依赖反转即 OOP 中的 SOLID 原则中的 D(Dependency Inversion Principle),最早么,是 Uncle Bob 提出的:
The dependency inversion principle was postulated by Robert C. Martin and described in several publications including the paper Object Oriented Design Quality Metrics: an analysis of dependencies, an article appearing in the C++ Report in May 1996 entitled The Dependency Inversion Principle, and the books Agile Software Development, Principles, Patterns, and Practices, and Agile Principles, Patterns, and Practices in C#.
在大多数业务系统中,我们希望能将业务领域层放在系统的最上层,类似下面这样:
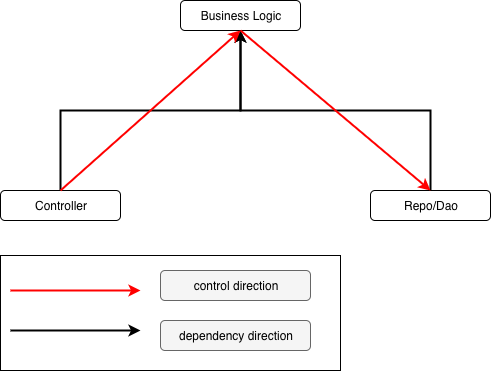
控制流为:controller -> logic -> repo,依赖方向为:controller -> logic,repo -> logic。
这个看起来很简单的原则,日常开发中能帮我们解决很多问题。就像我之前写的:
- 公司的老存储系统年久失修,现在已经没有人维护了,新的系统上线也没有考虑平滑迁移,但最后通牒已下,要求N天之内迁移完毕。
- 平台部门的老用户系统年久失修,现在已经没有人维护了,真是悲伤的故事。新系统上线没有考虑兼容老接口,但最后通牒已下,要求N个月之内迁移完毕。
- 公司的老消息队列人走茶凉,年久失修,新来的技术精英们没有考虑向前兼容,但最后通牒已下,要求半年之内迁移完毕。
我们总是会配合下游做一些迁移工作,迁移工作本身和业务逻辑没什么关系,因此不希望这些变动侵入到业务代码层。而希望只在 repo 层就能解决掉。
肯定有人会觉得,我即使不用 interface,也可能保证很好的项目分层,保证 repo/dao 的逻辑不侵入到 logic。这理论上虽可行,但开发过程中团队的代码类似这种什么代码该放什么位置的问题,其实没有办法进行很好的约束,现实还是很骨感。
interface 语法是程序语言+编译器提供给我们的一种编程契约,有效使用可以杜绝一部分人为造出垃圾代码的可能性。毕竟大多数程序员是懒惰而随意的。
除了可以反转依赖方向,我们引入 interface 后还可以带来测试上的好处,因为可以以 mock 出的测试对象(test double)来替换掉真实的实现来模拟各种情况以测试所谓的核心逻辑层是否能在各种异常情况下正常工作。这里就不展开了。
最近两年看了一些方法论相关的书,发现其实软件行业的大佬们并不是很喜欢直接使用前人的理论基础,而更喜欢自行发明自己的方法论。
就拿这里的依赖反转来说,还有很多衍生概念,比如在 《Building Evolutionary Architecture》一书中所说的,micro kernel 架构。
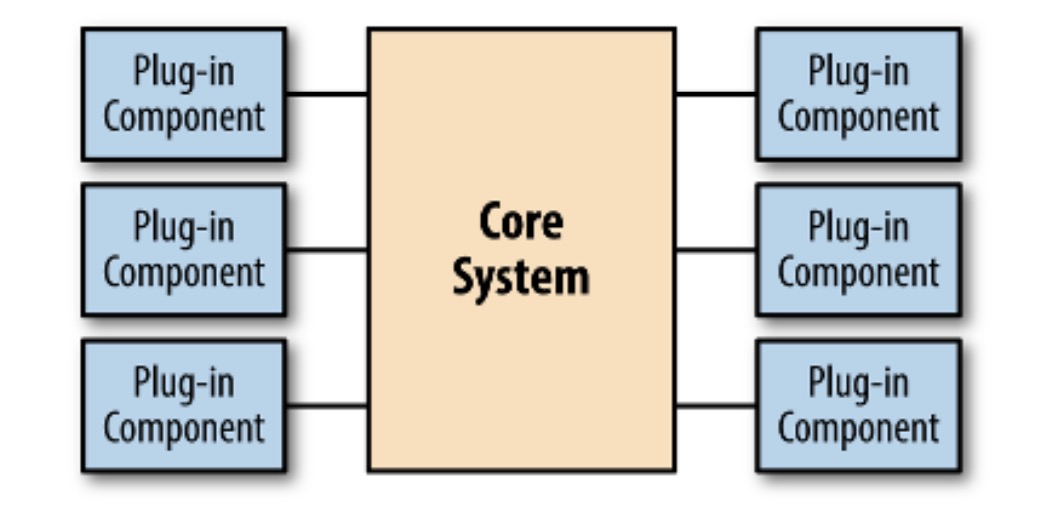
这位 thoughtworks 的作者虽然以 IDE 为例作了解释,但本质上,这和依赖反转没什么两样,由 IDE 提供统一的协议,插件作者实现便可以集成到 IDE 中。
再比如 Uncle Bob 在 《Clean Architecture》书所说的 “Clean Architecture”:
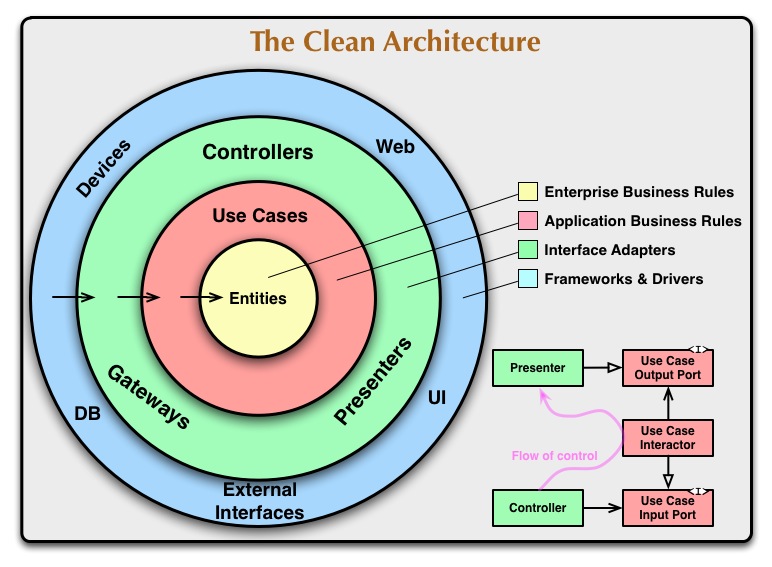
把企业的商业规则(真能造词)放在中心,其它层如 Controller、DB、UI 全部环绕在周围,本质上还是要通过 interface 来完成和控制流相反的依赖工作。
不要忘了还有更能造名词的 DDD 社区,六边形架构:
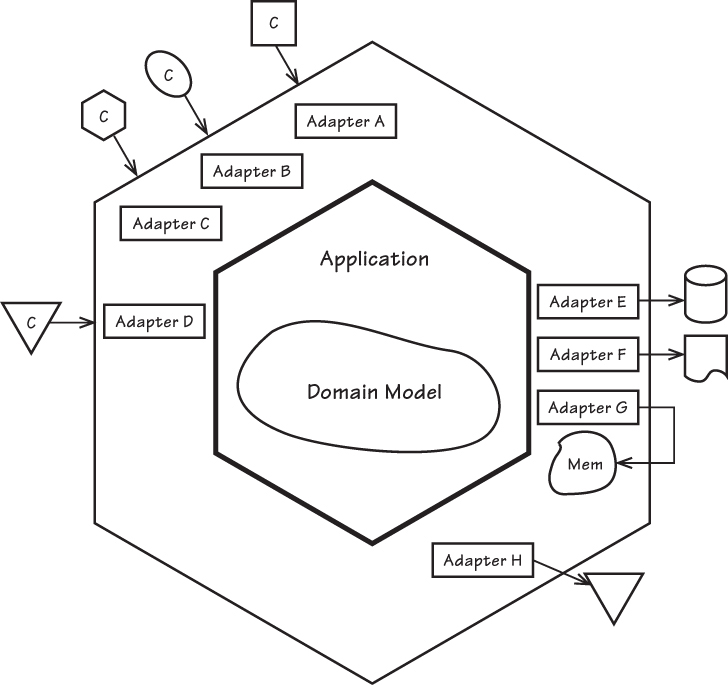
中心是应用程序和领域模型,周围是 input/output adapters,瞧瞧是不是很 Deja Vu。
当然了,国内很多人吵吵的插件化架构。也是一样的东西。
大佬们疯狂造概念,不交流。受苦的都是我们这些后来的程序员。
而这些概念本质上又是同样的东西,就看你是谁的信徒了。
最后留一个问题,在 web 项目中,我们对持久化对象定义的 interface,应该放在 logic 层,还是 repo 层?
