在 这篇总结 的结尾,提到了 GraphQL 的问题。
之前在某公司落地查询 API 方案时,我们没有选择 GraphQL,是因为:
- GraphQL 对于数据用户来说有一定的学习成本
- GraphQL 的稳定性很难做,难以限流
学习成本倒也不是特别大的问题,程序员们本能上还是喜欢接触新东西的,这会让他们有一种虚假的获得感。
关键是这个限流问题,是真的很难做,开放 GraphQL 的 API,就像你在 MySQL 上直接开了一个 SQL 接口一样,用 SQL 可以一次只查一条数据,也可以一次查一亿条数据。
所有查询都只用主键做条件查一条数据,那单 MySQL 实例可以搞出百万 QPS。如果一个查询要查一亿条数据,那这条查询就把 MySQL 实例的 CPU/内存打爆了[doge]。
GraphQL 里类似的情况是这样:
query maliciousQuery {
album(id: ”some-id”) {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
#... Repeat this 10000 times...
}
}
}
}
}
}
}
}这个例子来自这里。嵌套查询会导致查询的成本无法预测。
不同的查询复杂度完全不一样,只是按传统的 REST 风格 API,按次数来限制,就不太合适了。
Shopify 今年 6 月份发了一篇《Rate Limiting GraphQL APIs by Calculating Query Complexity》的文章,讲了他们在使用 GraphQL 时做的限流策略。
下面的内容主要是这篇文章的翻译。
开头说了说 REST 风格 API 的限制,这个应该大多数人都知道了。。主要就是下面这两种限制:
- REST 认为户端每个请求都是一样的消耗,即使 API 响应里有很多数据他们不需要
- POST,PUT,PATCH 和 DELETE 这些请求相比 GET 请求会产生更多 side effects,会消耗更多服务端资源,但在 REST 里这些都是一视同仁的。
在大一统的 REST 风格 API 下,所有类型的客户端都只能接受 response 里那些它们不需要的字段。并且更新、删除操作对服务产生更多负载,但它们在基于请求响应的模型里是按一样的资源消耗量进行计算的。
GraphQL 主要解决了动态字段的问题,但 GraphQL 不同的请求,成本也是不一样的。所以 Shopify 的方案在执行 GraphQL 请求前会先对这个 GraphQL 请求做静态分析,来计算该请求的成本。这篇文章主要就是介绍它们这套计算方法。
Object :一点
object 是查询的基本单位,一般代码一个单次的 server 端操作,可以是一次数据库查询,也可以一次内部服务的访问。
Scalars and Enums:零点
标量和枚举是 Object 本身的一部分,在 Object 里我们已经算过消耗了,这里的 scalar 和 enum 其实就是 object 上的某个字段。一个 object 上多返回几个字段消耗是比较少的。
query {
shop { # Object - 1 point
id # ID - 0 points
name # String - 0 points
timezoneOffsetMinutes # Int - 0 points
customerAccounts # Enum - 0 points
}
}这个例子里的 shop 是一个 object,消耗 1 点。id,name,timezoneOffsetMinutes,customerAccounts 都是标量类型,消耗 0 点。着的查询消耗是 1。
Connections: 两点+返回的对象数量
GraphQL 的 Connection 表示的是一对多的关系。Shopify 用的是 Relay 兼容的连接,这意味着连接遵循常见的规范,比如和 edges,node,cursor 以及 pageInfo 一起混合使用。
edges 对象包含的字段是用来描述一对多的关系的:
- node:query 返回的 object 列表
- cursor:当前在列表中的游标位置
pageInfo 有 hasPreviousPage 和 hasNextPage 的 boolean 字段,用来在列表中进行导航。
connection 的消耗认为是两点+要返回的对象数量。在这个例子里,一个 connection 期望返回五个 object,所以消耗七点:
query {
orders(first: 5, query: "fulfillment_status:shipped") {
edges {
node {
id
name
displayFulfillmentStatus
}
}
}
}cursor 和 pageInfo 不需要计算成本,因为他们的成本在做返回对象计算的时候已经都计算过了。
下面这个例子和之前的一样也消耗七点:
query {
orders(first:5, query:"fulfillment_status:shipped") {
edges {
cursor
node {
id
name
displayFulfillmentStatus
}
}
pageInfo {
hasPreviousPage
hasNextPage
}
}
}Interfaces 和 Unions:一分
Interfaces 和 unions 和 object 类似,只不过是能返回不同类型的 object,所以算一点。
Mutations:十分
Mutations 指的是那些有 side effect 的请求,即该请求会影响数据库中的数据或索引,甚至可能触发 webhook 和 email 通知。这种请求要比一般的查询请求消耗更多资源,所以算 10 点。
在 GraphQL 的响应中获取 Query Cost 信息
你不需要自己计算 query 成本。Shopify 设计的 API 响应可以直接把 object 消耗的成本包含在响应内容中。可以在他们的 Shopify Admin API GraphiQL explorer 里跑查询来实时观察相应的查询成本。
query {
shop {
id
name
timezoneOffsetMinutes
customerAccounts
}
}计算出来的 cost 会在 extention object 里展示:
{
"data": {
"shop": {
"id": "gid://shopify/Shop/91615055400",
"name": "My Shop",
"timezoneOffsetMinutes": -420,
"customerAccounts": "DISABLED"
}
},
"extensions": {
"cost": {
"requestedQueryCost": 1,
"actualQueryCost": 1,
"throttleStatus": {
"maximumAvailable": 1000.0,
"currentlyAvailable": 999,
"restoreRate": 50.0
}
}
}
}返回 Query Cost 详情
上面举的例子是直接返回一个计算出的总值,还可以得到按字段细分的查询消耗,在请求中加一个 X-GraphQL-Cost-Include-Fields: true 的 header 就可以让 extention object 展示更详细的点数信息了:
{
"data": {
"shop": {
"id": "gid://shopify/Shop/91615055400",
"name": "My Shop",
"timezoneOffsetMinutes": -420,
"customerAccounts": "DISABLED"
}
},
"extensions": {
"cost": {
"requestedQueryCost": 1,
"actualQueryCost": 1,
"throttleStatus": {
"maximumAvailable": 1000.0,
"currentlyAvailable": 999,
"restoreRate": 50.0
},
"fields": [
{
"path": [
"shop",
"id"
],
"definedCost": 0,
"requestedTotalCost": 0,
"requestedChildrenCost": null
},
{
"path": [
"shop",
"name"
],
"definedCost": 0,
"requestedTotalCost": 0,
"requestedChildrenCost": null
},
{
"path": [
"shop",
"timezoneOffsetMinutes"
],
"definedCost": 0,
"requestedTotalCost": 0,
"requestedChildrenCost": null
},
{
"path": [
"shop",
"customerAccounts"
],
"definedCost": 0,
"requestedTotalCost": 0,
"requestedChildrenCost": null
},
{
"path": [
"shop"
],
"definedCost": 1,
"requestedTotalCost": 1,
"requestedChildrenCost": 0
}
]
}
}
}理解请求消耗和实际的查询消耗
可以注意到上面的返回结果里有不同类似的 cost 字段:
- 请求消耗是在执行查询前通过对 GraphQL 进行静态分析得到的值
- 实际的查询消耗是通过执行查询得到的值
有时实际的消耗也比静态分析得到的消耗要少一些。比如你的查询指定要查 connection 里的 100 个 object,但实际上只返回了 10 个。这种情况下,静态分析多扣除的分数会返还给 API client。
下面这个例子,我们查询前五个库存中的商品,但只有一个商品满足查询条件,所以尽管计算出的请求消耗点数是 7,client 并不会被扣掉 7 分。
query {
products(first: 5, query: "inventory_total:<5") {
edges {
node {
title
}
}
}
}还是按真实的查询成本来计算的:
{
"data": {
"products": {
"edges": [
{
"node": {
"title": "Low inventory product"
}
}
]
}
},
"extensions": {
"cost": {
"requestedQueryCost": 7,
"actualQueryCost": 3,
"throttleStatus": {
"maximumAvailable": 1000.0,
"currentlyAvailable": 997,
"restoreRate": 50.0
}
}
}
}
对本文中的 Query Cost 模型进行有效性检验
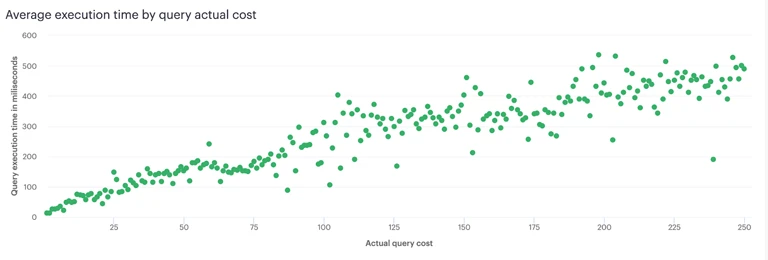
使用了查询复杂度计算规则之后,我们能够让查询的成本和服务端的负载基本线性匹配。这使得 Shopify 对网关层的基础设施能够有效地进行负载预测和横向扩展,并且也给用户提供了稳定的构建 app 的平台。我们还可以检测出那些资源消耗大户,专门对它们进行性能优化。
通过对 GraphQL 查询的复杂度计算进行限流,我们得到了比 REST 更可靠的 API client,同时相比 REST 又具备了更优的灵活性,这种 API 模式鼓励用户只请求它们需要的那些数据,使服务器的负载也更加可预期。
其它信息:
- Shopify API rate limits
- Shopify Admin API GraphiQL explorer
- How Shopify Manages API Versioning and Breaking Changes
- ShipIt! Presents: A Look at Shopify's API Health Report
