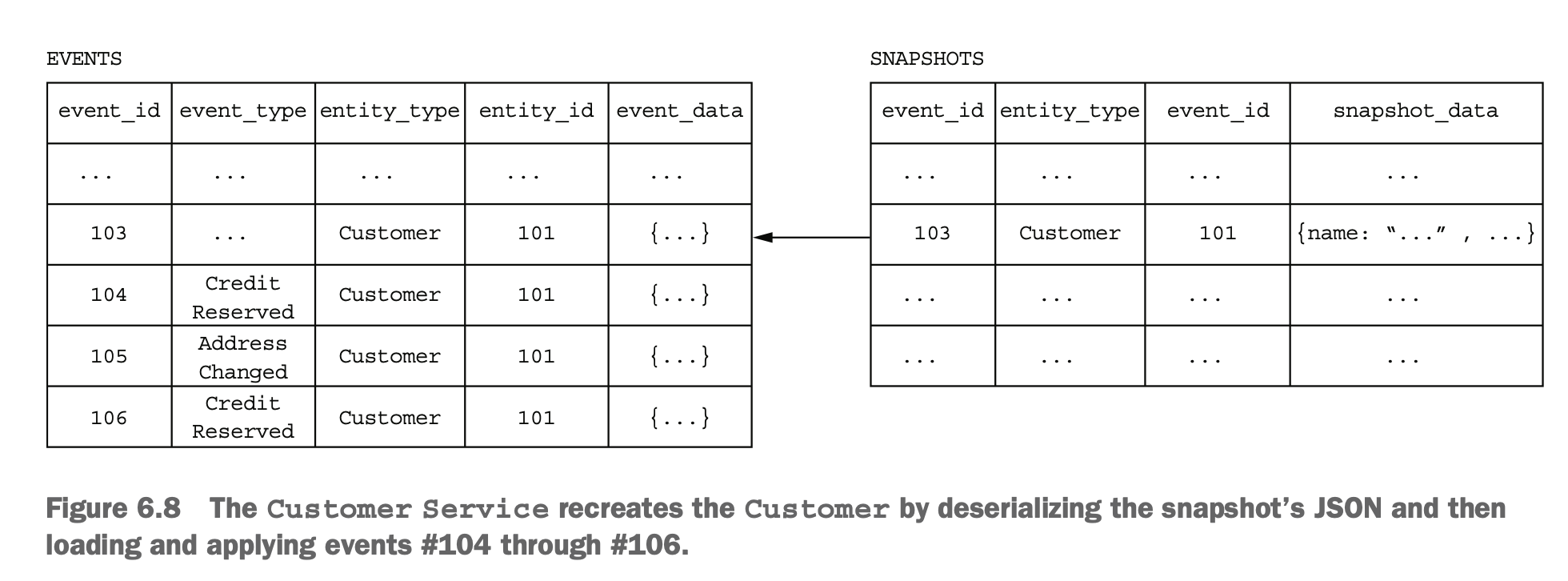
但这样事件累积太多以后会有性能问题,所以可以对一部分历史数据进行计算,得到一个中间的快照,之后的计算在快照的基础上再叠加。
看起来方案很酷,我们在实际工作中也确实在一些下游的计算逻辑中使用过这种设计模式,不过它也是有缺陷的:
- 事件本身结构变化时,新老版本兼容比较难做
- 如果代码中要同时处理新老版本数据,那么升级几次后会非常难维护
- 因为容易追溯,所以删除数据变得非常麻烦,GDPR 类的法规要求用户注销时必须将历史数据删除干净,这对 Event Sourcing 是一个巨大的挑战
在使用异步消息来做解耦的时候,我们也会遇到一些实际的业务问题:
- 这个数据我需要,你能不能在消息里帮我透传一下
- 你重构的时候怎么把这个字段删了,我还要用呢
- 你们原来的状态机变更都有 event,本来有三个,怎么现在变成两个了?
- 你们 API 故障的时候,怎么消息顺序乱了?

这要求我们能有对上游的领域事件进行校验的系统,这里可以参考 Google 的 schema validation 这个项目,之前我在 《MQ 正在变成臭水沟》一文中有详述。这里就不提了。
查询模式
很多查询逻辑其实就是进行 API 的数据组合,这个涉及到需要组合数据的 API 组合器,和数据提供方:
- API 组合器:通过查询数据提供方的服务实现查询操作
- 数据提供方:提供数据
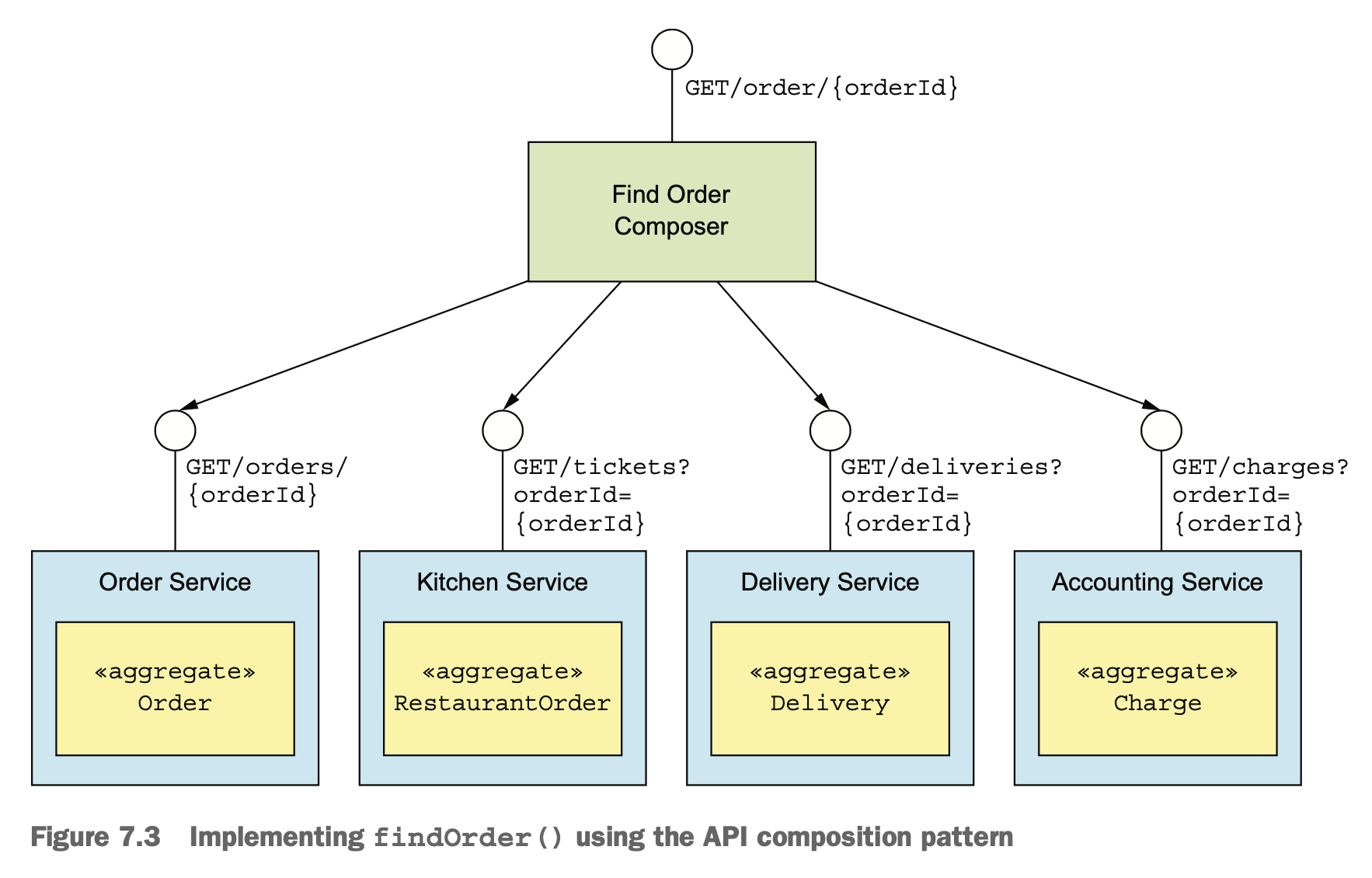
虽然看起来挺简单,写代码的时候,下面这些问题还是难处理:
- 谁来负责拼装这些数据?有时是应用,有时是外部的 API Gateway,难以定立统一的标准,在公司里也经常扯皮
- 增加额外的开销-一个请求要查询很多接口
- 可用性降低-每个服务可用性 99.5%,实际接口可能是 99.5^5=97.5
- 事务数据一致性难保障-需要使用分布式事务框架/使用事务消息和幂等消费
CQRS
业务开发经常自嘲是 CRUD 工程师,在架构设计里,CRUD 的 R 可以单独拆出来,像下面这样。
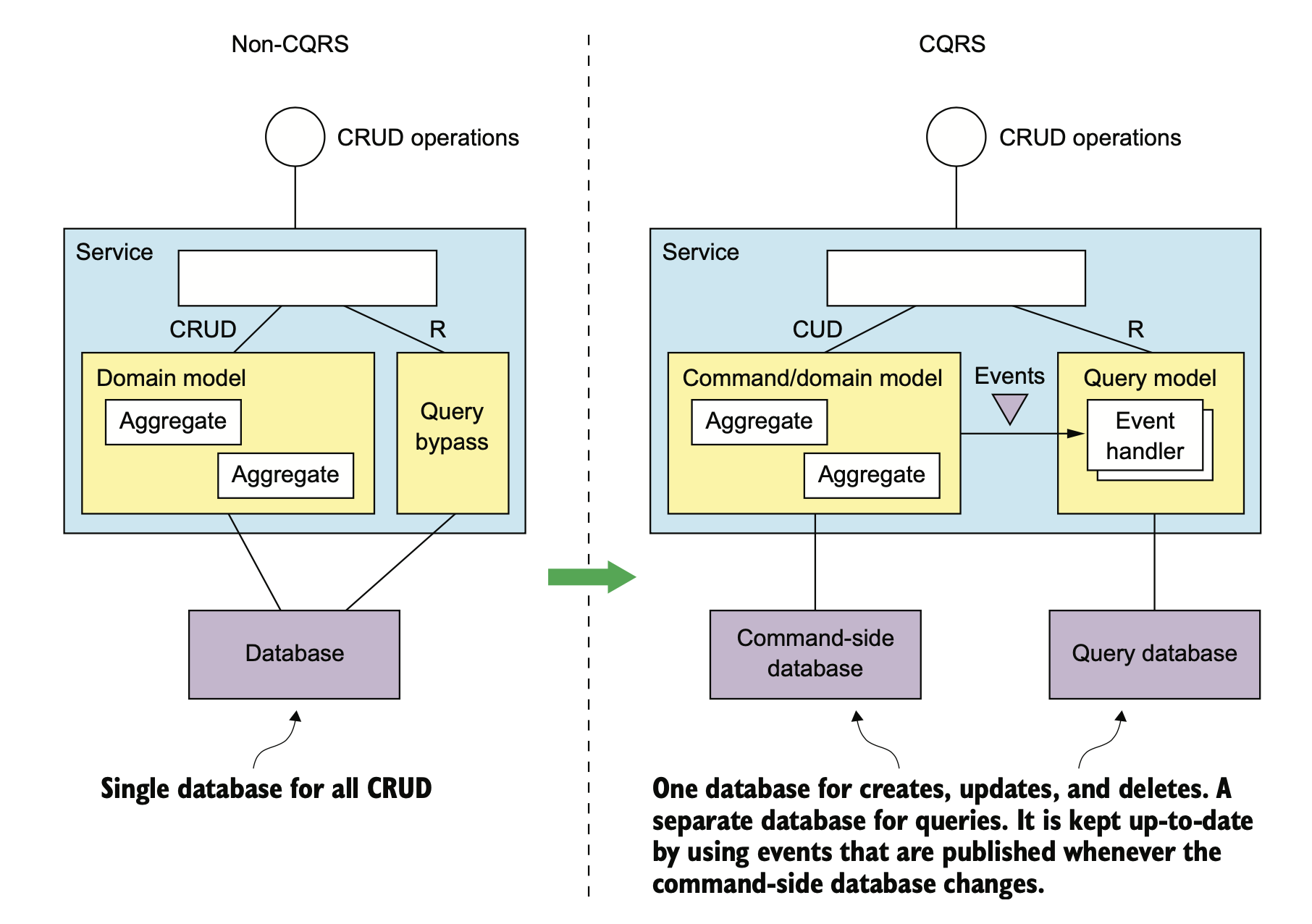
拆出来的好处?互联网大多是写少读多的服务,将关注点分离之后,读服务和写服务的存储可以做异构。
比如写可以是 MySQL,而读则可以是各种非常容易做横向扩展的 NoSQL。碰到检索需求,读还可以是 Elasticsearch。
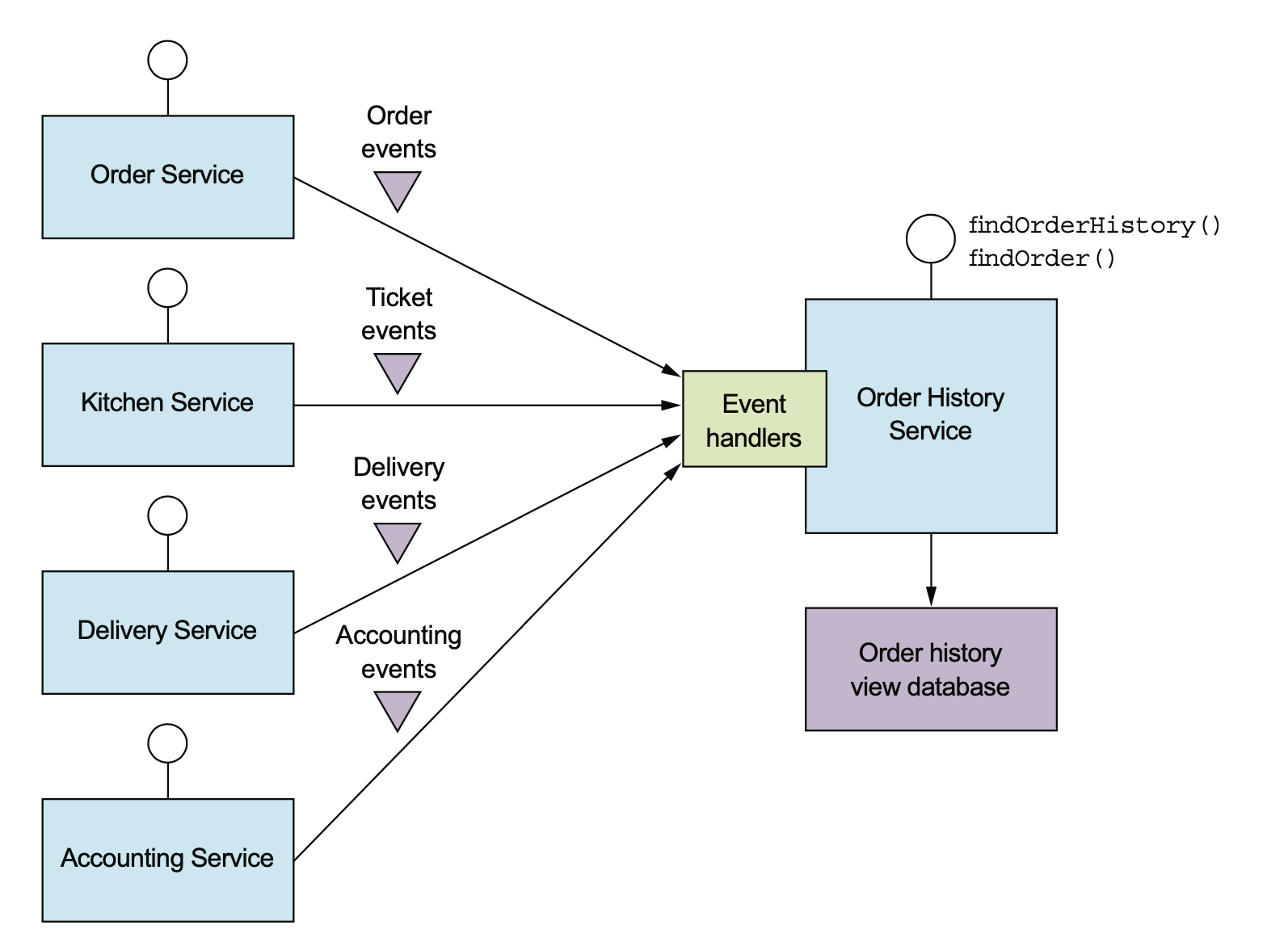
读服务可以订阅写服务的 domain event,也可以是 MySQL 的 binlog。
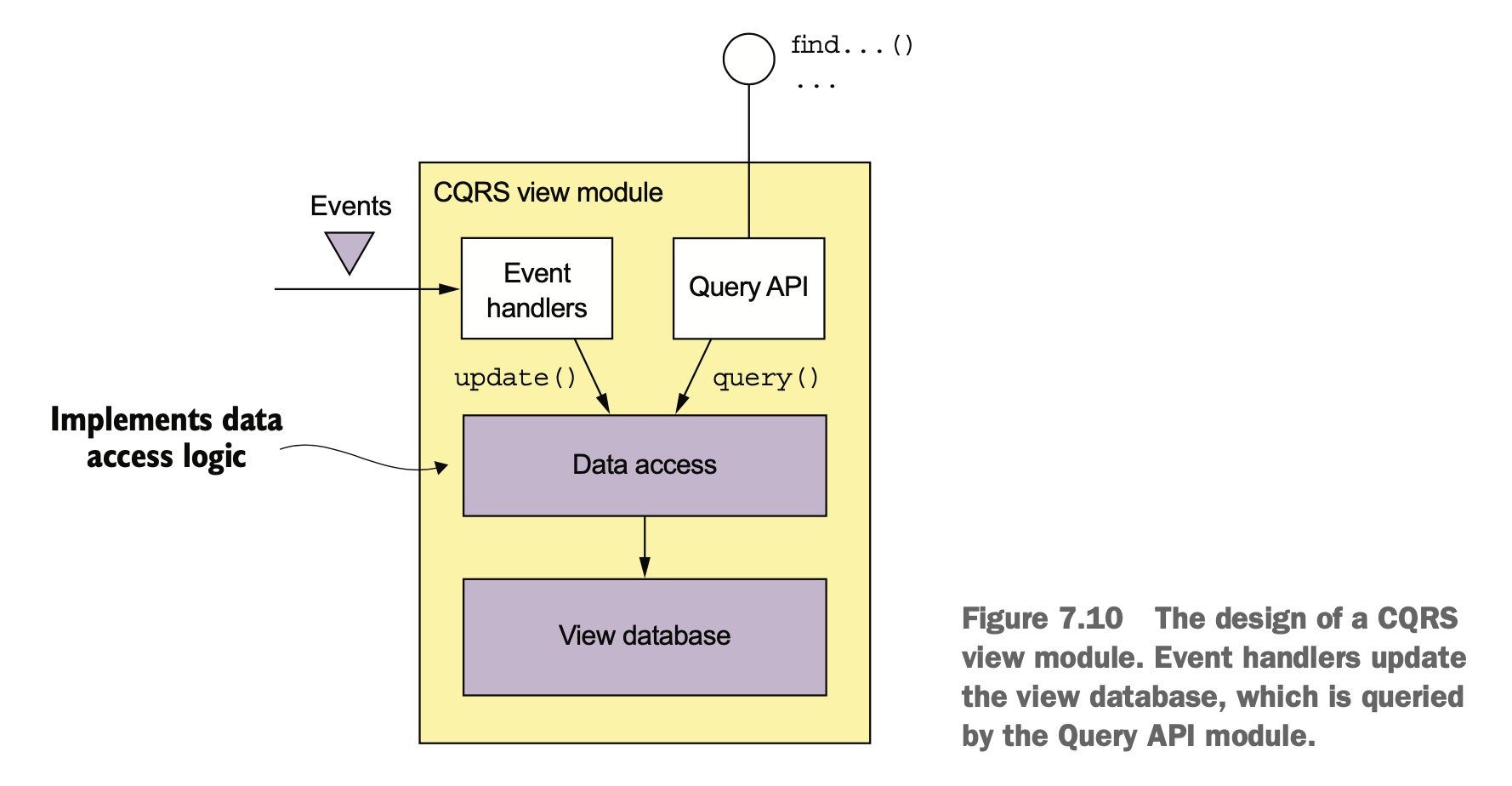
在消费上游数据时,需要根据业务逻辑去判断有些状态机要怎么做处理。这里其实数据上是有耦合的,并不是放个 MQ 和 domain event 就能解耦干净了。
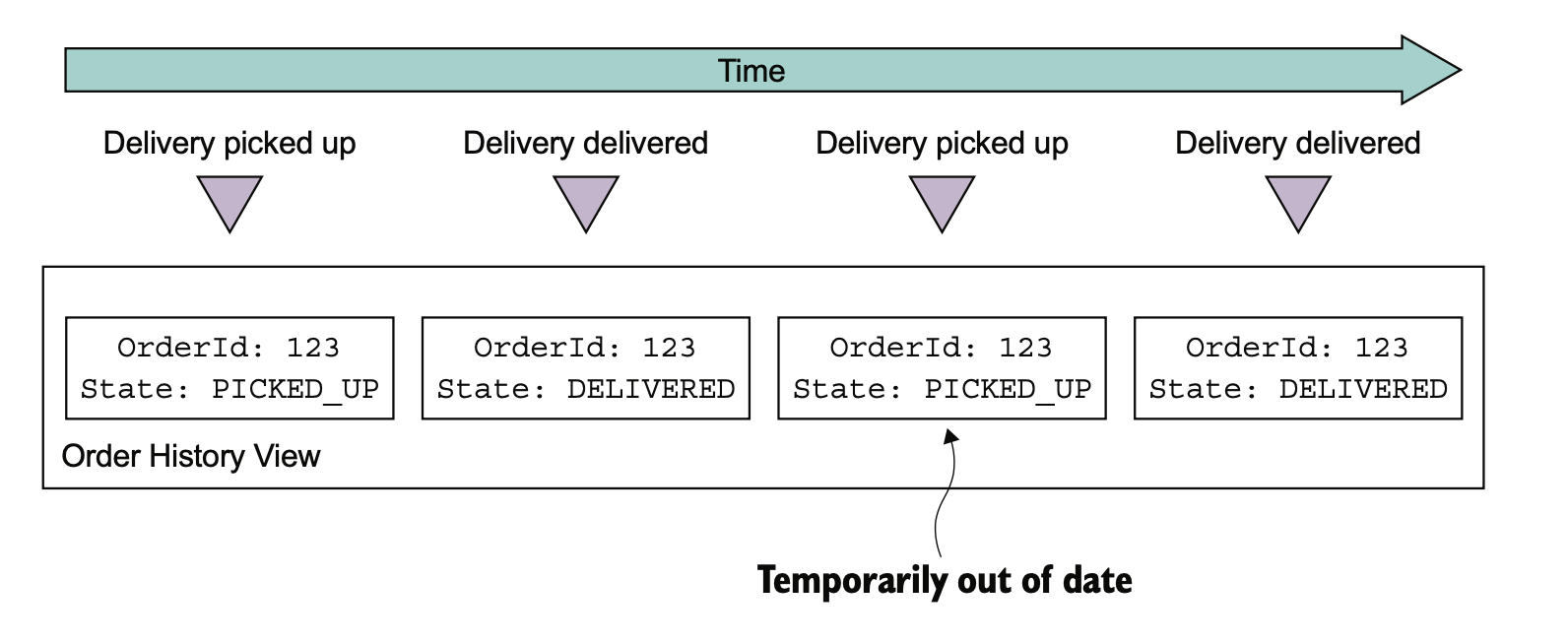
CQRS 的缺点也比较明显:
- 架构复杂
- 数据复制延迟问题
- 查询一致性问题
- 并发更新问题处理
- 幂等问题需要处理
外部 API 模式
现在的互联网公司一般客户端都是多端,web、移动、向第三方开放的 open API。
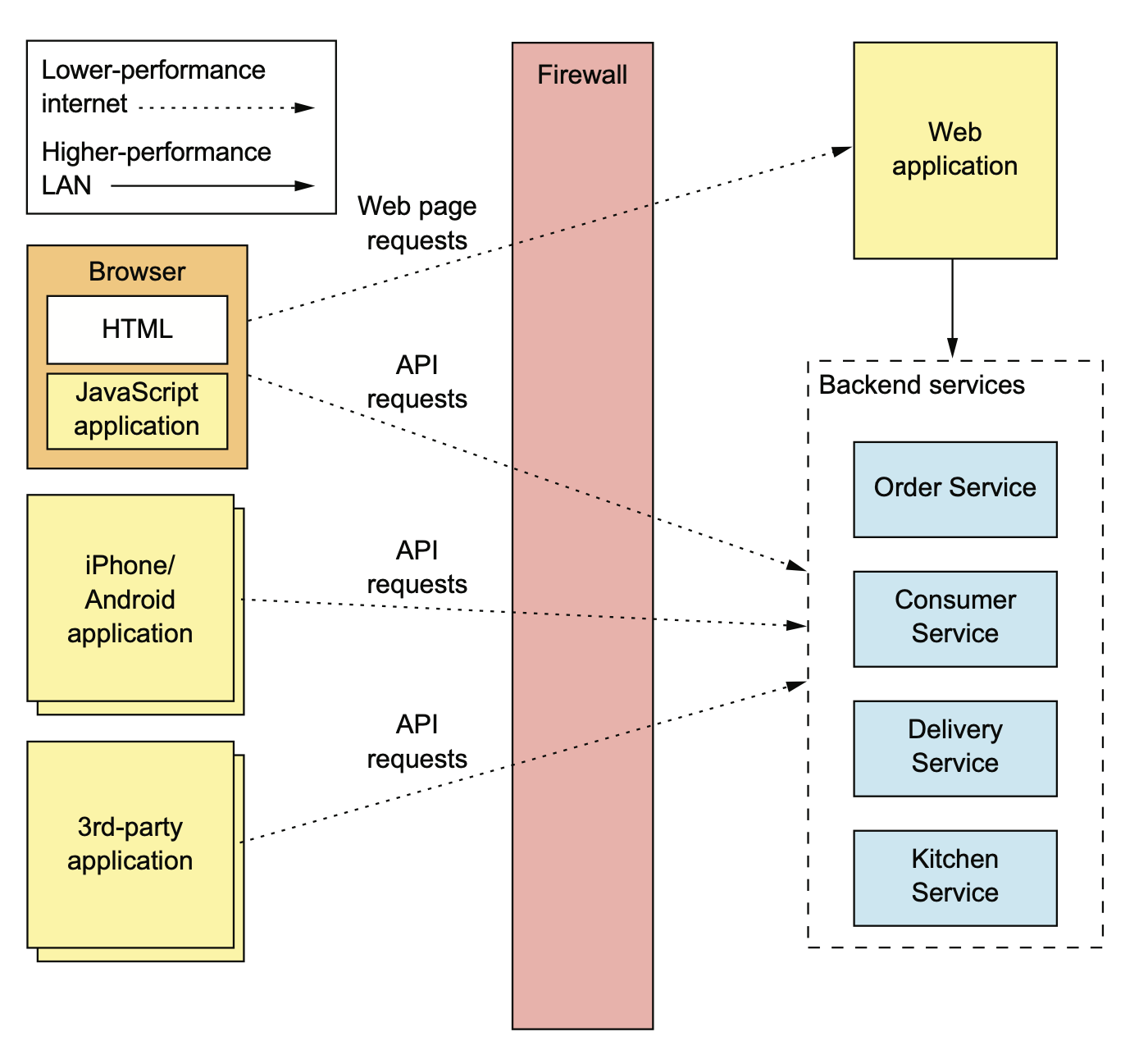
如果我们直接把之前用拆分方法拆出来的这些内部 API 开放出去,那未来内部的 API 想升级就会非常非常地麻烦。
在单体时代,客户端走弱网 internet,只需要一次调用。微服务化以后,如果不做任何优化,那在 internet 这种慢速网络上就需要有多次调用。
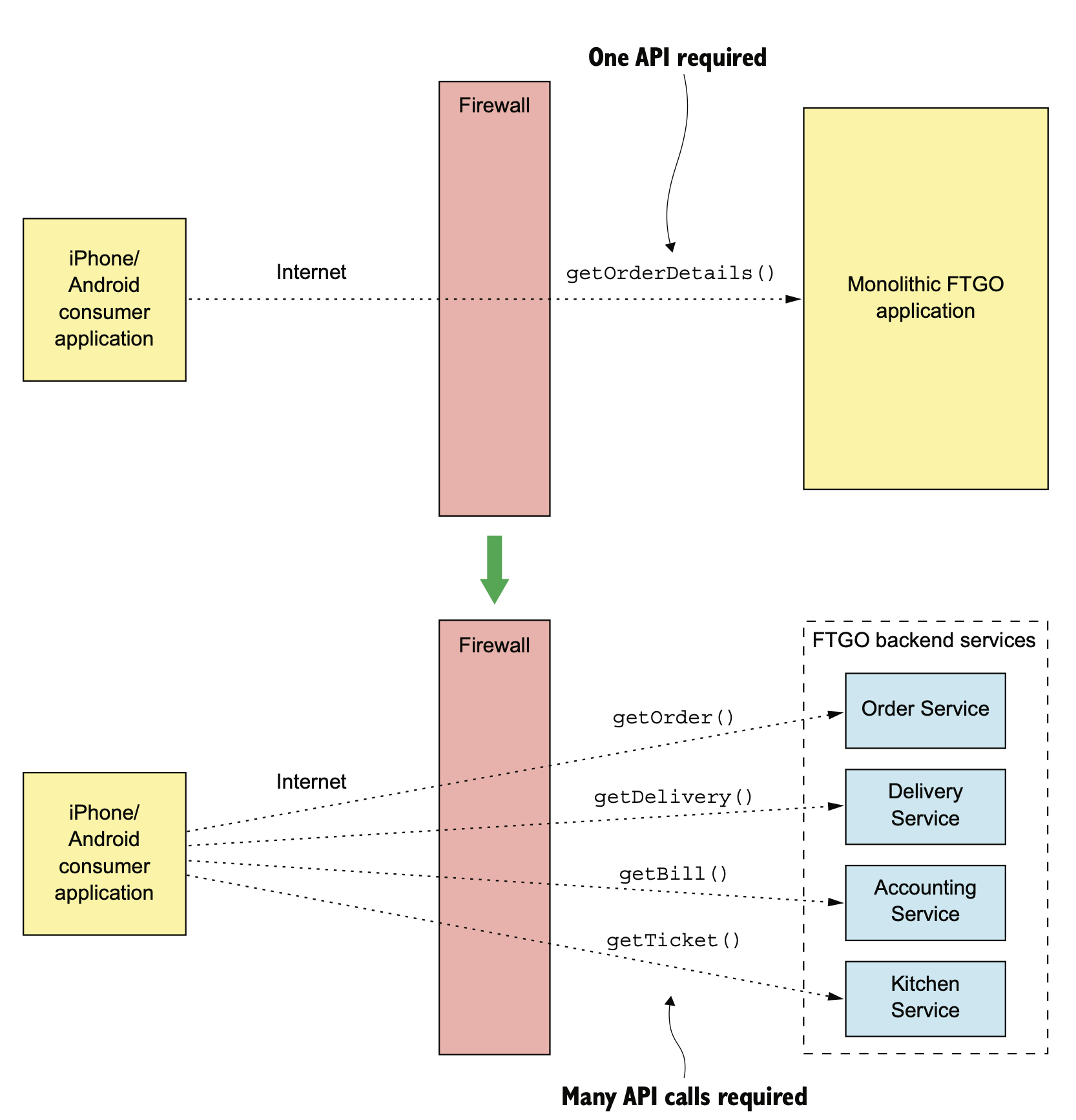
这就是我们为什么需要中间有一个 API Gateway 的原因。
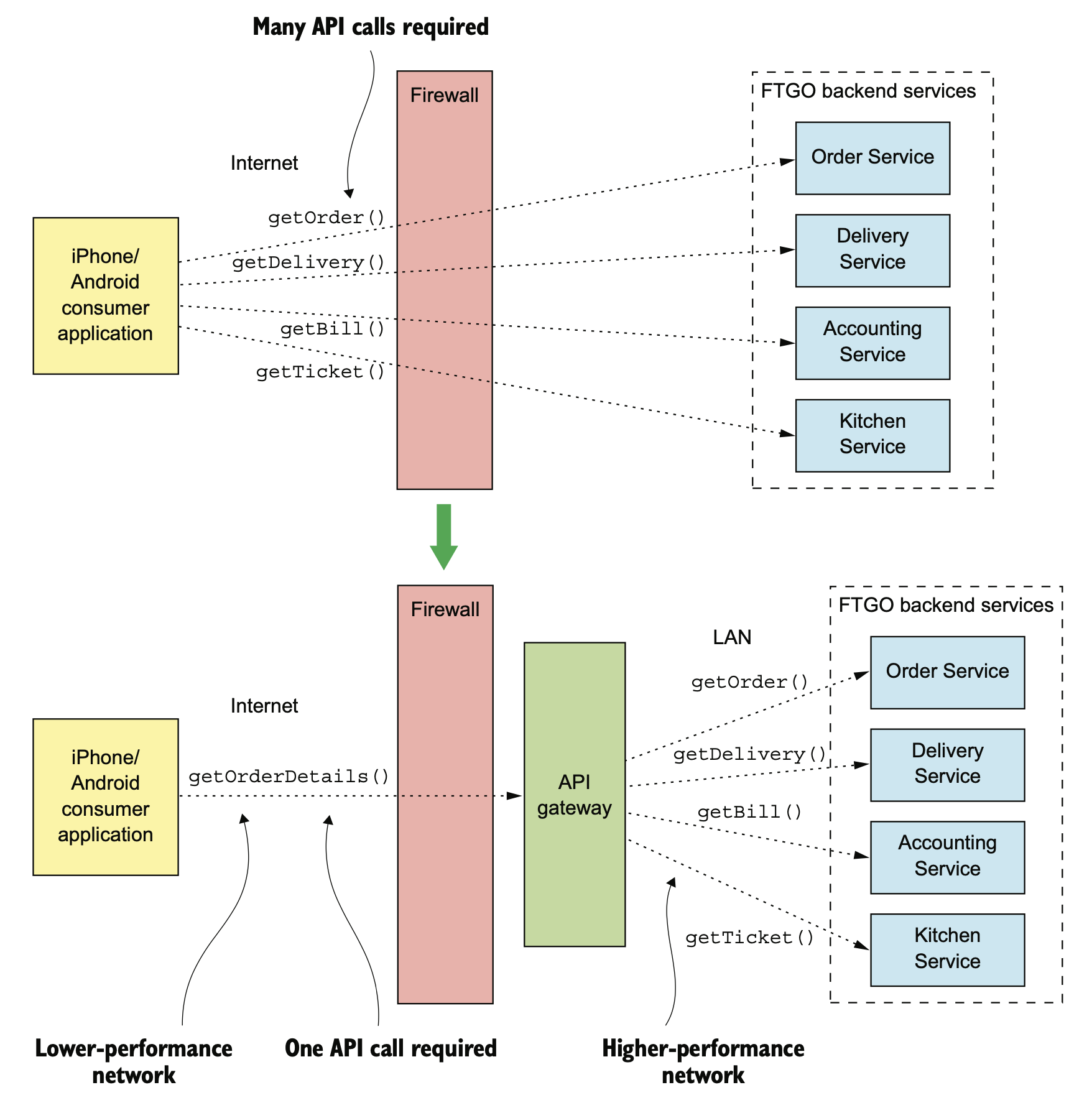
有了 Gateway 之后,在 internet 依然还是一次调用,在内部 IDC 强网络的状态下多次网路调用相对没有那么糟糕。
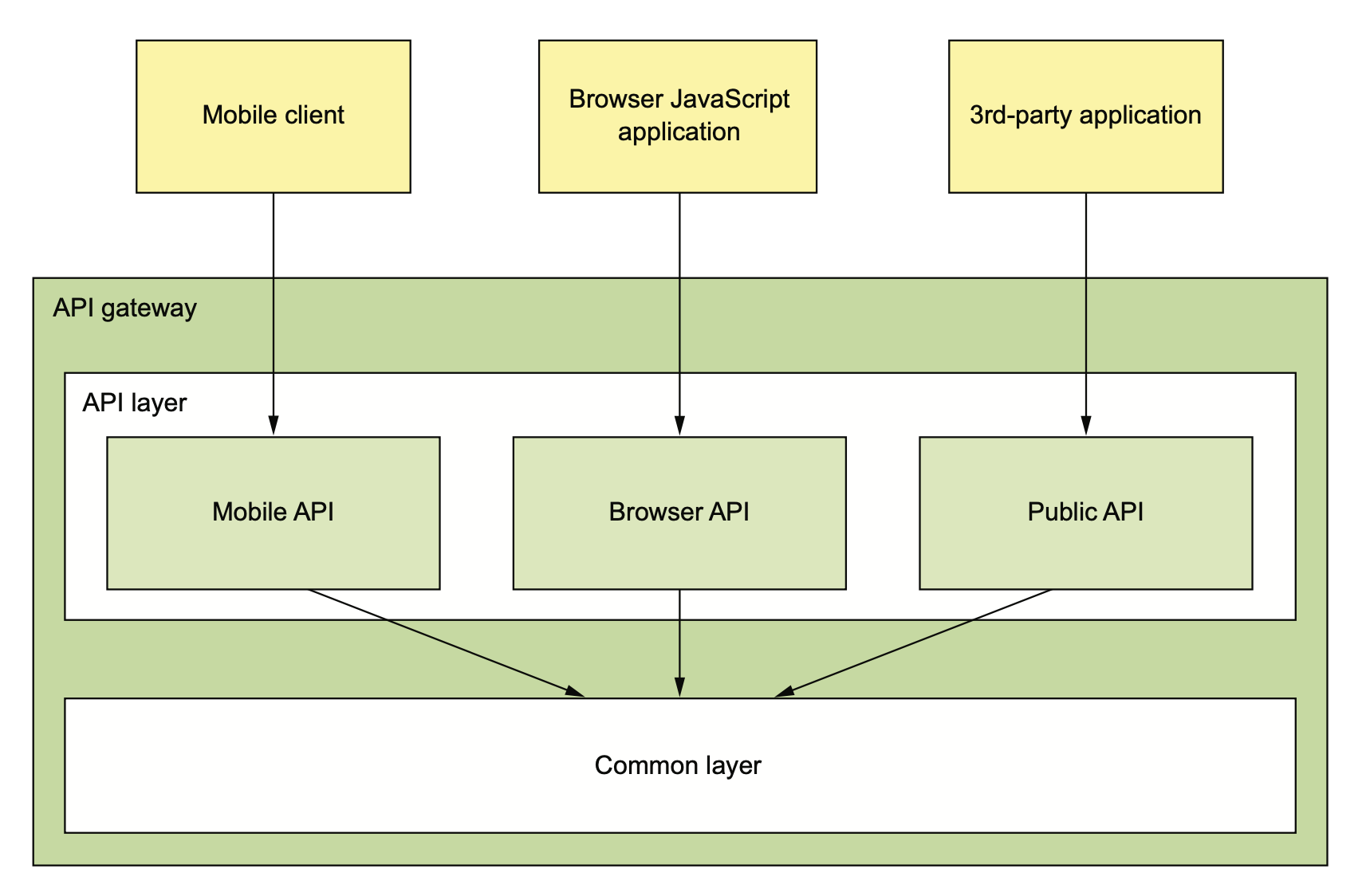
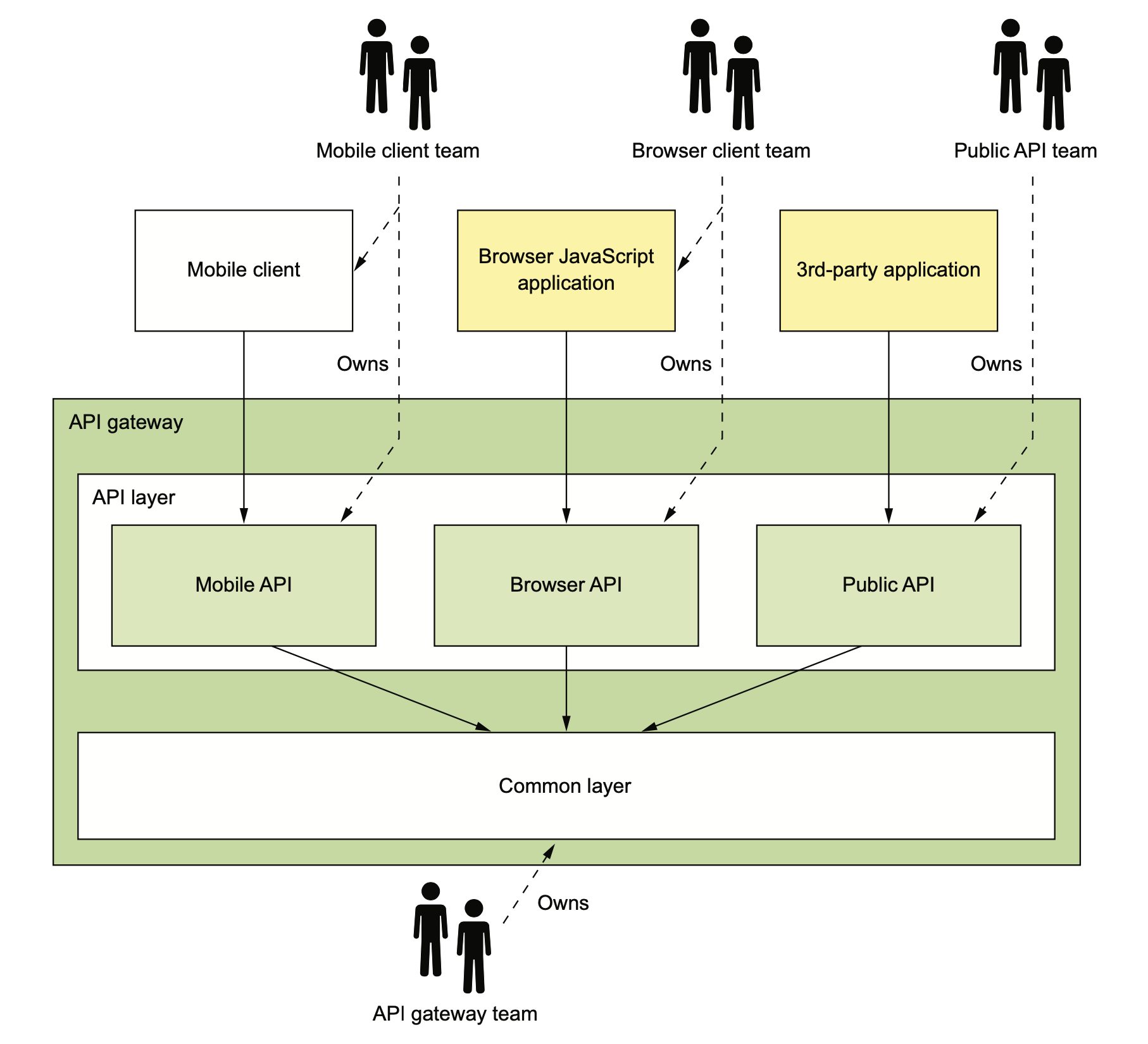
API Gateway 涉及到这些不同端的 API Gateway 应该要谁来维护的问题。下面是一种理想的情况,Mobile 团队负责维护他们在 Gateway 里的 API(也可能是单独的 Gateway),web 端团队维护 web 的 Gateway,open API 团队负责维护第三方应用的 Gateway API。
网关基础设施团队负责提供这三方都需要的基础库。
在研发 API Gateway 的时候,我们有多种可选项:
- 直接使用开源产品
- Kong
- APISix
- Traefik
- 自研
- Zuul
- Spring Cloud Gateway
- RESTFul 自己做一个
- GraphQL 自己做一个
开源的 API Gateway 大多不支持 API 数据组合功能,所以公司内的 API Gateway 有时候有两层,一层是 nginx 之类的负责简单路由和鉴权的 gateway,后面还有一个业务的 BFF 来负责拼装端上需要的数据。
如果我们都是自研,那就可以在一个模块上把 API Gateway 需要的功能都实现。这里经常讨论的一个问题是,我们是要使用 REST 还是类似 GraphQL 的图查询。
Netflix 的工程师在 2012 年发表过一篇文章:

《为什么 REST 让我半夜睡不着》,老哥还挺幽默。内容大概是讲 Netflix 要面对成百上千的终端设备,Netflix 曾经希望能给所有终端提供大一统的方案,大家使用统一的 REST API,但后来发现这种统一的方式是放弃了对任一有自己特性的设备的优化,比如有些设备内存小,有些设备屏幕小,这些设备上你返回的很多字段数据对他们来说根本就用不上,纯粹是浪费网络带宽。有些设备用流式响应比返回完整响应性能更好,这也应该是要考虑的优化点。
所以 Netflix 做了一个叫 falcor 的方案,其实和后来 Facebook 的 GraphQL 非常类似,是用 JSON Graph 来描述内部 API 能提供的数据,然后用 JS 来定制图上的查询。
现在大多数人比较熟悉的还是 GraphQL:
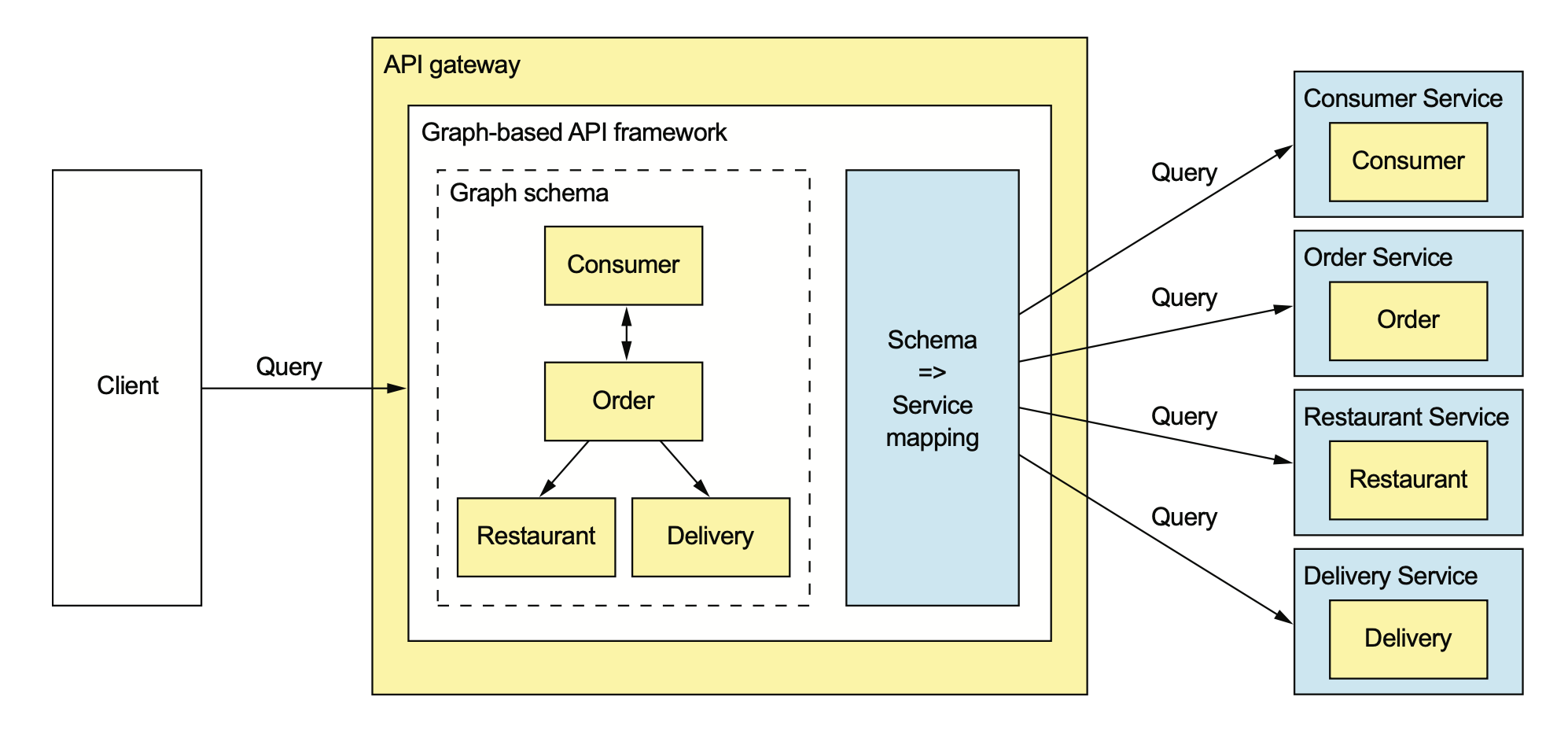
GraphQL 是个好东西,但之前我个人对使用 GraphQL 一直持怀疑态度,主要是因为:
- 网关容易被客户端的修改直接带崩
- 稳定性非常难保障
- 中文互联网上讲 GraphQL 的基本都没有提到限流,或者一笔带过,这是不太负责任的
直到最近我发现国外某公司公开了他们的 GraphQL 限流方案,这个方案非常有意思,我会在下一篇文章进行分享。
