之前公司因为 aws 的 kafka 服务上的副本数配置不正确,所以在 aws 例行重启时会导致 producer hang,连锁导致消费断连,当时总结了一篇简单的文章:
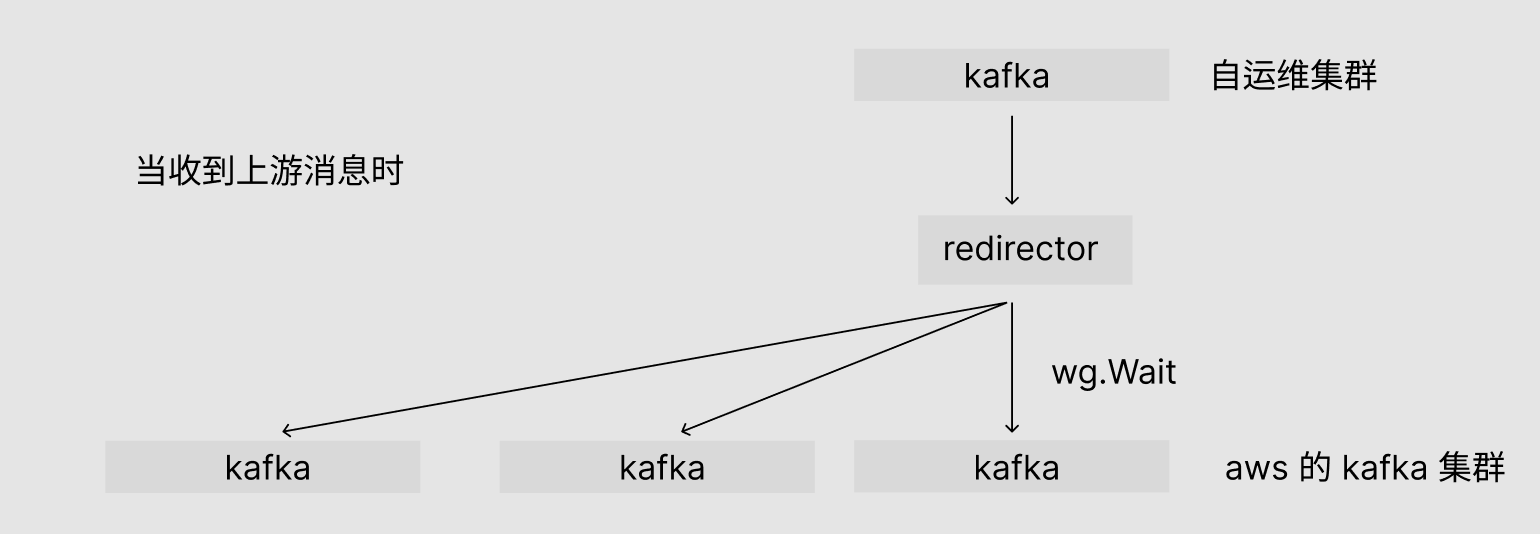
然而在将队列的副本数都修正之后,发现 producer hang 从高概率必现变成了低概率必现。。这就让人头痛了。
虽然我们也保留了问题的现场,把各种日志多种姿势 Google 检索,但始终没有找到任何线索,本来还想偷个懒,看看能不能直接照抄解决方案,看来没得参考了。

好吧,自己动手丰衣足食,不读代码是不行了,之前 sarama 的 producer 内部逻辑用了比较多的 channel,看着比较烦一直没有认真读,现在只能自己搞了。
我们先和公司内的队列运维同学以及 aws 的 msk 售后经过了多轮沟通,确定了 producer hang 的一些场景特征:
- producer hang 只会发生在 aws 上,在自运维的集群中复现不出来
- aws 上并不是必现,需要在安全更新期间
- producer 被 hang 住之后,没有任何错误返回
- aws 的 broker 重启和 leader 选举要比我们自己的集群慢,大概要 1-2s
出问题的时候,producer 的日志长这样:
send msg succ 584
send msg succ 585
send msg succ 586
send msg succ 587
2022/10/21 06:20:54 client/metadata fetching metadata for [t5] from broker b-3.testmsk.rwb418.c13.kafka.us-west-2.amazonaws.com:9092
2022/10/21 06:20:54 producer/broker/1 state change to [retrying] on t5/11 because kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:54 Retrying batch for t5-11 because of kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:54 client/metadata fetching metadata for [t5] from broker b-3.testmsk.rwb418.c13.kafka.us-west-2.amazonaws.com:9092
2022/10/21 06:20:55 producer/broker/1 state change to [retrying] on t5/11 because kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 Retrying batch for t5-11 because of kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 client/metadata fetching metadata for [t5] from broker b-3.testmsk.rwb418.c13.kafka.us-west-2.amazonaws.com:9092
2022/10/21 06:20:55 producer/broker/1 state change to [retrying] on t5/11 because kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 Retrying batch for t5-11 because of kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 client/metadata fetching metadata for [t5] from broker b-3.testmsk.rwb418.c13.kafka.us-west-2.amazonaws.com:9092
2022/10/21 06:20:55 producer/broker/1 state change to [retrying] on t5/11 because kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 Retrying batch for t5-11 because of kafka server: Tried to send a message to a replica that is not the leader for some partition. Your metadata is out of date.
2022/10/21 06:20:55 producer/txnmanager rolling over epoch due to publish failure on t5/11之后日志便不再滚动,注意这里最后一行的日志 `producer/txnmanager rolling over epoch due to publish failure on t5/11` 因为比较特殊,直接用文本去代码里搜索,可以找到代码的位置在:
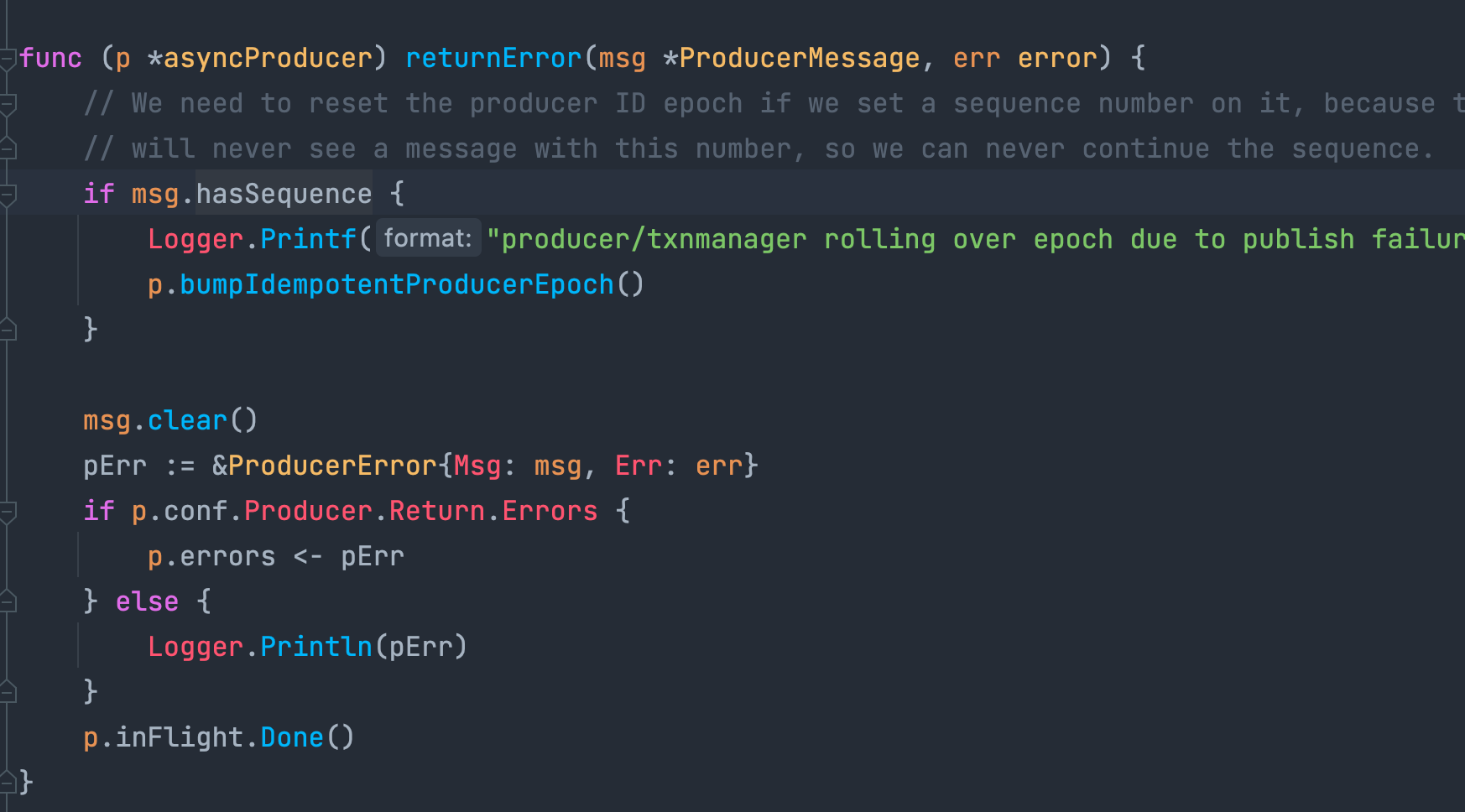
这里 msg.hasSequence 是在 producer 设置了 idempotent 时才会为 true 的:
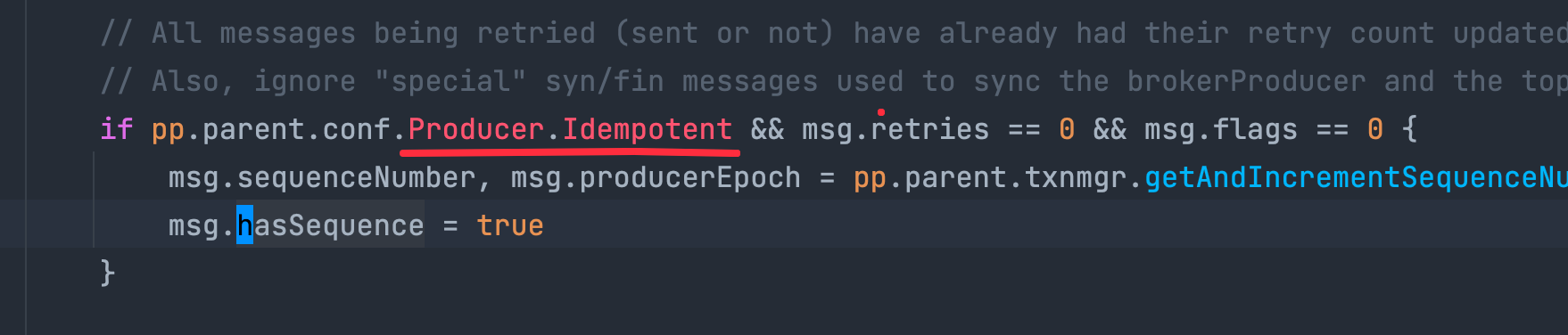
这说明我们部门目前的 producer 设置了 idempotent,和之前读代码时的认知相符。
既然知道了 idempotent 的特征,就需要看看 idempotent 的流程和非 idempotent 的流程有什么不同,经过一番确认和筛选,最终看到区别在 retry 流程。当 produce 发生错误时,有一类是 sdk 认为可以通过重试自动恢复的错误:
case ErrInvalidMessage, ErrUnknownTopicOrPartition, ErrLeaderNotAvailable, ErrNotLeaderForPartition, ErrRequestTimedOut, ErrNotEnoughReplicas, ErrNotEnoughReplicasAfterAppend:从日志中可以得知,我们触发的 producer error 就是 ErrNotLeaderForPartition 和 ErrLeaderNotAvailable,都是可以通过重试恢复的错误。
重试时,若用户设置了 produce 为 idempotent,则会进入 retryBatch 逻辑:
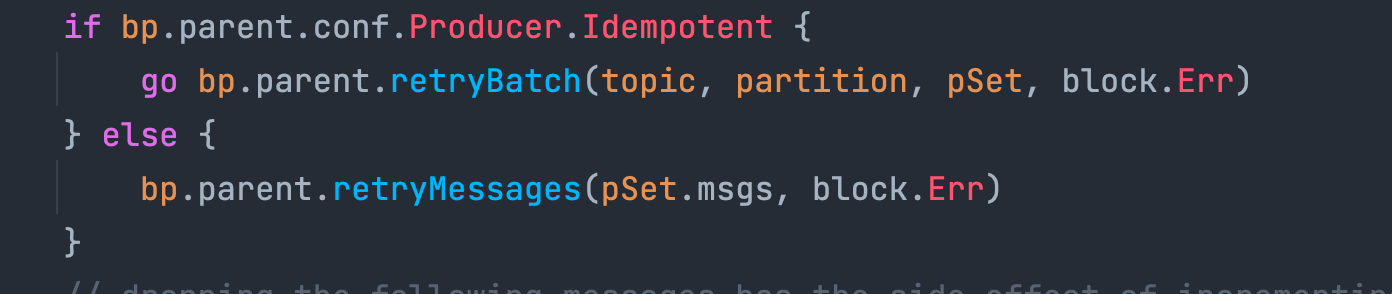
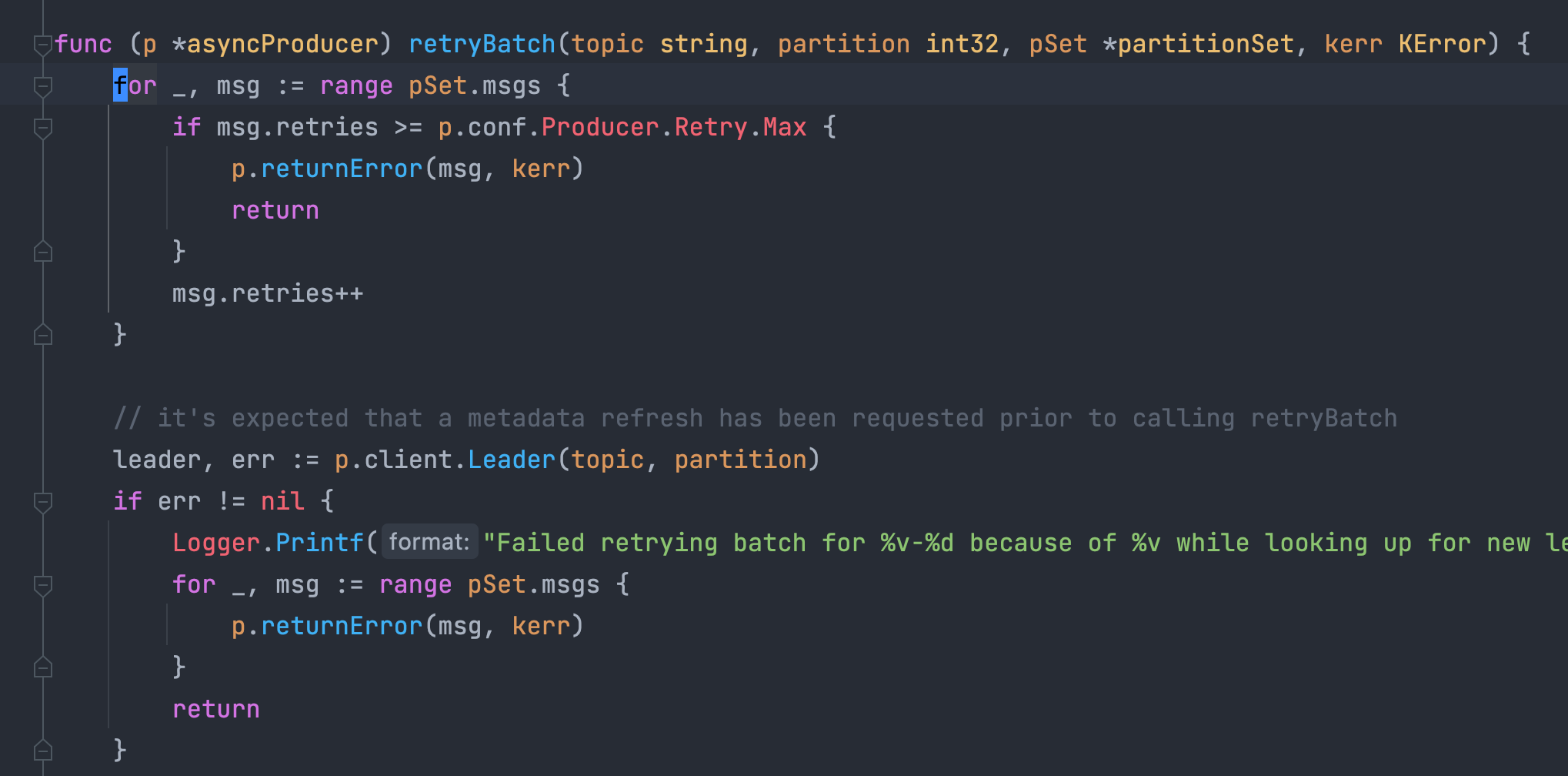
这里的 retryBatch 判断批量重试过程中,某条消息如果重试次数超标了,那么就会直接从函数中返回,而我们在阅读这段代码的时候会发现,紧跟着超 retry.max 的逻辑,当获取 partition 的 leader 逻辑出错时,每一条消息都返回了错误,这已经能够给我们足够的提示了:这里不应该在一次 returnError 时直接 return,而应该将批量消息中的每一条消息都返回错误。
可能大多数读者对 sarama 的 producer 逻辑不太了解,我们这里简单画一个图:
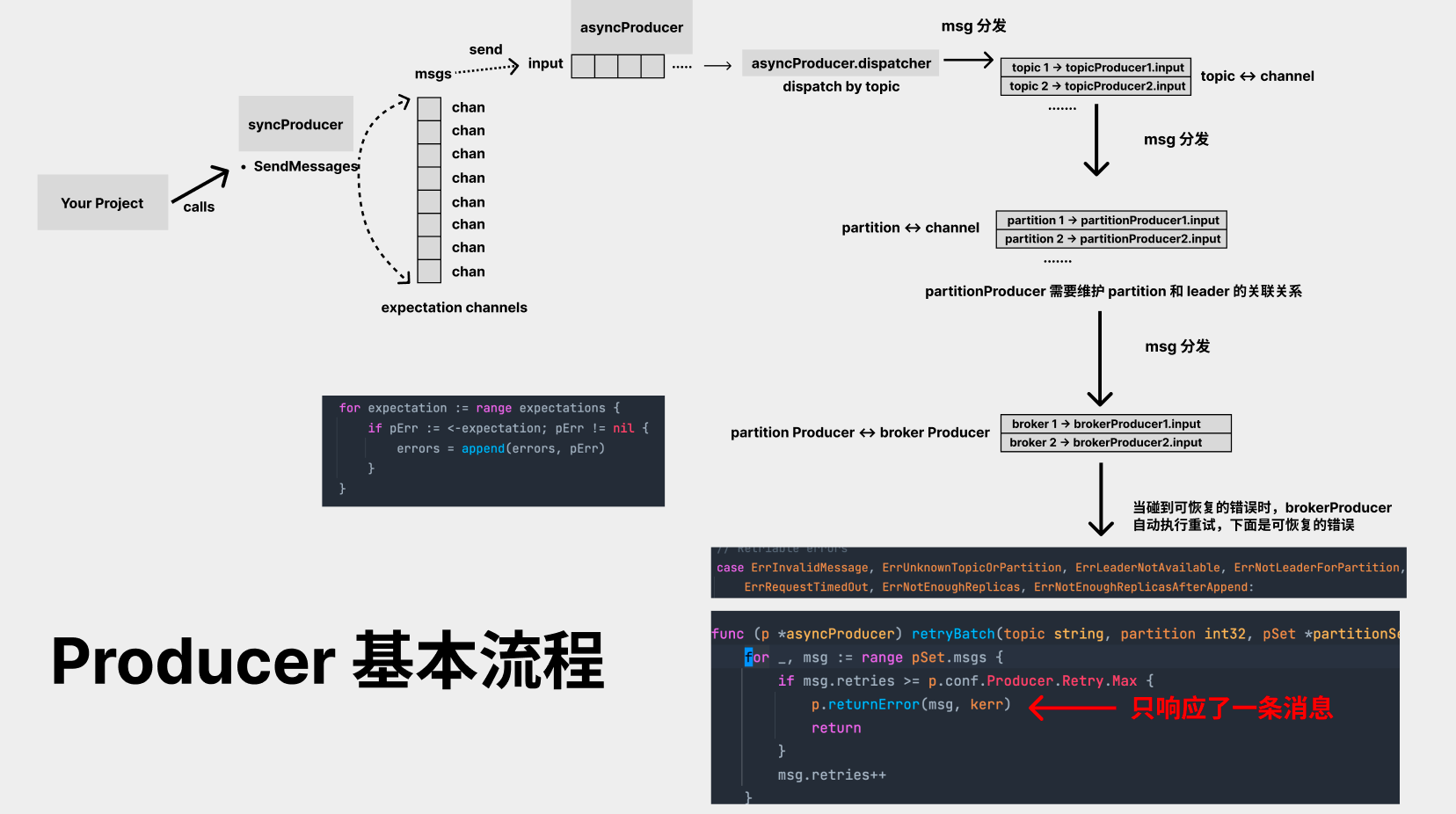
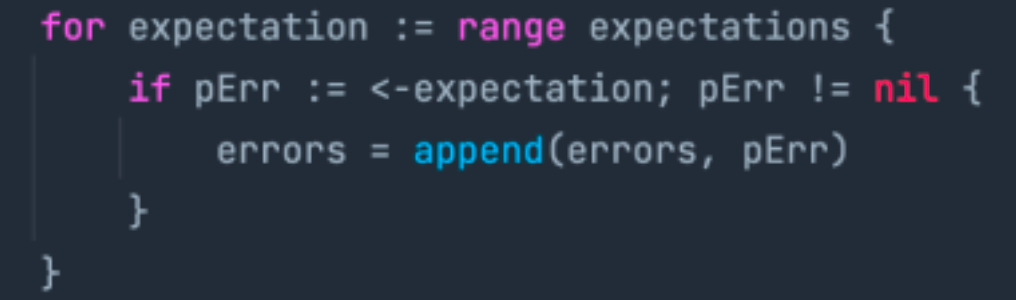
简单来说,用户调用 producer 的 SendMessages 接口,sarama 的 sdk 会给每一条 message 生成一个 ProducerMessage 对象,且对象内部会自带一个 channel,成功时,该 channel 需要返回 nil,失败时,需要返回 error 信息,每一条消息都必须有明确的成功 or 失败,因为 SendMessages 函数中会等待每一条消息的 expectation channel 有内容返回才能正常向下执行:
在 producer 的 sdk 中,这条 ProducerMessage 虽然传递链路较长,会从 asyncProducer.input -> topicProducer.input -> partitionProducer.input -> brokerProducer.input 一路传递,但最终的 response 都是从 msg 的 expectation channel 中返回的。
如果某条消息的 expectation channel 没返回,那么就会导致用户的 syncProducer 无限 hang 下去。
阅读代码和流程分析到这里,我们已经基本可以知道原因了,这个问题的触发流程是这样的:
- aws 执行安全更新,broker 滚动重启
- broker 下线期间,某些 topic 的 leader election 较慢,经过了 1-2s 才把新的 leader 选出来
- 我们部门的 kafka producer 使用了 idempotent = true 和 sendmessages 批量发送接口和默认的 producer.retry = 3,producer.backoff = 100ms
- 当 broker 下线且 leader 未选举出时,经过 3 次后,leader 依然未恢复,这时由于 sarama 的 bug,导致某些消息的 expectation channel 一直没有resp/err 返回
- 之后 producer 就永远 hang 在 SendMessages 函数上了
这个问题后来也提给了 sarama 官方,不过外企很 wlb,至今依然没有回复:
 Shopify
Shopify Shopify
Shopify
我反思了一下,为什么这个问题其它公司没怎么遇到过,Google 又搜不出来呢?
- 因为 idempotent 这个特性使用的人很少
- 同时开启 idempotent 又使用批量发送接口的人就更少了
- 同时开启了 idempotent 又使用批量发送,还用 aws 同时又遇到这种 leader election 特别慢的人少之又少
所以这个坑只有我们踩到了,没有办法。
