同事给了一个挺有意思的程序:
package main
import (
"fmt"
"os"
"runtime/trace"
"sync"
"time"
)
var mlock sync.RWMutex
var wg sync.WaitGroup
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
wg.Add(100)
for i := 0; i < 100; i++ {
go gets()
}
wg.Wait()
}
func gets() {
for i := 0; i < 100000; i++ {
get(i)
}
wg.Done()
}
func get(i int) {
beginTime := time.Now()
mlock.RLock()
tmp1 := time.Since(beginTime).Nanoseconds() / 1000000
if tmp1 > 100 { // 超过100ms就打印出来
fmt.Println("fuck here")
}
mlock.RUnlock()
}
并表示这里全是 RLock,按理说超过 100ms 似乎不太合理。
RLock 本身是一个很轻量的操作(atomic.AddInt32),不太可能会出现超出加个 RLock 超过 100ms 情况出现,除非和写锁频繁冲突。
在命令行执行 go run back2.go 2> trace,发现还是可能出现 **** here。
多运行几次,在控制台出现关键词时(记住这里出现的次数),进入 go tool trace ./trace。
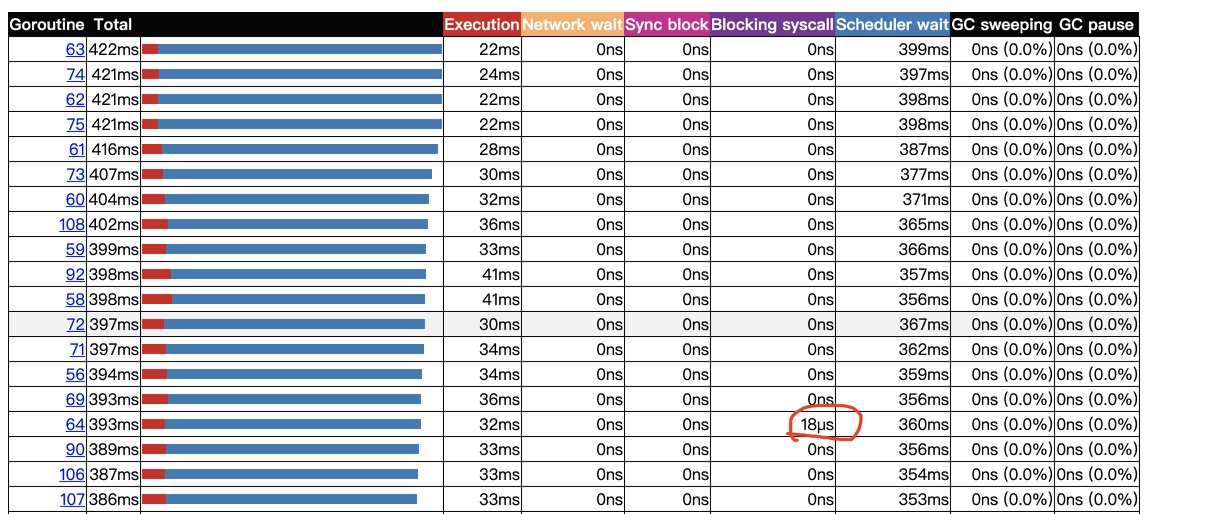
会看到有 goroutine 有在 blocking syscall 上被阻塞过:
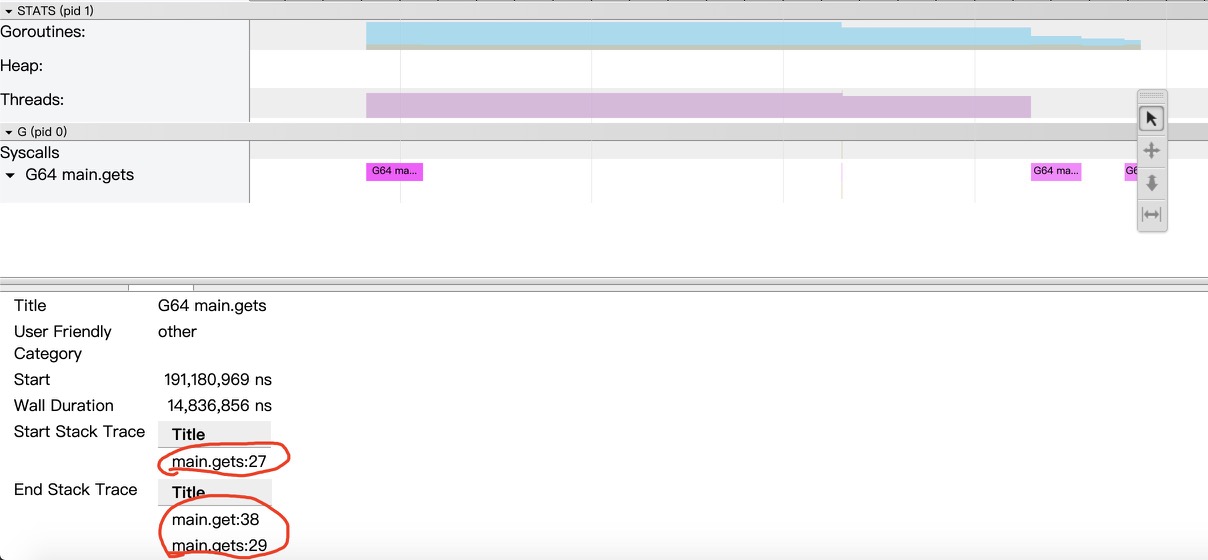
相应的 goroutine 是在 time.Since 调用这里被调度调出了,被调出的 goroutine 实际上仍然持有读锁。读锁之间是相容的,所以没有看到其它的 g 在 trace 上被同步手段所阻塞,因为其可以正常的 atomic 修改 reader 计数,从整体的 trace 图上也可以验证:
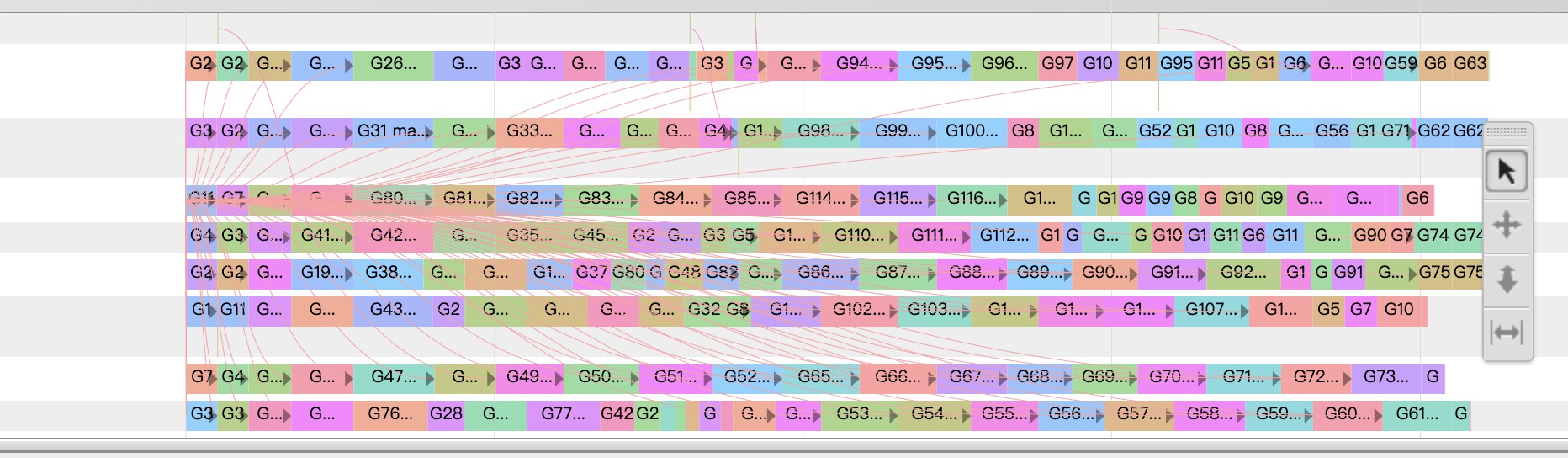
goroutine 的运行还是比较密集的。
倘若这里有写锁,那可能就杯具了。
同步+密集循环+调度,导致了这里的延时不可控。
此外,在 trace 的统计表格中,出现 blocking syscall > 0 的 goroutine 数和命令行中出现关键词的行数也是对得上的。因此可以简单地验证我们的结论,即这些 goroutine 并不是获取锁慢,是因为调获取时间的 syscall 被 runtime 调出了。。。被调出的 g 什么时候才能程序获得执行权只能随缘了。
结论:写代码的话,Lock 内尽量不要有 syscall(哪怕是 time.Now,time.Since 这种计时行为),RLock 也一样(虽然有时候确实避免不了)。
