本人现在暂时是无业状态,所以本文不代表任何雇主观点。
到了 2021 这个时间点,大多数公司都决定拥抱云原生,但不少程序员对云原生的理解局限于“原生基于 k8s 的应用”。公司只要上云(k8s)了,就是拥抱云原生了。稍微理解多一点的人觉得除了 k8s,我们只要上了 service mesh,就是拥抱云原生了。
cncf 给云原生的定义其实非常地庞杂:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
上面的描述是从 cncf 的 toc 中摘出来的,应该还是比较权威的。
第一条把后端开发涉及的大部分基础设施技术都囊括进来了。涉及到 docker,service mesh,microservice,k8s 和 yaml 式的声明 API。
第二条和我们已经听到耳朵起茧的敏捷稍微有点关系,在互联网公司工作,即使我们不知道怎么实现,高内聚低耦合自动化平台化这样的口号还是会喊两句的,除了系统设计层面,这条原则还要求我们要有能够支持自动化交付的平台和工具,现在开源的 CI/CD 产品非常多,一家公司基于开源产品(jenkins, argo 等)来定制自己的交付流水线并不难,没什么可说的。
第三条说的是厂商中立,也就是在 cncf 内部的这些基础设施软件不能像以前那样搞得用户各种 vendor-lock 了。有了这条原则,云厂商其实是很难再像以前一样通过特殊的 API 来绑架用户了。
三条综合起来看,我们日常开发的技术和工作流程全都在里面,从开发到交付全生命周期。对于不了解云原生的外行人来说简直是究级迷惑,这帮人到底是想干啥?
在本文中,我们只关注一条线,就是后端业务模块本身的架构变化。
互联网应用从单体切到微服务,解决了之前大家挤在一个仓库里迭代和上线,导致交付瓶颈的问题。服务拆分之后给基础设施带来了很多挑战,所以之前几乎每家公司都得自己去造服务框架,监控系统,链路追踪,日志收集,日志检索这些和业务没什么关系的系统。
在这个过程中也催生了大量的基础设施岗位,因为这些需求是每家公司的共性需求,早期大家都是刚刚切换到微服务架构,并不是每个领域都有好用的开源产品。所以只能自己动手了。
微服务的布道师们声称微服务拆分之后,大家都是基于 API 或 domain event 的松耦合,我们可以按照领域特性或团队长处,随意切换我们线上服务的语言(因为按照微服务的逻辑,每个服务的代码量都不大)。这导致了很多信以为真的公司内部使用了多种语言来编写他们的线上服务。比如某公司的五种语言八种框架,又比如某公司的 197 种 RPC 框架(强调一下,这个不是段子),都是这个时期内诞生的荒诞现实。
举个例子,比如我要在业务框架里支持一下在 SRE 书里学到的重试套路,那么作为一个框架组的开发人员,我需要用 Go 写一遍,用 Java 写一遍,用 javascript 写一遍,用 C++ 写一遍,用 PHP 写一遍,用 Rust 写一遍,写到猝死。
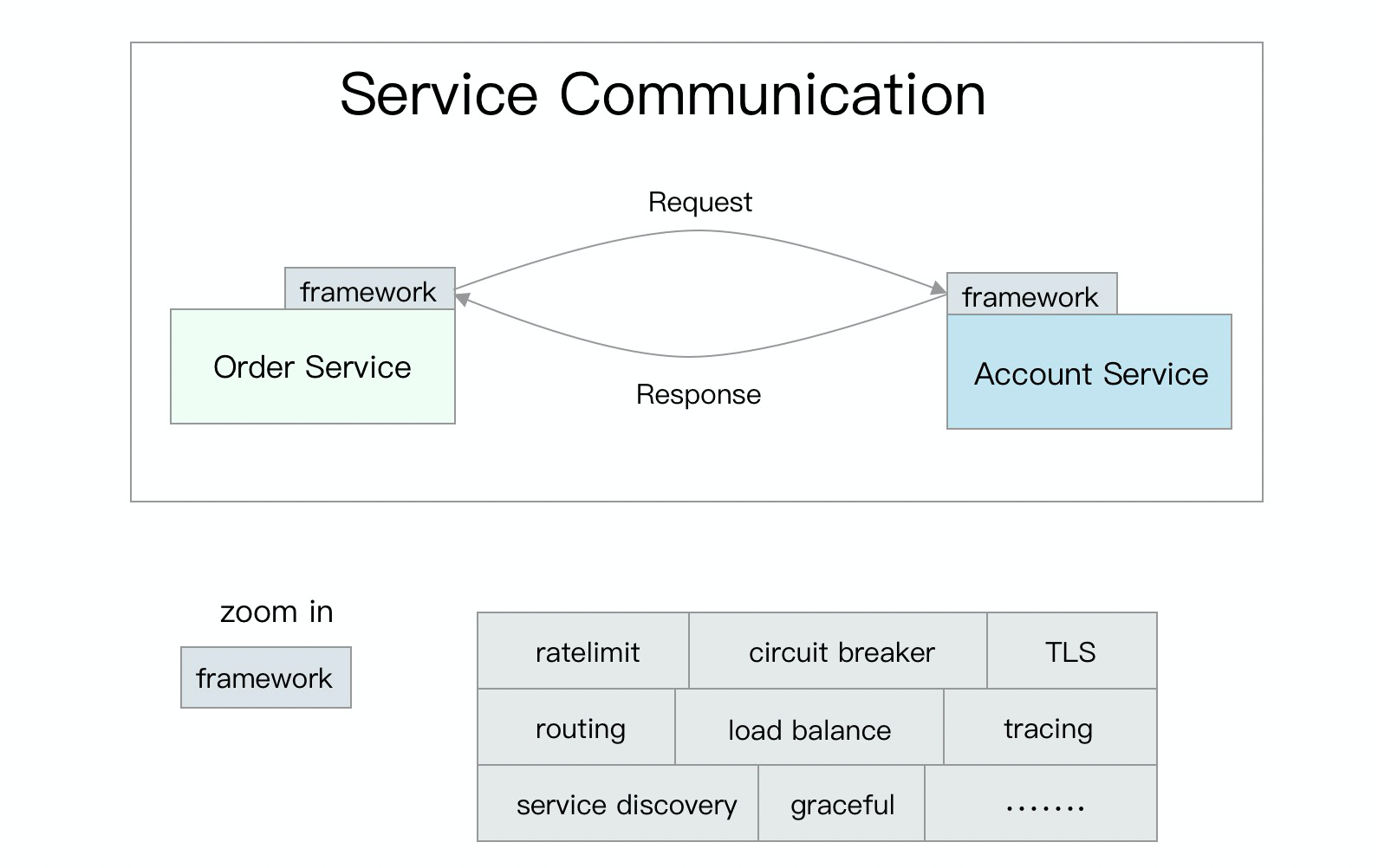
上面这张图里的框架功能,要为每一门公司内使用的语言实现一份。如果碰到了问题(比如 tls 的 0day 漏洞),要去每门语言里的 SDK 里修一遍。
框架的升级也是公司内的老大难问题,据某公司统计,因为某个基础库频繁出现漏洞,全年花在框架升级上的时间以千小时计。
service mesh 在一定程度上解决了这个问题,框架的功能从业务进程外移到 sidecar 进程中,比如 istio 和 envoy/mosn。
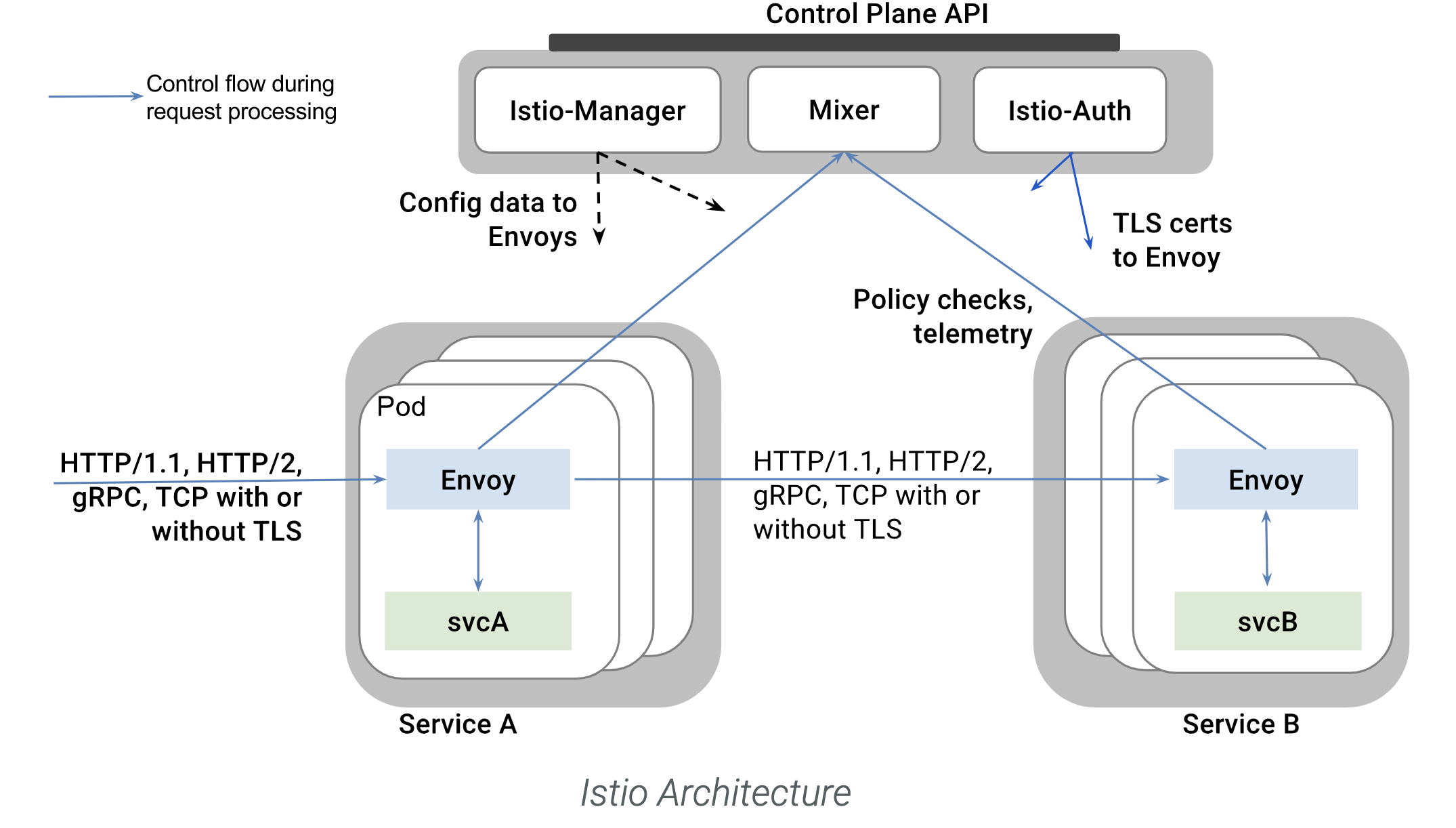
service mesh 一般分为控制面(control plane)和数据面(data plane),控制面(istio)负责管理与下发数据面需要的各种配置并保证配置信息的一致性;数据面(envoy、mosn)负责请求的转发以及稳定性有关的一切。
service mesh 追求对业务的零侵入/低侵入,并且被一部分公司所接受。在使用 service mesh 之后,公司内的限流、降级、熔断、重试、路由、加密都成为了语言无关的标准功能。
因为 service mesh 的数据面是以 sidecar 形式与业务在同一个 pod 中的不同 container 工作,所以 mesh 和业务可以分开升级。维护 mesh 和维护一个自己的项目差不多,走公司内的项目升级流程,几天就可以完成。
非业务功能的下沉,大幅度降低了框架层面的工作量,具体到框架组,公司内的框架组就没那么多事情可以干了。
当 sidecar 的形式被广泛接受后,我们也要留意到不追求对业务模块低侵入的新思潮,在 2020 年的 multi runtime microservice architecture 中,作者将微服务的需求提练为 State,Binding,Networking,Lifecycle 四个方面:
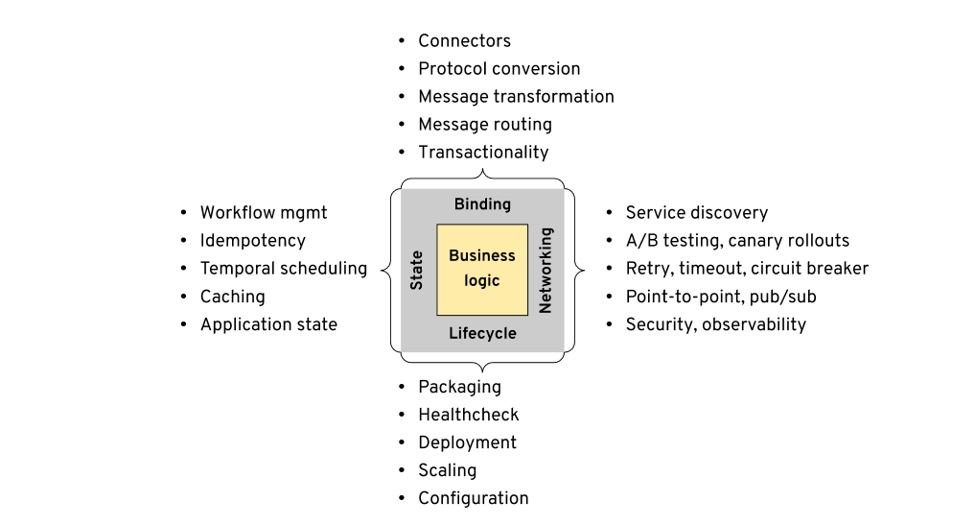
这其中的 Lifecycle 已经被 k8s 和 CI/CD 系统全权接管,Networking 在 service mesh 中已经得到了很好的实践。后来的 Dapr 的抽象更进一步,把 Binding 和 State 也包括在内了。
如果我们去阅读 Dapr 的文档,会发现如果使用 Dapr 的话,无论是我们存取 MySQL/Redis,还是订阅发布消息,抑或是与外部服务通信。都是以 HTTP 或者 gRPC 的方式来与其通信:
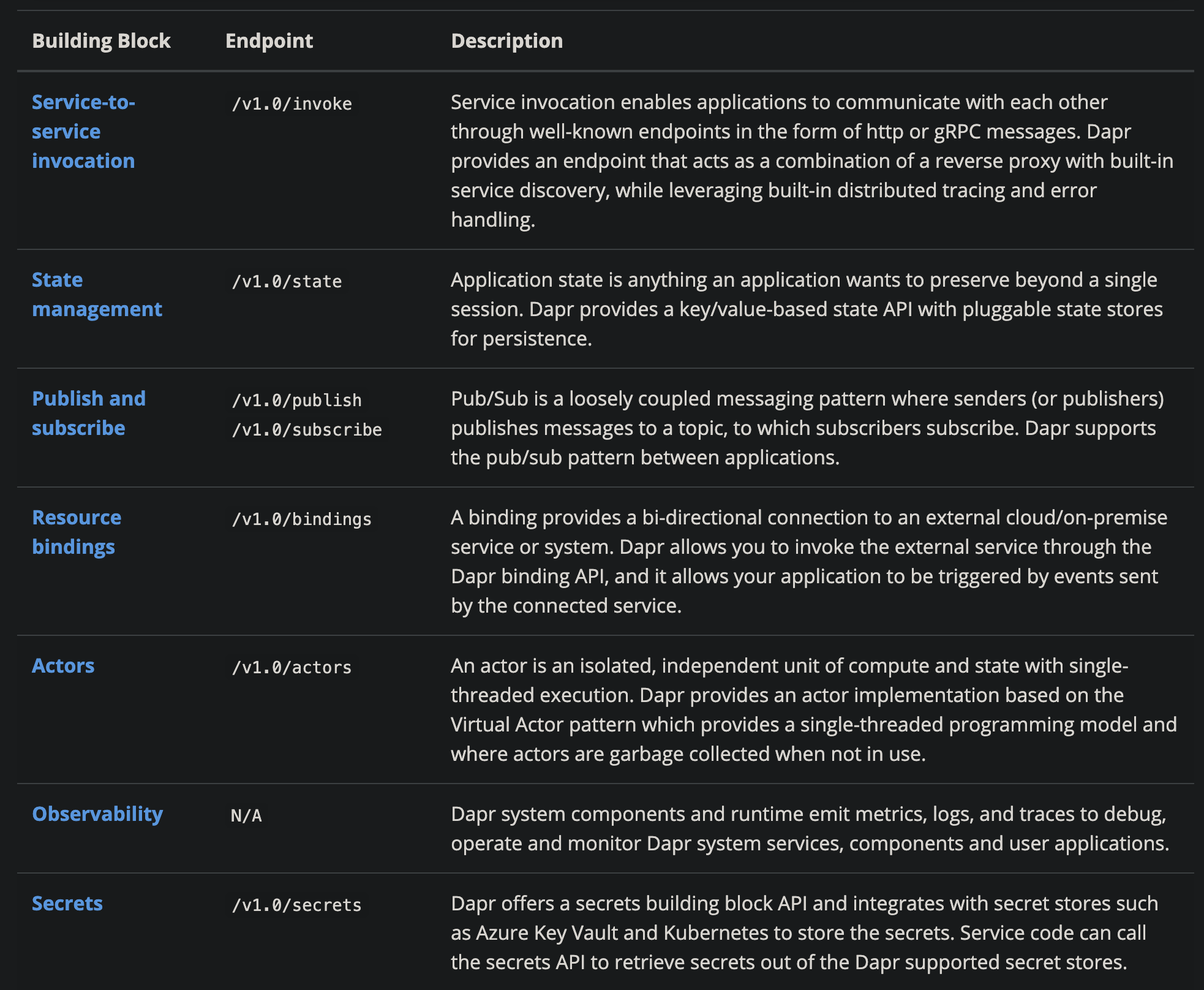
这种形式的抽象如果被接受,框架开发岗位大概率就直接消失掉了。大公司里需要各种黑科技才能实现的流量回放功能,在 Dapr 中也只是加几个 if else 的事情。
如果你看到了这里,我相信你已经差不多看明白了。云原生的本质其实是基础设施与业务的解耦,以及基础设施自身的标准化。
如果我们想要学习稳定性的知识,现在既不需要去加入一家大公司,也不需要去读 Google 的 SRE,很多知识已经在 service mesh 这样的标准化模块中实现了,我们只要去简单读读代码就可以搞明白。
作为大公司的工程师,我们可能在一段时间内以自己积累了完善的稳定性解决方案而自豪,但在云原生被普遍接受后,以往的大部分高可用、高并发、高扩展的知识可能会很快地贬值。仔细地想一想,有人会因为自己能背出乐高的说明书目录而感到自豪么?
早先的 k8s 的诞生一定程度上抹平了二线公司与一线公司的基础设施差距,能够以低成本的方式让每家公司都拥有故障自愈和自动扩缩容功能。对于互联网公司来说,这已经是生产力的一次巨大的进步了。但这次进步其实消灭了很多传统的运维岗位,一部分愿意学习和写代码的人后来转为 SRE,在公司内进行 k8s 和其它基础设施的二次开发工作。但整体岗位数量一定是减少的。
现如今服务架构的标准化会进一步削减各个公司的框架开发人员规模,当 cncf 内每个领域的头部软件都解决了大规模部署的性能问题之后,新进场的公司、软件和相关开发人员大概就很难有很好的机会了。

