The Tail at Scale,是 Google 2013 年发表的一篇论文,大规模在线服务的长尾延迟问题。
要知道怎么解决长尾问题,先要理解长尾延迟是个什么问题,在开发在线服务的时候,我们都知道要关注服务的 p99/p999 延迟,要让大部分用户都能够在预期的时间范围内获得响应。
下面是一个不同响应时间的请求数分布图:
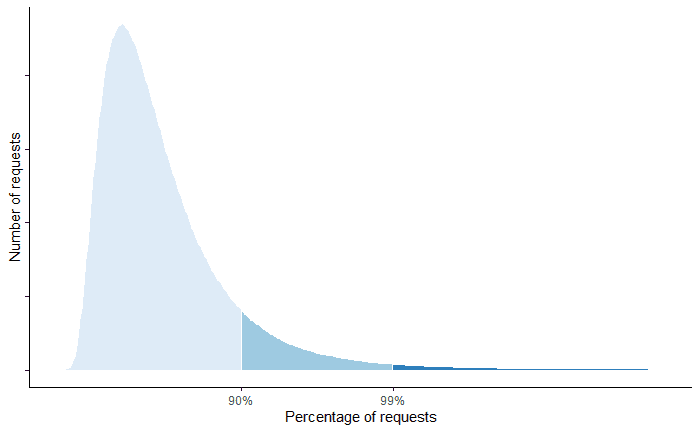
大部分系统也都遵循这种分布规律,现在互联网的系统规模比较大,一个服务依赖几十上百个服务的情况都是有可能的。单一模块的长尾延迟会在有大量依赖的情况下,在服务粒度被放大,《The Tail at Scale》论文里给出了这样的例子。
考虑一个系统,大部分服务调用在 10ms 内响应,但 99 分位数的延迟为 1 秒。如果一个用户请求只在一个这样的服务上处理,那么 100 个用户请求中只有一个会很慢(一秒钟)。
这里的图表概述了在这种假设的情况下,服务级别的延迟是如何被非常小概率的大延迟值影响的。
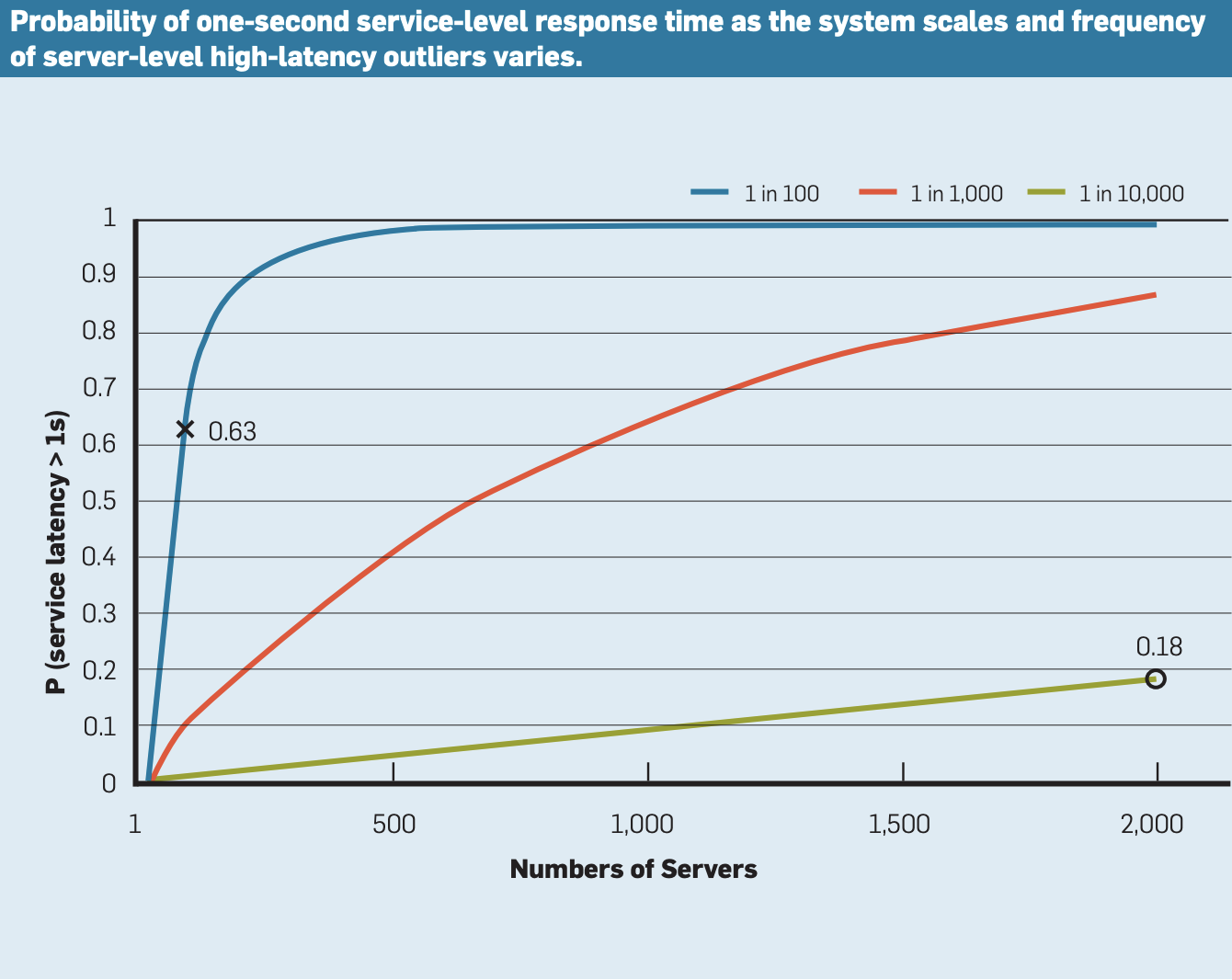
如果一个用户请求必须从100个这样的服务并行收集响应,那么 63% 的用户请求将需要超过一秒钟(图中标记为 "x")。
即使对于只有万分之一概率在单台服务器上遇到超过一秒的响应延迟的服务,如果服务的规模到达 2000 实例的话,也会观察到几乎五分之一的用户请求需要超过一秒(图中标记为 "o")。
Xargin 注:
- 因为请求是并行的,所以只受最慢的那个影响,100 个请求都落在 99 分位内延迟才会小于 1s,所以延迟小于 1s 的概率是 pow(0.99, 100) = 0.3660323412732292,也就是说一定有 63% 的概率会超过 1s。
- 第二个,我们落在 99 分位的概率是 pow(0.9999, 2000) = 0.8187225652655495,也就是将近 20% 的用户响应会超过 1s。

上面的表格列出了一个真实的谷歌服务的测量结果,该服务在逻辑上与前文简化过的场景相似;根服务通过中间服务将一个请求分发到非常多的叶子服务。表展示了大量扇出(fan-out)调用时,对延迟分布的影响。
在根服务器上测量的单个随机请求完成的 99 分位延迟是 10ms。然而,所有请求完成的 99 分位数延迟是 140ms,95% 的请求 99 分位数延迟是 70ms,这意味着等待最慢的 5% 的慢请求要对总的 99 百分位数延迟的一半负责。对这些慢请求场景进行优化,会对服务的整体延迟产生巨大影响。
为什么会有长尾延迟?
单个服务组件的长尾高延迟可能由于许多原因产生,包括:
共享资源(Shared resources,Xargin: 混部现在越来越多了)。机器可能被争夺共享资源(如 CPU 核心、处理器缓存、内存带宽和网络带宽)的不同应用所共享,而在同一应用中,不同的请求可能争夺资源。
守护程序(Daemons)。后台守护程序可能平均只使用有限的资源,但在运行时可能会产生几毫秒的峰值抖动。
全局资源共享(Global resource sharing)。在不同机器上运行的应用程序可能会争抢全局资源(如网络交换机和共享文件系统)。
维护活动(Maintenance activities)。后台活动(如分布式文件系统中的数据重建,BigTable等存储系统中的定期日志压缩,以及垃圾收集语言中的定期垃圾收集)会导致周期性的延迟高峰。
排队(Queueing)。中间服务器和网络交换机中的多层队列放大了这种可能性。
同时也是因为当前硬件的趋势:
功率限制(Power limits.)。现代 CPU 被设计成可以暂时运行在其平均功率之上(英特尔睿频加速技术),如果这种活动持续很长时间,之后又会通过节流(throttling)限制发热;
垃圾收集(Garbage collection)。固态存储设备提供了非常快的随机读取访问,但是需要定期对大量的数据块进行垃圾收集,即使是适度的写入活动,也会使读取延迟增加 100 倍;
能源管理(Energy management)。许多类型的设备的省电模式可以节省相当多的能量,但在从非活动模式转为活动模式时,会增加额外的延迟。
解决方案
模块内尽量降低长尾延迟
服务分级 && 优先级队列(Differentiating service classes and
higher-level queuing)。差异化服务类别可以用来优先调度用户正在等待的请求,而不是非交互式请求。保持低级队列较短,以便更高级别的策略更快生效。
减少队头阻塞(Reducing head-of-line blocking)。将需要长时间运行的请求打散成一连串小请求,使其可以与其它短时间任务交错执行;例如,谷歌的网络搜索系统使用这种时间分割,以防止大请求影响到大量其它计算成本较低的大量查询延迟。(队头阻塞还有协议和连接层面的问题,需要通过使用更新的协议来解决,比如 h1 -> h2 -> h3 的升级思路)
管理后台活动和同步中断(Managing background activities and
synchronized disruption)。后台任务可能产生巨大的 CPU、磁盘或网络负载;例子是面向日志的存储系统的日志压缩和垃圾收集语言的垃圾收集器活动。可以结合限流功能,把重量级操作分解成成本较低的操作,并在整体负载较低的时候触发这些操作(比如半夜),以减少后台活动对交互式请求延迟的影响。
请求期间内的一些自适应手段
对冲请求(Hedged requests)。 抑制延迟变化的一个简单方法是向多个副本发出相同的请求(Go 并发模式中的 or channel),并使用首先响应的结果。一旦收到第一个结果,客户端就会取消剩余的未处理请求。不过直接这么实现会造成额外的多倍负载。所以需要考虑优化。
一个方法是推迟发送第二个请求,直到第一个请求到达 95 分位数还没有返回。这种方法将额外的负载限制在 5% 左右,同时大大缩短了长尾时间。
捆绑式请求(Tied requests)。不像对冲一样等待一段时间发送,而是同时发给多个副本,但告诉副本还有其它的服务也在执行这个请求,副本任务处理完之后,会主动请求其它副本取消其正在处理的同一个请求。需要额外的网络同步。
跨请求的自适应手段
微分区(Micro-partition)。把服务器区分成很多小分区,比如一台大服务器分成 20 个 partition,这样无论是流量调整或者故障恢复都可以快非常多。以细粒度来调整负载便可以尽量降低负载不均导致的延迟影响。
选择性的复制(Selective replication)。为你检测到的或预测到的会很热的分区增加复制因子。然后,负载均衡器可以帮助分散负载。 谷歌的主要网络搜索系统采用了这种方法,在多个微分区中对流行和重要的文件进行额外的复制。(就是热点分区多准备些实例啦,感觉应该需要按具体业务去做一些预测)
将慢速机器置于考察期(Put slow machines on probation)。当检测到一台慢速机器时,暂时将其排除在操作之外(circuit breaker)。由于缓慢往往是暂时的,监测何时使受影响的系统重新上线。继续向这些被排除的服务器发出影子请求,收集它们的延迟统计数据,以便在问题缓解时将它们重新纳入服务中。(这里就是简单的熔断的实现)
一些其它的权衡
考虑“足够好”的响应(Consider 'good enough' responses)。一旦所有的服务器中有足够的一部分做出了响应,用户可能会得到最好的服务,即得到轻微的不完整的结果,以换取更好的端到端延迟。(这里应该是大家常说的降级,如果不完整的结果对于用户来说已经足够有用,那不重要的不展示也可以)
使用金丝雀请求(canary requests)。在具有非常高扇出的系统中可能发生的另一个问题是,一个特定的请求触发了未经测试的代码路径,导致崩溃或同时在成千上万的服务器上出现极长的延迟。为了防止这种相关的崩溃情况,谷歌的一些 IR 系统采用了一种叫做“金丝雀请求”的技术;根服务器并不是一开始就把一个请求发送给成千上万的叶子服务器,而是先把它发送给一个或两个叶子服务器。其余的服务器只有在根服务器在合理的时间内从金丝雀那里得到成功的响应时才会被查询。
