最近翻看了一些 Google 的老文章/论文,发现 Google 有不少系统的设计文上都写着 planet scale,行星级,口气那是真的大。仔细想想,FAANG 这样能把生意做到全球的互联网公司,除了这五家,也没几家其它的了,人家确实有吹行星级的资本。着实羡慕。
Google 的员工出来创业,公司名也是 TailScale(似乎是做 vpn 的),PlanetScale(这家似乎是拿着 vitess 出来创业的) 这样,说明 ex-googler 也是比较喜欢这家公司的文化的。
本文是 Google 2015 年在 acm queue 上发表的 《Reliable Cron across the Planet》的总结,该文后来被收录在那本著名的 《Site Reliability Engineering》一书的 第 24 章,换了个收敛点的名字:Distributed periodic Scheduling。
为什么单机的 cron 不可以
可能很多同学不太理解,既然 linux 的 cron 这么好用,为什么还要兴师动众地做一套分布式的 cron 系统?
公司里的定时任务需求还是比较常见的:
- 大数据平台,我们需要每小时执行一次定时任务,把在线系统产生的日志导入到 hive 里去(按小时分 partition)。
- 运营场景,某些活动是定时开始的,一些电商的购物节,如 618,双 11,活动是从 00:00:00 开始的,所以在 00:00:00 时刻需要把之前准备好的活动页面放出来给用户进行抢购,让人来这些操作是很反人类的。
- 有些平台的判罚规则出现偏差,用户投诉时,需要将之前的判罚记录抹掉,将用户的分数恢复,逻辑较简单,每五分钟扫描一次新增的合理投诉 MySQL 表,执行相应的补偿逻辑。
- 游戏平台有匹配需求,我们要把那些挂机用户定时从服务器上踢下线,需要每 15 分钟扫描一次全量在线用户状态。
为了满足这些需求,最直观的想法是我们在 linux crontab 中管理这些定时任务,把这些 cron 任务配置在一台单独的服务器上:
- (*) myserver-crontab
- myserver-service-1
- myserver-service-2
- myserver-service-3
业务的发展会使这样的定时任务需求越来越多,当这台 crontab 机器挂掉之后,所有定时任务全部失效。如果恰巧这些 cron 任务没有备份,那就又要开始经典的会上甩锅环节了。
单台机器的故障概率比较高,所以至少要有一个独立的 cron 服务,保证当单台机器故障时,定时任务不会丢,并且依然能够得到执行。
这样的服务怎么设计
文中没有提到 cron 任务本身存储在什么系统里,不过这个我们简单推测一下就可以,比较复杂的业务,可能也就几千~上万的 cron 任务,并且变更不会特别频繁,配置文件、配置系统、外部存储(在 Google 的话,就是 spanner 了),应该都是可以的。
为了避免单机故障,cron 服务使用 paxos 协议组成一个 paxos 集群。由 leader 来进行 cron 任务的状态更新与执行操作。
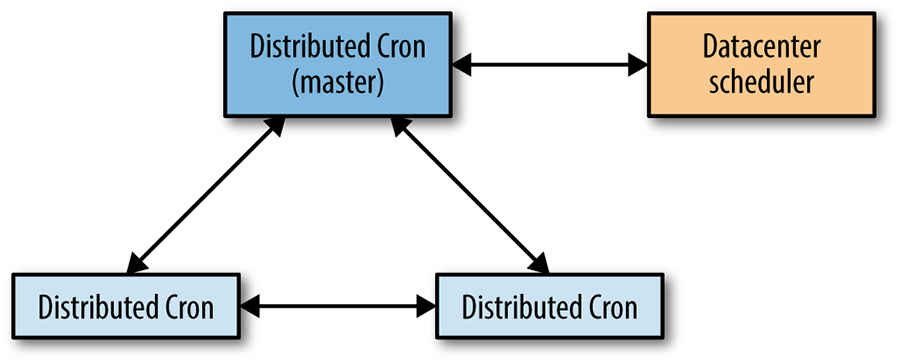
任务执行要与 cron 本身解耦,所以一个 cron 任务的执行过程,一般就是向 datacenter scheduler 发一个 RPC 请求。每一个任务需要记两条数据,一条是 begin,一条是 end。这两条数据需要在 paxos 集群中进行同步,因为它们是 cron 任务的关键状态信息。
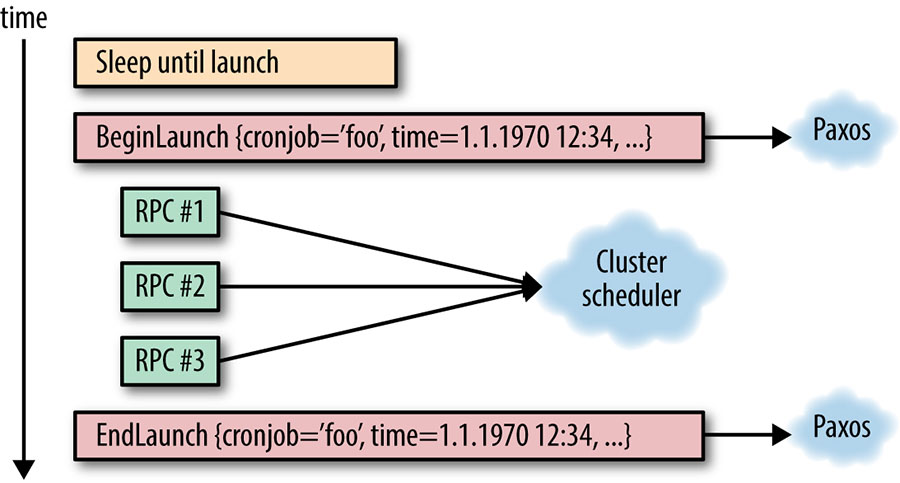
一旦 paxos 集群中的 leader 失去了 leader 身份,那么它就不应该再与 datacenter scheduler 进行任何交互了。
由于一次 cron 任务执行过程中会多次与 scheduler 通信,可能会发生部分失败的情况(例如 RPC #1,RPC #2 都完成了,但在 RPC #3 开始前,paxos 发生了 leader 切换。这种情况下,有两种解法:
- 新选出的 leader 需要知道之前的 RPC 是否都完成了,这就需要能够从外部查询这些任务的状态。该过程与公司内的具体基础设施实现是绑定的。
- 将外部 RPC 都实现成幂等请求,这样新的 leader 接手后只要无脑再发一遍 RPC #1,RPC #2,RPC #3 即可。
外部系统的幂等需要用户的任务执行逻辑进行配合,也不是特别好做。
其它问题
因为 paxos 这类一致性算法都是基于日志来实现的,所以本身存储的日志会不断膨胀,这个过程中需要考虑日志的压缩,比如可以用 snapshot 来替代之前的日志。这种思想和 event sourcing 中的 snapshot 差不多。
日志和快照在本地存储中都会有一份,同时快照会被备份在远端的分布式存储中。如果系统整个发生崩溃时,还可以用快照将服务恢复出来。
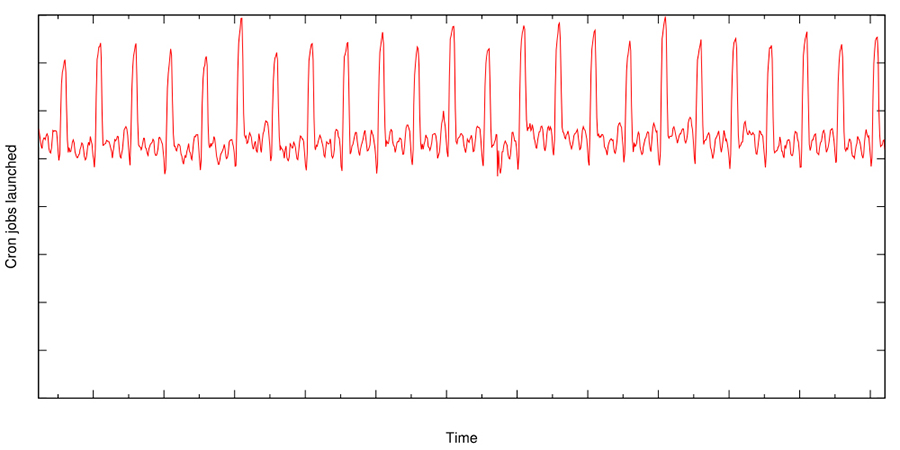
大型的 cron 系统本身还有一些负载不均衡问题,Google 在设计过程中给 cron 做了个简单扩展,具体的时间配置位置可以直接写一个问号,表示任意时间都可以,这样 cron 系统就可以根据负载来动态地选择任务的具体执行时间,将高峰负载打散。尽管做了这些之后,理论上 cron 相关的负载还是会有尖峰,这也是由定时任务的性质决定的:
总结
Google 的 cron 设计还是稍微有点复杂的,如果我们稍微牺牲一些依赖上的要求,可以做出相对简单的一个系统来。
当然,现在每家都有 k8s,或许对于大多数公司来说,直接使用 k8s 的 cronjob 就可以了。
