当前互联网公司的后端架构都是微服务化的,服务彼此使用 RPC 通信,与业务无关的功能部分会从业务代码中抽离为框架。
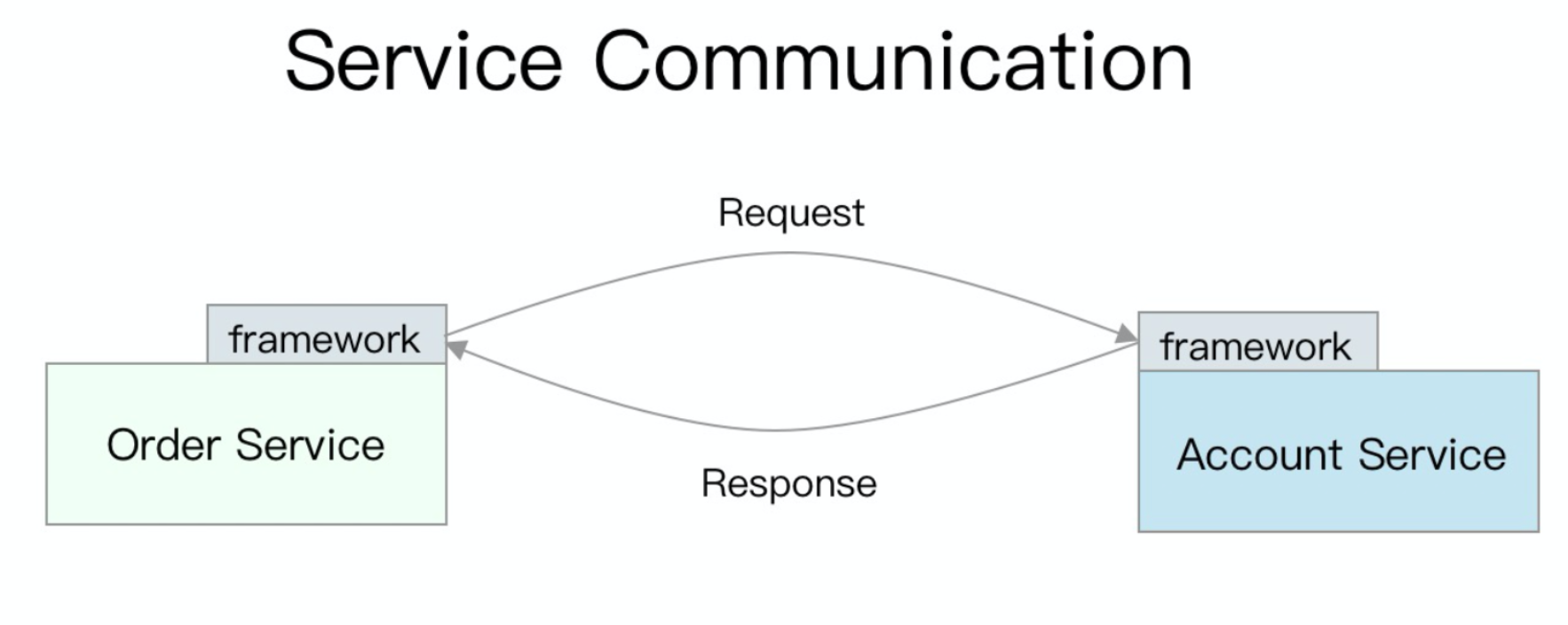
框架提供了基础的 RPC 功能,同时需要对稳定性负责,一个微服务框架包含但不限于以下功能:
- 路由
- 限流
- 熔断
- 负载均衡
- 服务注册与发现
- tracing
- 链路加密
这些功能看起来也是通用且稳定,所以我们对一个框架的印象往往是成型了之后便很少再升级了。但是云原生时代将我们的假设击得粉碎。底层基础设施也开始迅速发生变化,例如:
- 物理机集群 -> k8s 集群,破坏了我们的服务实例 ip 不会变的假设
- 基础设施给服务的资源分配方式发生变化,超卖使以往未经审慎设计的代码在恶劣环境下更易崩溃
- 服务数量的爆炸式增长使每个内部的微服务都要面对 C10k 问题,框架的优化变得更加重要。
借由此,框架的升级成为了比以前更频繁的需求。大公司内的海量服务框架升级往往工时以千小时计,即使只是有新的安全漏洞曝出,也会导致大量本可以用在业务上的工时被无端浪费。
设想,如果我们想在框架里试点新的限流策略,会要求业务帮我们升级框架;如果我们想要修复 bug 或安全漏洞,也会要求业务帮我们升级框架;如果我们想要回滚之前有 bug 的新功能,会要求业务帮我们回滚框架。长此以往,基础设施只会变成业务的累赘,而不是业务的加速器。
解决耦合的问题,要么就是增加一层,要么就是早点分手,mesh 是在这样的思路下产生的理念:
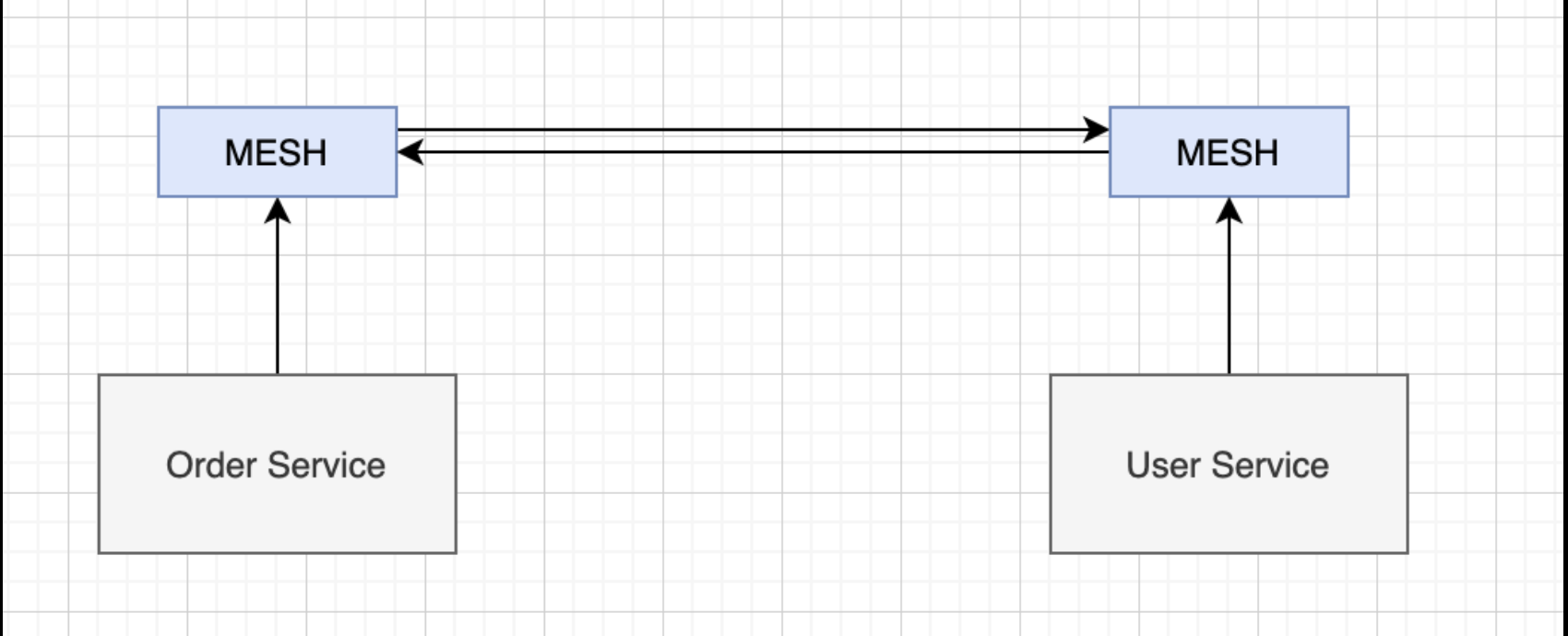
基础设施和业务模块在部署上成为了两个分离的模块,这样大家各自安好,各自升级,不出故障就两不相欠。
service mesh 模块中的功能都不算是新功能,这场分离运动一定程度上推动非功能性需求进行了一场浩浩荡荡的标准化:
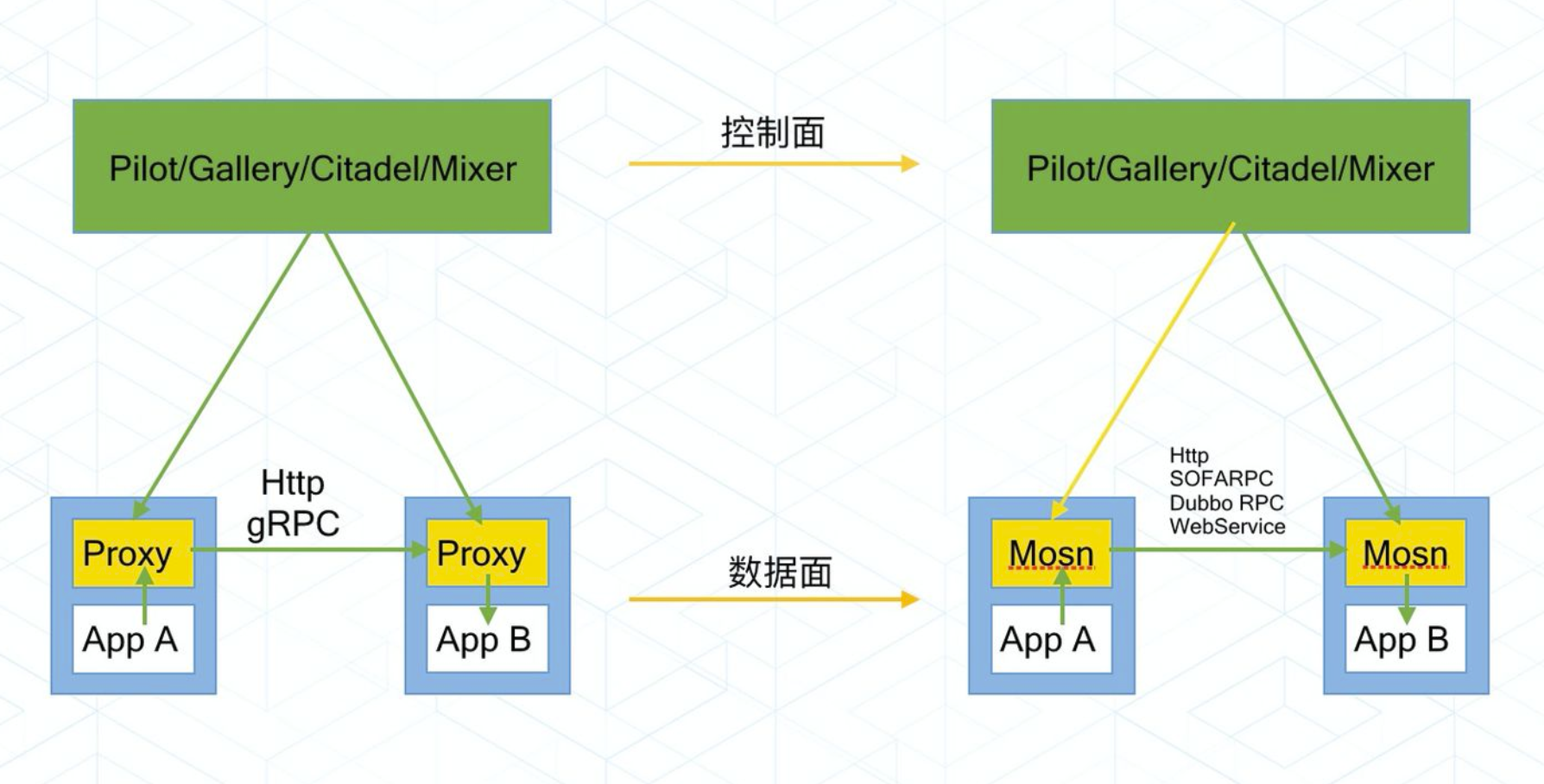
我们可以以下面的思路来对 service mesh 的控制面和数据面进行简单的理解和诠释:
- 控制面 = 配置管理(服务配置、路由配置、限流配置、证书配置等)
- 数据面 = 通信执行(连接处理,协议处理,按配置执行 proxy 逻辑)
其实就是配置管理和执行实体这两个部分,几乎所有需要动态配置化的软件系统都会这样设计。就像开源社区中的其它产品一样,如果一件事情是由两个实体来完成,那么就会涉及到谁来占主导权的问题(就像 k8s 和 docker 那样)。
从现状来看,当前主导局面的是社区中的控制面,也就是 istio 这类的软件。下面的图是社区中与 mosn 类似的产品 envoy 的图片,我们借来进行一些说明:
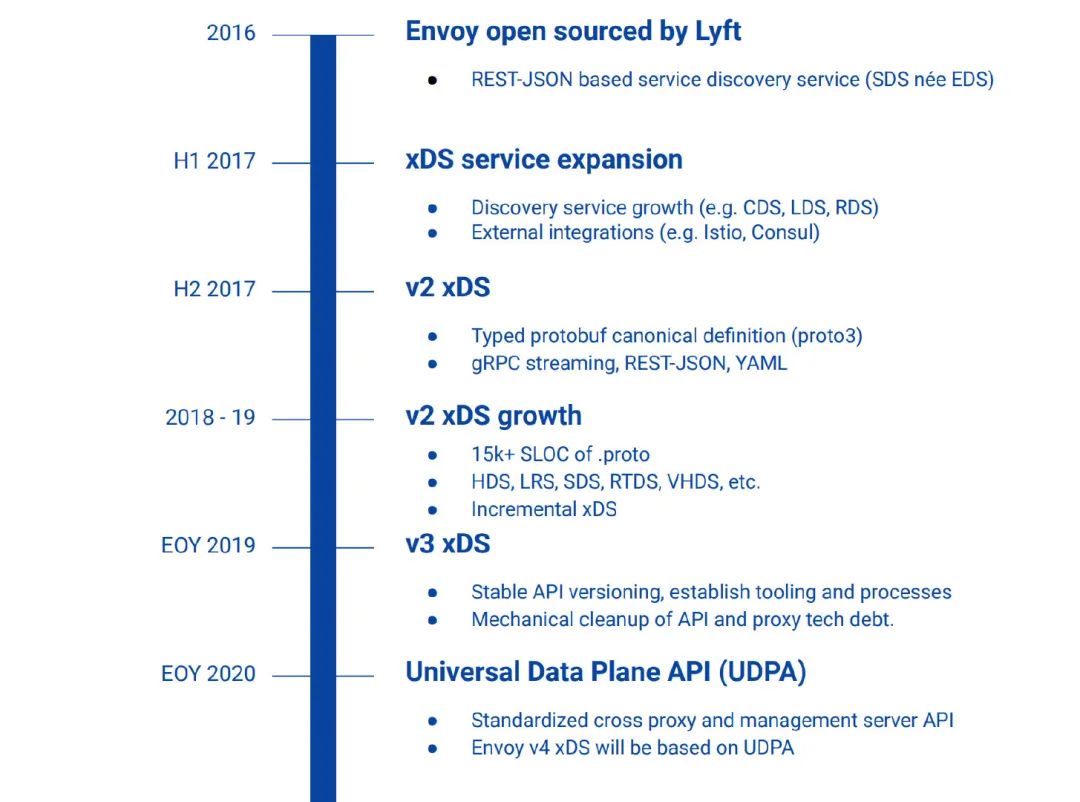
简单来讲,社区制定了一套标准,只要一个数据面软件支持该标准的 API(这里的 API 以前叫 xDS,未来叫 UDPA),那么该数据面便可以工作在支持该标准 API 的控制面环境。这和 docker 社区的 open xxx interface 很类似,可见开源社区基础设施模块间的配合未来都将工作在类似的模式下。
MOSN 也是支持 xDS API 由蚂蚁金服开发并开源的数据面模块,该模块在蚂蚁线上已部署了几十万服务实例,覆盖了支付主链路的服务。
当然,既然数据面是做网络通信的,MOSN 除了可以当 service mesh 场景下的数据面来使用,在内部实际上也是会被用来当做 API gateway 的底层模块来使用的。当前 MOSN 已经支持了大部分 service mesh 场景数据面的功能点:
- 通过 xDS API 对接 Service Mesh,支持全动态资源配置运行
- 支持 TCP 代理、HTTP 协议、多种 RPC 代理能力
- 支持丰富的路由特性
- 支持可靠后端管理,负载均衡能力
- 支持网络层、协议层的可观察性
- 支持多种协议基于 TLS 运行,支持 mTLS 支持丰富的扩展能力,提供高度 自定义扩展能力
- 支持无损平滑升级
当然,如果只是功能点和其它数据面差不多,也就没什么好说的了,最重要的是,MOSN 是用 Go 写的,相比 C/C++ 等语言编写的数据面,优点很明显,可以方便社区广大的 Gopher 上手学习和定制。
例如用户想要在 MOSN 中实现一套自己的协议,那么只要按照 step by step 的教程,实现下图中右侧的部分逻辑即可。
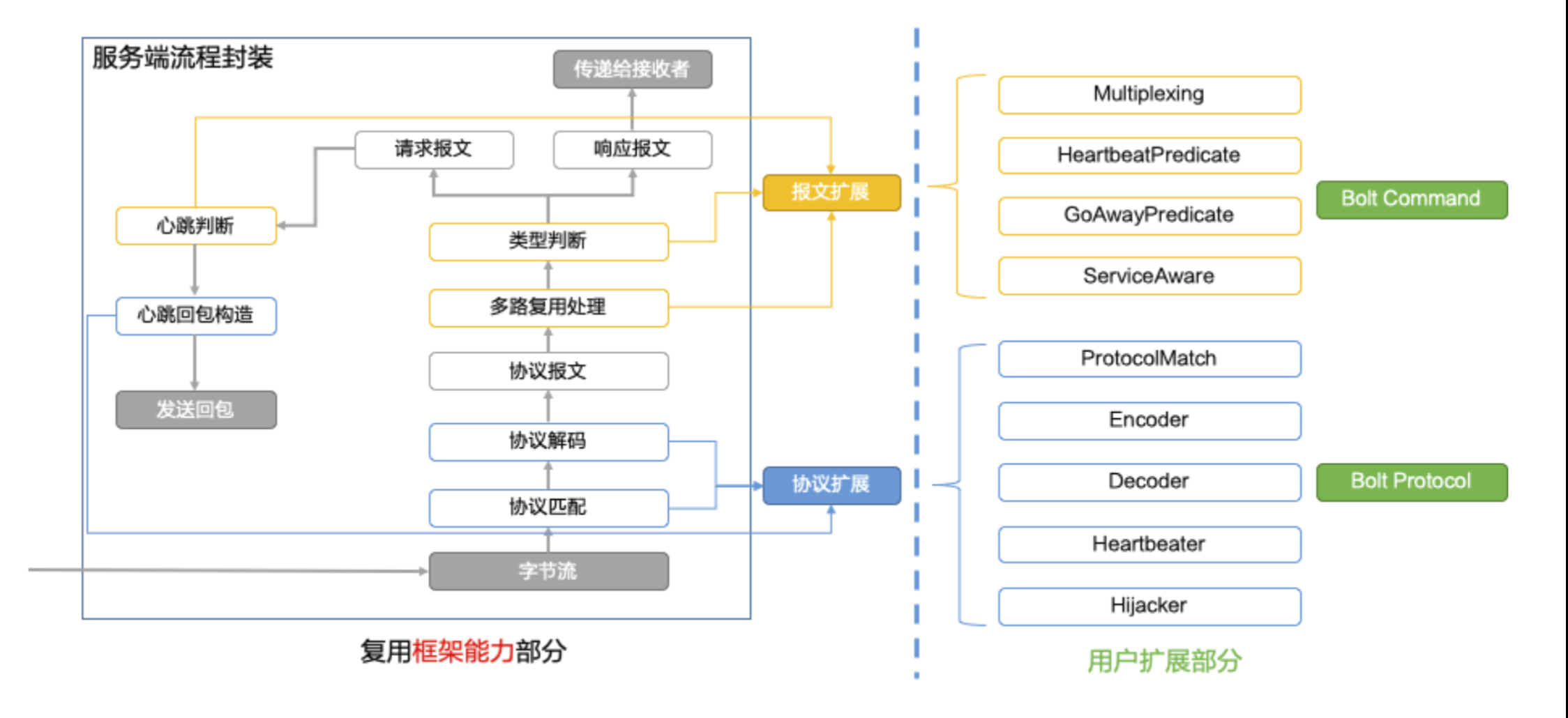
熟练的 Gopher 可以在当前基础上很快实现自有的协议 POC。
MOSN 是一个比较典型的网络应用,在 Go 语言中,大多数网络应用都可以理解为下面几个流程的循环:
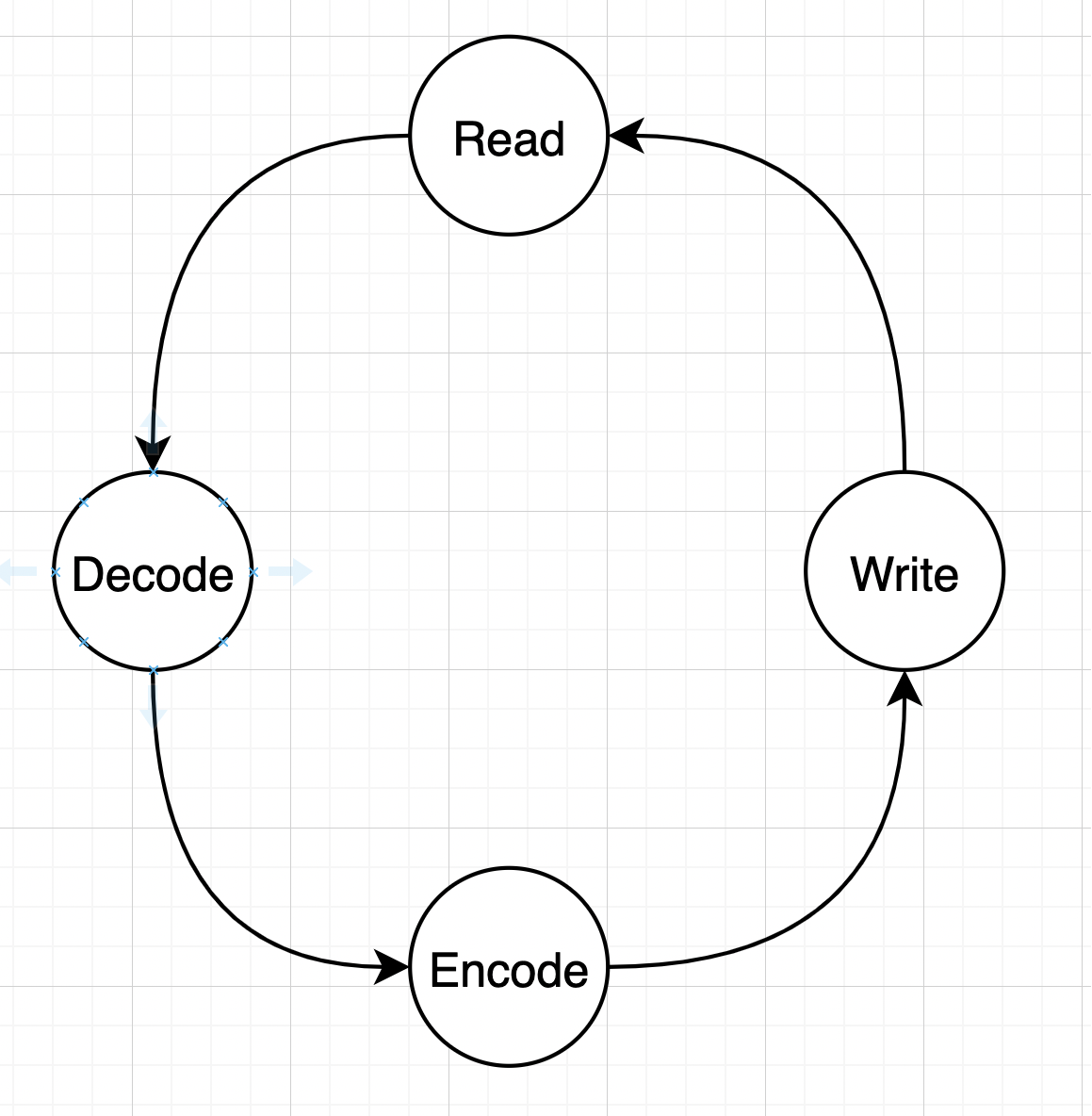
Go 语言的 netpoll 模块通过对 read goroutine/write goroutine 的抽象,以及 net.Conn 的 Read、Write 封装,在 OS 提供的同步非阻塞 (epoll/kqueue) 的回调流程上,实现了一套用户态的顺序流程,对用户完全屏蔽了底层操作系统的 IO 回调流程。极大地降低了语言的网络编程门槛,普通用户可以轻松地写出高性能的网络程序。
当 read buffer 无数据可读,而用户调用 Read 时,我们可以通过 pprof 看到阻塞 goroutine 的调用栈:
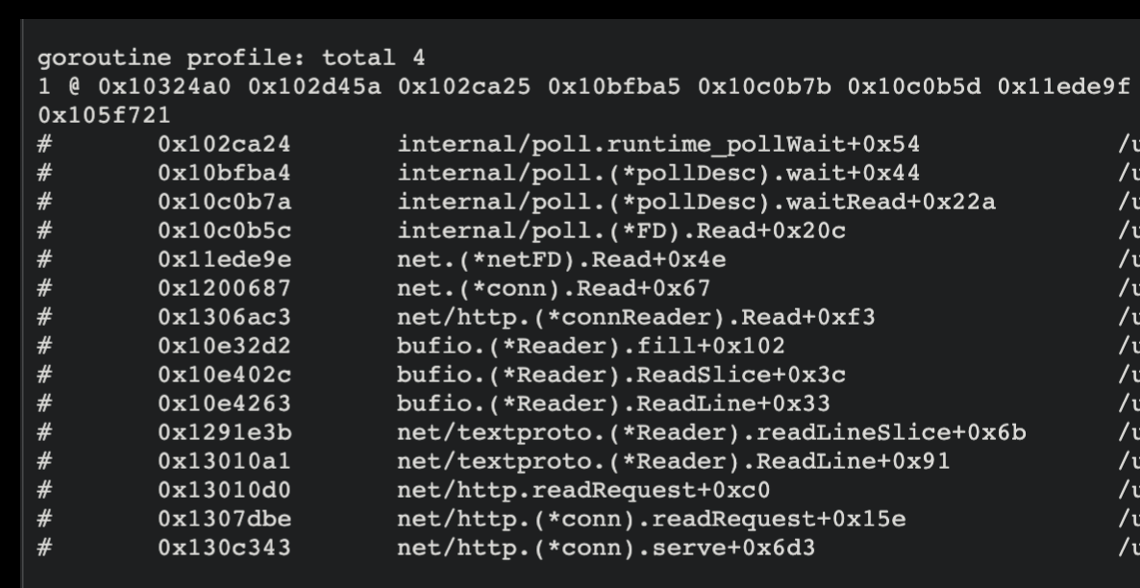
这个 goroutine 其实就是在执行 gopark 后,暂时休眠了,当 read buffer 有数据时,再执行 goready 把它唤醒,用户的逻辑继续向下执行。
虽然降低了心智负担,得到了一定程度的高性能的结果,但这种抽象也是有代价的。
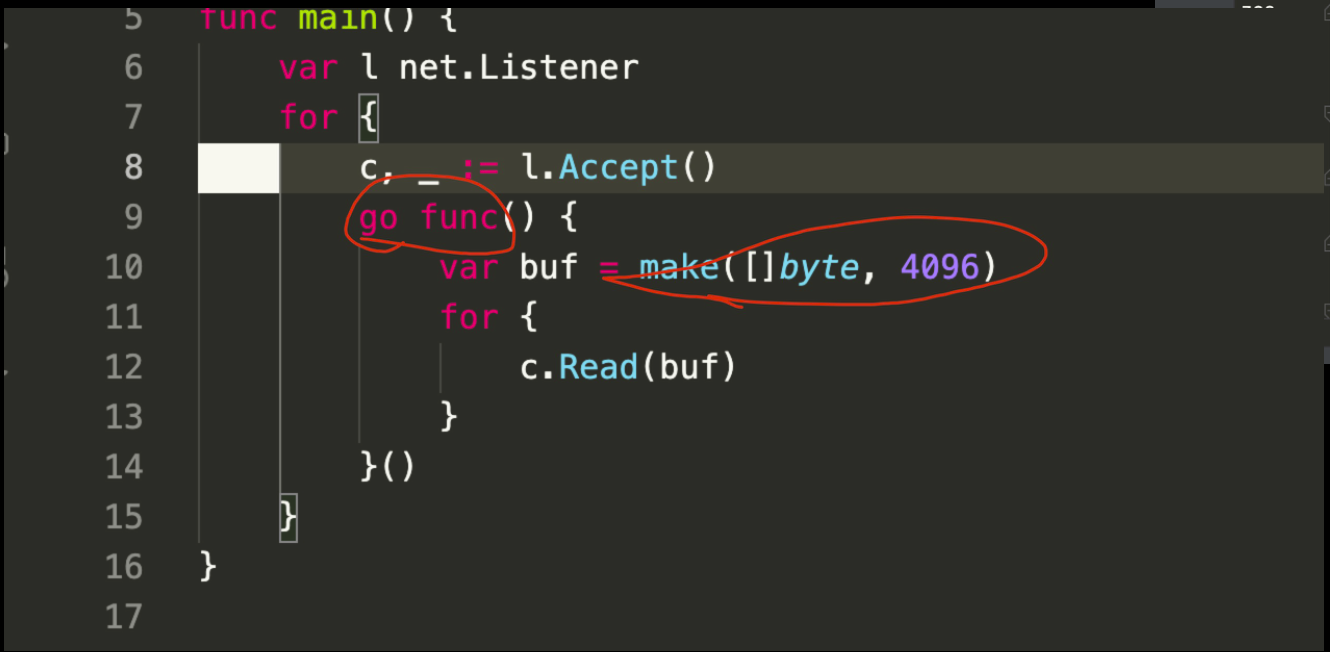
上图为常见的网络程序写法,accept 得到一个连接,然后启动 goroutine 来对连接进行 read/write。
如果我们的网络程序有 10w 长连接,可以简单计算一下该 go 程序的内存消耗,goroutine 初始栈为 2K,实际在线上的栈经常是 8K 左右,给每个连接分配 4K 的 read buffer。那么这个进程至少需要:12KB * 100000 = 1200000 KB = 1200 MB = 1.2 GB。
这也是非常保守的计算方法,read buffer 和 write buffer 的内存消耗与实际业务的数据包大小是密切相关的。因此我们可以想象,如果你的单请求/响应如果比较大,是 1MB 的话又会怎么样?
MOSN 针对内存问题有很多相关的优化,我们先来看看优化的前提:

这个图应该比较直观,我们认为任一时刻,正在读 or 写的连接都是一条活跃连接,其它没有任何行为的连接都是非活跃连接。从线上的实际场景来说,活跃连接在整体连接中的占比很低。因此 MOSN 都是在该前提下进行优化的。具体手段有两个:
- 让所有 buffer 都能够得到复用
- 如果在通信过程中有 buffer 涨到比较大,需要有机制能让 buffer 缩容
第一点 Gopher 应该都很熟悉,就是 sync.Pool,使用 sync.Pool 的话,相当于让请求生命周期内需要申请的对象只与活跃连接数成正比,而不是与所有连接数成正比。
第二点在 MOSN 中是通过连接读超时判断来完成的,当连接发生读超时,会判断当前连接的 read buffer 中是否有数据,同时 buffer 是否过大,如果没有数据且过大,那么这就是一个很好的缩容机会。
做到这两点,对大多数 buffer 导致的内存占用问题有了很好的缓解。但极端情况下,还是会有 OOM,这就是 Go 语言本身的特性导致的了。我们知道在 Go 语言的 GC 有三个触发点:
- 两分钟没有发生 GC,则强制 GC
- 用户手动调用 runtime.GC(一般线上不这么用,该函数主要用来写测试
- 程序当前使用的堆内存到达了 runtime 中动态计算出的 GC heap goal
如果进程频繁地申请大内存,那么会把 GC heap goal 不断地推高,在云环境下,任何程序运行都是有内存限制的,如果你的进程 heap goal 被推到超出内存上限,那么就可能在执行中发生 OOM。
这个问题比较难解决,据笔者所知,当前业界还有两个其它 buffer 管理方案:
- dgraph 的方案,能明确生命周期的对象,可以在堆外进行内存分配和释放,不会影响到 GC heap goal
- 链式 buffer,扩容时,在 buffer 链表后增加一个新 buffer,缩容时,就是把链表后的节点干掉。相比一些简单的 buffer 扩容/缩容策略,这种方式不会产生过多的 buffer 对象,大家都在复用单元大小的 buffer 来组成自己的 buffer 链
不过这两个方案目前笔者还没有进行尝试,所以暂时不确定这两个方案是否能够缓解大内存分配推高 goal 导致的 OOM 问题。未来有机会的话,会在尝试后再做分享。
这次分享先讲了怎么解决问题,其实我们发现这些问题的过程也是很曲折的,MOSN 在公司内部落地是一个平台级的应用,有很多组外的同事在 MOSN 基础上编写和内部业务相关的代码,在几十万实例中,一点小问题就会被放大成各种大问题,万分之一概率发生的问题,在几十万的实例环境下也变成了 100% 会发生的问题。
但线上的很多问题都是瞬时(也没那么瞬时啦,可能几十秒)发生,然后短时间恢复,从收到报警再到上线去把 pprof dump 好一定是来不及的。如果 MOSN 短时间发生 OOM,发生 goroutine 暴涨,或者 CPU 占用暴涨,想要能快速地发现 root cause 非常困难。
我们设计了一个使用 moving avgerage 理念的工具,计算多个周期内的 CPU/RSS/Goroutine 数的平均值,来帮助我们判断线上的进程是不是发生了某些抖动(OOM 也可以被归类为抖动)。这个工具解决了困扰我们很久的线上系统发生抖动怎么定位的问题。
举两个例子:
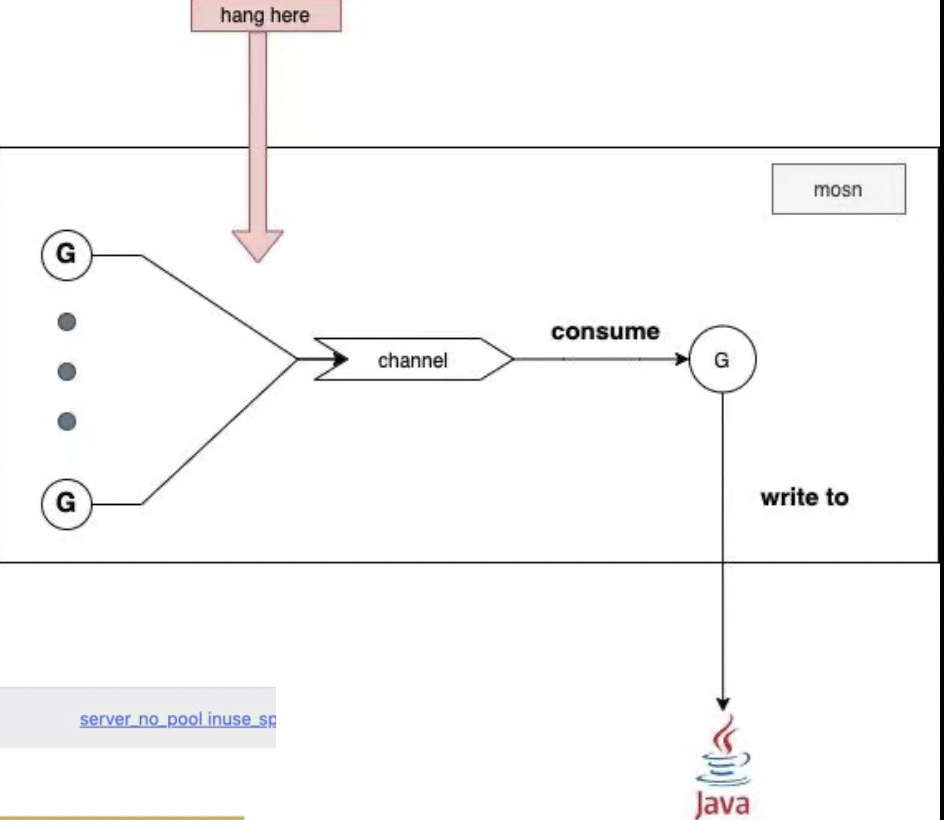
图中表示的场景是: N * request G ----> write to channel -----> consumer G -----> write to local java
从 consumer G 写到本地 java 进程这里是个本地网络操作,MOSN 的老代码里并不认为这是个可能发生阻塞的地方,因为 pod 内的网络通信(不了解 k8s 的同学可以认为是在同一个物理机上的两个进程通信)都是很快的。但是在业务高压力时,我们发现有一个机房的一个服务的 MOSN 实例却偶尔会 OOM,通过上述问题定位工具在抖动时 dump 的 profile,我们发现导致 OOM 的元凶就是这里的 N * request G 堆积。
有了结果,再去推导过程就很简单了,我们只是看了看监控图,就发现在发生堆积的时间点,业务 java 进程发生了 FGC,一次几十秒。
再举一个例子:
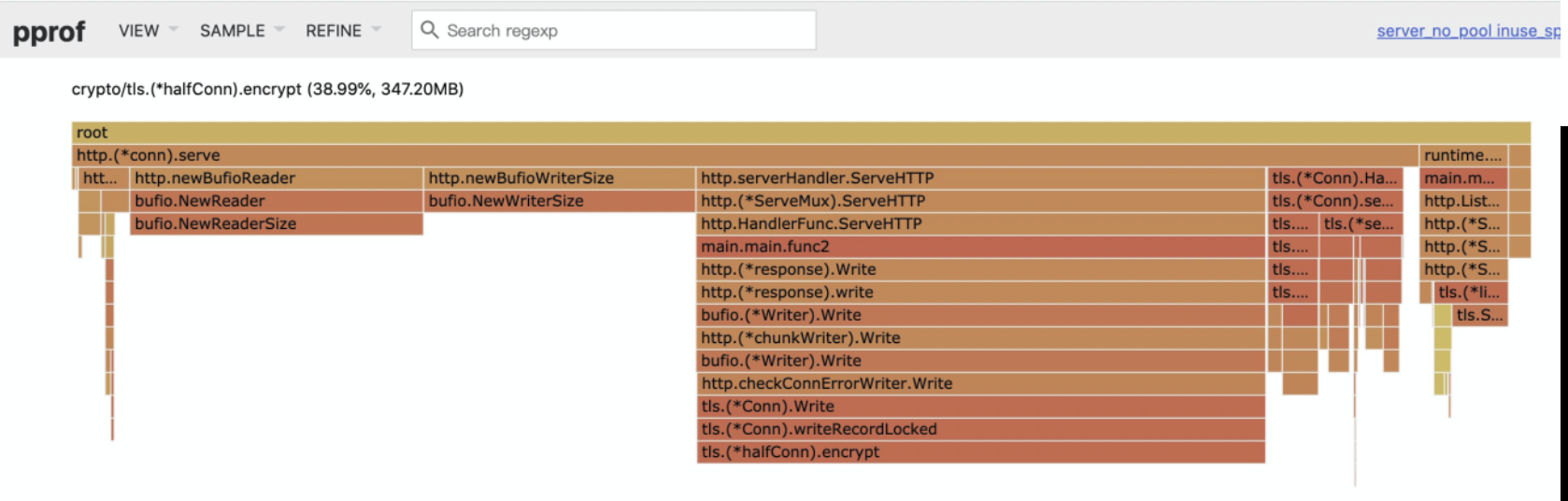
公司内部在推进全链路加密的时候,发现开启 TLS 后,有些应用占用的内存会一直上升,直至 OOM。同样查看了 dump 工具保存好的现场后,发现 TLS 本身的逻辑里也是有一些 read、write buffer 的,这些 buffer 是在 tls.Conn 对象上,这和前面我们说的问题类似,对象的数量和总的连接数相关,所以在高连接数场景下非常容易爆内存。
上面的图是我们在 http tls 下模拟的,可以看到这个例子是加密后的 write buffer 占用了很高的内存,这个问题我们修复后已经把 PR 提给了 Go 语言官方,并且已经被接受,1.16 版本中应该已包含该优化。本例中只优化了加密的 write buffer,其实 read buffer 也是会有类似的问题,我们暂时没有想到较为通用的解决方案,所以当前 read buffer 的优化只合并进了 MOSN,还没有提给 Go 官方。
说到这里,可能读者已经迫不及待地想要加入 MOSN 社区来了解 MOSN 了,这里简单介绍一下 MOSN 社区的组织形式:
- MOSN 用户群/开发者群
- MOSN committers
- MOSN SIG
- MOSN 开发者会议
首先是用户钉钉群,想要了解或者把玩 MOSN 的同学都可以加入来学习,与 MOSN 的蚂蚁员工、社区用户来交流。如果用户有定制需求,或者要参与社区的开发工作,那么我们会将你拉进开发者群,这里基本都是 MOSN 的社区开发和外部用户,他们基本上都是动过 MOSN 的代码的。
长期给 MOSN 做贡献的同学会被社区选拔为 MOSN committer,我们目前已经有了十个左右的 committer,除了蚂蚁的员工外,还有阿里云,多点,头条等公司的同学被认证为 committer,committer 会进入 MOSN 的 SIG 小组,负责 MOSN 的版本发布工作,参与一些核心的设计的讨论。对 MOSN 未来的发展具有一定的话语权。
同时 MOSN 会不定期举办社区开发者会议,一般由 SIG 成员来主持,聆听社区的声音,向社区传达一些 MOSN 发展的近况,并进行相关的记录。
2021 年,MOSN 这个项目还计划了新的 roadmap:

这些新功能中,有一个比较大的优化,是 MOSN 的网络层优化,未来 MOSN 可能会将网络层做成可替换的组件:
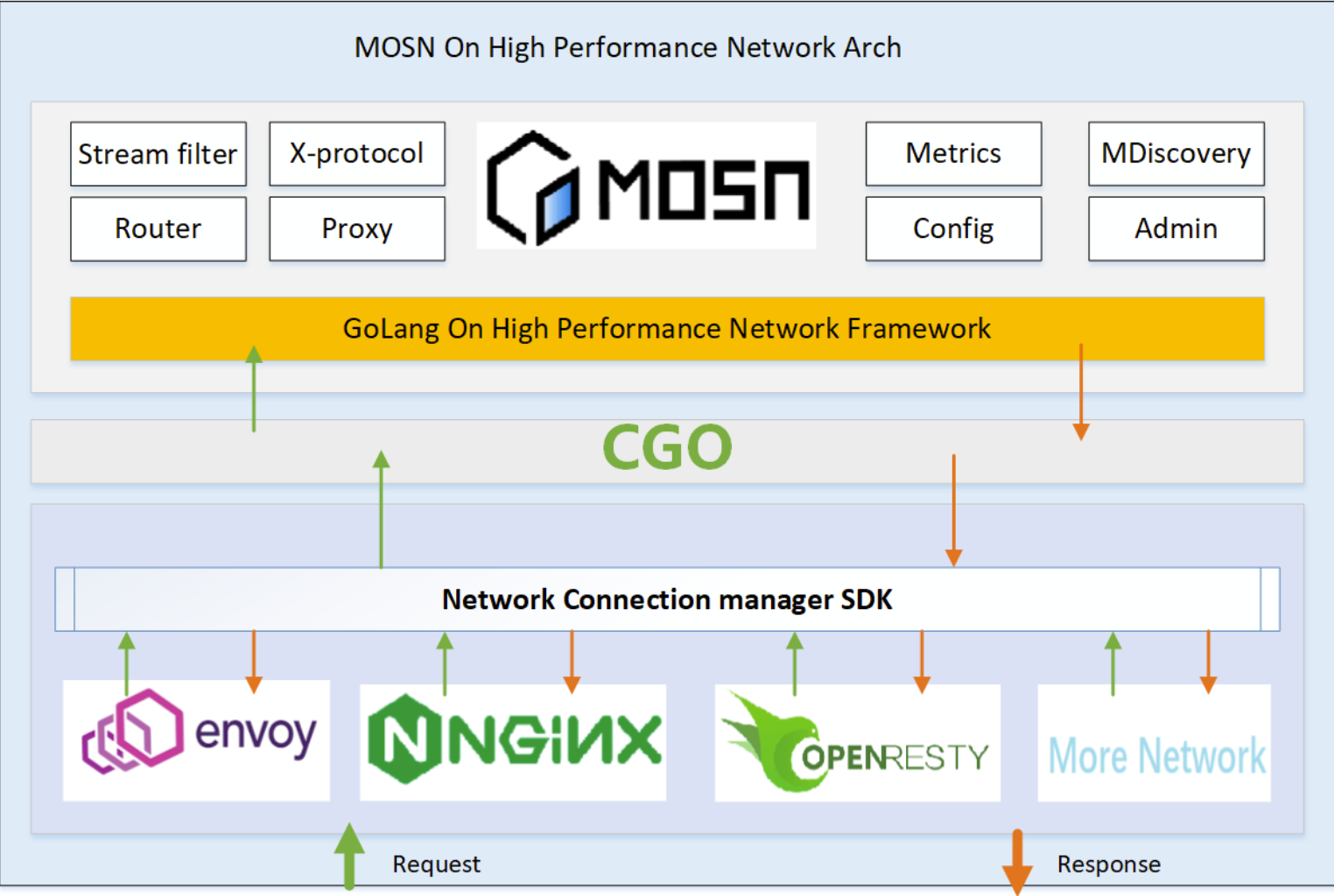
对 roadmap 感兴趣的同学可以访问 mosn roadmap 参与讨论。
对可替换的高性能网络层感兴趣的同学可以访问 moe 参与讨论。
除此以外,公司内的同事还提出了使 MOSN 从 service mesh 进化为 cloud native application runtime 的方案 CNAR,其理念和微软的 dapr 相似,最近 dapr 也发布了 1.0 版,希望大家多多关注 MOSN 和相关的技术。
